
aus dem Netzwerk Insider Juni 2024
Das Thema Object Storage begegnet mir im Projektgeschäft aktuell immer häufiger. Neu ist die Technologie dabei nicht. Besonders bekannt ist diese Art von Storage vor allem aus der Cloud, mit AWS S3 als vielleicht prominentester, aber auch sehr komplexer Object Storage.
Warum also erst jetzt ein Artikel? Object Storage kommt mittlerweile immer häufiger auch on Premises zum Einsatz, mit sehr unterschiedlichen Use Cases. Daher soll in diesem Artikel ein grundlegendes Verständnis für Object Storage als Technologie und einige Use Cases vermittelt werden, denn: Object Storage ist nicht gleich Object Storage.
Es werden zunächst die Grundlagen und Ähnlichkeiten mit anderen Technologien beschrieben. Danach sollen die verbreitetsten Arten von Object Storage dargestellt werden, nicht alle sind dabei überall verfügbar. Und da keine Technologie ein Selbstweck ist, werden für verschiedene Use Cases gezeigt, ob und warum Object Storage dafür (nicht) gut geeignet ist.
Grundlagen von Object Storage
Object Storage unterscheidet sich sowohl in der Architektur als auch bei der Nutzung stark von traditionellen Storage-Technologien wie Block-Storage, z. B. in der Form von iSCSI oder Fibre Channel oder Fileservern. Fangen wir mit dem Zugriff auf die Daten an. Eine schematische Darstellung findet sich in Abbildung 1.
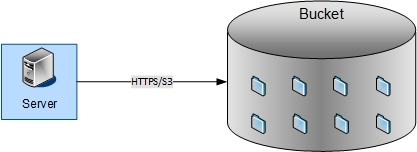
Abbildung 1: Zugriff auf einen S3-Bucket per HTTPS
Der vielleicht größte Unterschied zu klassischem Storage: Es gibt keine Ordner, wie wir alle sie seit Jahrzehnten kennen. Ein Object Storage ist in sog. Buckets – Eimer – aufgeteilt, in denen Daten abgelegt werden können. „Alles in einen Eimer schmeißen“ ist also bei Object Storage kein reines Sprichwort. Das mag nach einem Rückschritt in die altehrwürdigen Zeiten von Multics und OS/360 aussehen. Aber das Fehlen von Ordnern wird durch andere Mechanismen ersetzt.
Statt in Dateien mit einer begrenzten Zahl von Dateisystem-abhängigen Metadaten werden in Object Storage, wie der Name es schon andeutet, Daten in „Objekten“ abgespeichert. Die Identifikation innerhalb der oben genannten Buckets erfolgt anhand eines 128-bit-Identifiers, der sogenannten UUID, die typischerweise in hexadezimaler Form mit Bindestrichen dargestellt wird, z. B. 11223344-5566-7788-99aa-bbccddeeff00. Werden keine weiteren Funktionen genutzt, sollte man sich also eine Methode überlegen, wie man sich merkt, welche Daten zu welcher UUID gehören.
Aber genau hier kommen die weiteren Funktionen von Object Storage zum Einsatz: Vor allem die diversen Metadaten, die man an ein Objekt anhängen kann, sind dabei hilfreich. Diese können eine Vielzahl von Eigenschaften festlegen und auch bei der Suche helfen. Beispiele für mögliche Metadaten sind:
- Tags zur Sortierung und Organisierung
- Zugriffsrechte auf Nutzer- oder IP-Basis
- Ein Ablaufdatum, ab welchem Daten nicht mehr benötigt werden
- Ein Datum, ab dem die Daten verändert werden können – hierauf wird im Bereich der besonderen Funktionen noch genauer eingegangen
- Sprechende Namen
Durch diese in sich geschlossene Natur der Objekte ergibt sich auch eine große Herausforderung: Um einen Teil der Daten zu verändern, muss eine wesentlich größere Menge an Daten komplett neu hochgeladen und abgelegt werden. Das bedeutet entweder einen neuen Upload des gesamten Objekts oder zumindest eines Teils. Hierfür gibt es eine eigene Funktion, die jedoch eine Minimalgröße für den zu ändernden Teil hat sowie eine maximale Anzahl von Teilen für ein Objekt. Bei AWS S3 zum Beispiel ist die minimale Größe 5 MB und eine Aufteilung auf maximal 10.000 Teile möglich. Wird ein Objekt größer, bedeutet dies irgendwann unweigerlich größere Teile für das Objekt und längere Änderungszeiten. Für kleinere Objekte mag der Overhead sich in Grenzen halten. Bei größeren Objekten kann die Änderung eines einzelnen Bits aber zu enorm langen Schreibvorgängen führen. Zwar mag damit Object Storage für kleinere Datenmengen attraktiv wirken, jedoch wird der Overhead durch die Metadaten und die einzelnen Netzwerk-Verbindungen für jedes Objekt schnell signifikant. Und damit zeigt sich ein erster und vielleicht der wichtigste Use Case, den wir später genauer betrachten werden: Die Ablage von Daten, auf die fast nur lesend zugegriffen wird.
Der Zugriff auf die Daten erfolgt auch anders als im Bereich von klassischem Storage, wo entweder ein Protokoll wie NFS oder SMB für den Zugriff auf Dateisysteme oder Block-Storage-Protokolle gesprochen werden. Der Zugriff auf die Daten, ob lesend oder schreibend, erfolgt über HTTPS, also verhält sich, überspitzt dargestellt, der Storage wie eine Web-Anwendung oder eine REST-API.
Und hier kommt, auch für Nutzer die erste Komplikation ins Spiel: Zwar ist der Zugriff per HTTPS eigentlich standardisiert, es kann aber auf zwei Ebenen zu (teilweise großen) Unterschieden kommen:
- Zum einen ist S3 zwar für Object Storage der verbreitetste „Dialekt“, aber nicht der einzige.
- Zum anderen unterstützt auch nicht jeder S3-konforme Object Storage alle Funktionen und Befehle.
Auf diese Unterschiede wird weiter unten noch genauer eingegangen.
Die Grundlagen zu den Objekten und dem Zugriff darauf ist jetzt bekannt. Wie genau werden die Daten im Hintergrund abgelegt?
Die Verteilung von Daten
Schauen wir uns also als nächstes an, wie Daten verteilt werden und welche Redundanz-Mechanismen zum Einsatz kommen (können):
Ein Hinweis vorweg: Bei der eigentlichen Verteilung der Daten auf verschiedene Datenträger oder Systeme sind die Details natürlich nur für On-Permises-Lösungen zu betrachten. Was genau bei Cloud-Anbietern eingesetzt wird, ist für den Nutzer nicht ersichtlich.
Bei den verbreitetsten On-Premises-Lösungen findet die Verteilung der Daten auf zwei Ebenen statt:
- Zum einen auf Ebene der Datenträger der beteiligten Systeme
- Zum anderen die Verteilung der Daten auf verschiedene Systeme, falls mehr als ein System zum Einsatz kommt.
Damit ergeben sich im Großen und Ganzen drei Möglichkeiten, Object Storage im eigenen Rechenzentrum zu betreiben:
- Ein System mit einem einzelnen Datenträger zur Ablage der Objekte (Single Node Single Disk):
Die vielleicht einfachste Realisierung eines Object Storage. Diese Lösung ist eigentlich nur in Eigenarbeit mit Software-Lösungen denkbar. Kommerzielle Hersteller von Object-Storage-Appliances liefern zumeist größere Systeme, die unter die nächsten beiden Kategorien fallen. Trotzdem haben Single-Node-Single-Disk-Storages ihre Daseinsberechtigung: In Test- und Entwicklungsumgebungen ist ein einfacher Storage sinnvoll, da ein Datenverlust häufig verkraftbar ist und es sich auch nur um Testdaten handelt. Hier für einzelne Anwendungen komplette Object-Storage-Cluster aufzubauen, ist in vielen Fällen zu kostenintensiv. - Ein System mit mehreren Datenträgern (Single Node Multiple Disks):
Hier können wir das erste Mal von einem auch für Produktivsysteme geeigneten Object Storage reden, da der Ausfall von Datenträgern nicht zu Datenverlust führt. Viele andere Komponenten, wie Netzteile, Lüfter etc. sind typischerweise auch redundant ausgelegt. Für unternehmenskritische Anwendungen ist diese Lösung aber auch nicht optimal. Bei „klassischem“ Storage kommen nicht umsonst Multi-Controller-Lösungen oder sogar synchrone Spiegelung über mehrere Standorte zum Einsatz. - Mehrere Systeme jeweils mit mehreren Datenträgern (Multiple Nodes Multiple Disks):
Hier ergibt sich die optimale Redundanz: Egal ob einzelne Datenträger oder ganze Systeme ausfallen: Die Daten werden (entsprechende Konfiguration vorausgesetzt) so verteilt, dass sie immer noch verfügbar sind. Dies ist die für Produktivsysteme optimale Architektur. Ein weiterer Vorteil: Eine Erweiterung der Kapazität ist einfach durch Hinzufügen weiterer Node möglich.
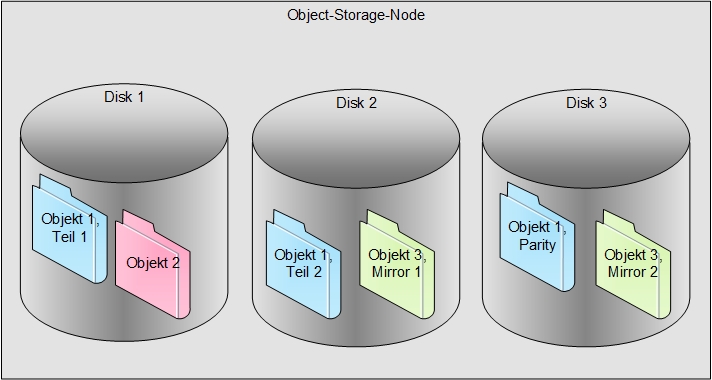
Abbildung 2: Aufteilung von Objekten innerhalb eines Nodes. Buckets und deren Objekte können unterschiedliche Redundanzen bieten. Hier: Einfache Parität (Objekt 1, blau), keine Redundanz (Objekt 2, rot) oder Spiegelung (Objekt 3, grün). Bei mehreren Nodes oder zusätzlichen Disks auch Mehrfach-Parity möglich.
Natürlich gäbe es theoretisch noch die Möglichkeit, mehrere Systeme mit jeweils einem Datenträger zu nutzen. Der Overhead ist jedoch in diesem Fall nicht vertretbar und wird daher nicht weiter betrachtet.
Auch eine Replikation über verschiedene Standorte ist möglich. Ob man dabei eine synchrone oder asynchrone Replikation nutzt, hängt von vielen Faktoren ab, die den Rahmen dieses Artikels sprengen.
Die Aufteilung innerhalb eines Nodes ist in Abbildung 2 dargestellt, die Kopplung mehrerer Systeme und Standorte in Abbildung 3.
Wie viel Redundanz – aka wie viel Spiegelung oder Parität – pro Objekt benötigt wird, lässt sich bei On-Premises-Lösungen ebenfalls konfigurieren, meistens auf Bucket-Ebene. Ebenso werden die Objekte je nach Lösung in unterschiedlich große Teile aufgeteilt, für die dann die geforderte Redundanz greift.
Sobald man mehrere Datenträger in einem System einsetzt, muss man auch noch weitere Vorgaben beachten. Im Gegensatz zu einem klassischen zentralen Storage müssen die Datenträger in einem Node oder Disk-Shelf immer die gleiche Größe haben. Ist dies nicht der Fall, werden normalerweise alle Datenträger identisch zum kleinsten Datenträger behandelt. Was man in der Darstellung der Architekturen und in diesem Abschnitt vielleicht auch schon zwischen den Zeilen lesen konnte: Ein klassisches RAID ist für den Ablageort der Objekte üblicherweise nicht vorgesehen und auch nicht empfohlen. Hier greift der Object Storage selbst ein und verteilt die Daten selbständig. Da das System weiß, welche Daten wo liegen und welche Bereiche der Datenträger noch frei sind, ist eine Wiederherstellung nach einem Ausfall einfacher: Es müssen nur die genutzten Bereiche wiederhergestellt werden. Eine Warnung an dieser Stelle: Besteht ein Zugriff auf das zugrundeliegende Betriebssystem, z. B. beim Einsatz von Open-Source-Software, so sollten die für den Object Storage genutzten Datenträger für nichts anderes verwendet werden!
Sobald mehr als ein Node zum Einsatz kommt, ist ein Object Storage ähnlich aufgebaut wie ein verteilter Storage. Mit dieser Ähnlichkeit kommt eine ganze Reihe von Vorteilen, gerade was Redundanz, Wiederherstellung und Skalierbarkeit angeht. Man bezahlt aber auch einen Preis dafür: Bei Ausfall eines Datenträgers oder Nodes erfolgt eine schnelle und gezielte Wiederherstellung der Daten an anderen Orten, um die Redundanz wieder herzustellen. Dies ist aber mit einer erheblichen Auslastung des Netzwerks und der Datenträger verbunden, was einen Einfluss auf den regulären Zugriff auf die Daten haben kann.
Damit kommen wir zu einem weiteren Thema, das beim Einsatz von Object Storage nicht außer Acht gelassen werden darf: Die Planung und Dimensionierung des Netzwerks. Dadurch, dass Object Storage vor allem für große Datenmengen geeignet ist, sollte auch eine entsprechende Netzwerk-Bandbreite zur Verfügung stehen. Die beste Technologie für die Ablage von Objekten im Terabyte-Bereich nutzt einem nichts, wenn das Netzwerk nur 100 Mbit/s liefert.
Auch das ist prinzipiell nichts neues: Ein klassischer Storage bietet normalerweise mehrere Ports mit hoher Bandbreite, die in Summe ein Vielfaches der Bandbreite der möglichen Clients liefern. Bei Object Storage kommt hier jedoch die Ähnlichkeit zu verteiltem Storage zum Tragen: Im Hintergrund oder bei einem Restore müssen die Daten auf mehrere Systeme verteilt werden, also erzeugt ein Object Storage auch viel Backend-Traffic. Zwar ist es grundsätzlich möglich, diese beiden Traffic-Arten über gemeinsame Netzwerk-Interfaces zu führen, es bietet sich aber an, den Backend-Traffic zu trennen. Mindestens über eigene Netzwerk-Interfaces der Nodes, im Optimalfall durch eigene Switches. Das führt insgesamt zu mehr Performance und ist deterministischer.
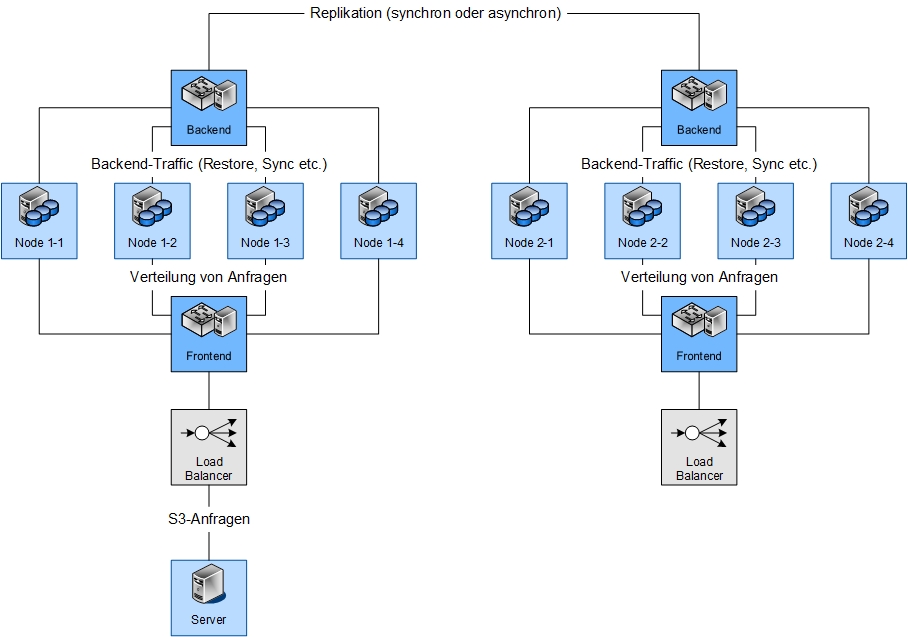
Abbildung 3: Beispielhafte Netzwerk-Topologie für einen Multi-Site, Multi-Node Object Storage
Damit sind die grundlegenden Aspekte von Object Storage geklärt: Was ist es? Wie benutze ich es? Wie werden die Daten im Hintergrund organisiert?
Bis jetzt haben wir nur ein paar „Eimer“, in die wir Daten einwerfen und aus denen wir sie wieder auslesen können. Was bietet uns Object Storage für weitere Möglichkeiten, gerade mit Blick auf die ganzen Zusatzinformationen, die an ein Objekt angehängt werden können?
Besondere Funktionen
Bei den weiteren Funktionen kommen wir in einen Bereich, in dem sich nicht alle Lösungen gleich verhalten. Ich möchte an dieser Stelle die häufigsten Funktionen erwähnen.
Zunächst ist da der Umgang mit den vielen verschiedenen Redundanz-Mechanismen und -Ebenen, die ich oben beschrieben habe. Diese sind typischerweise auf verschiedenen Ebenen konfigurierbar. Meistens gilt dies auf Bucket-Ebene, teilweise kann die gewünschte Redundanz für ein Objekt auch als Metadatum an ein Objekt angehängt werden.
Zusätzlich ist eine Versionierung von Objekten sehr häufig möglich. Das heißt: Sollte ein Objekt überschrieben werden, werden alte Versionen noch vorgehalten und können über entsprechende Anfragen auch wieder ausgelesen werden. Das kostet Speicherplatz im Object Storage, weswegen man typischerweise eine begrenzte Anzahl von alten Versionen vorhält. Wie viele das sind, muss konfiguriert werden.
Zu den Komfort-Funktionen von Object Storage gehören Suchfunktionen und die mögliche Vorverarbeitung der Daten.
Die Suchfunktionen basieren dabei auf Tags und anderen Metadaten, die an das Objekt angehängt sind. Damit können Nutzer alle Daten zu einem bestimmten „Thema“ schneller finden und runterladen.
Die Vorverarbeitung von Daten ist für Datenanalysen oder Anonymisierung/Pseudonymisierung sehr nützlich, erfordert aber ein tiefes Verständnis der zu erwartenden Daten und Kenntnisse in der Programmierung von entsprechenden Interfaces. Hier sind Cloud-Dienste im Allgemeinen im Vorteil, da sie typischerweise auch für den Object Storage optimierte Dienste für die Vorverarbeitung anbieten, z. B. AWS Lambda oder Azure Functions.
Auch lassen sich Objekte individuell verschlüsseln und der Schlüssel vom Object Storage verwalten. Wie weit man einem Object Storage hier vertraut, muss man für sich entscheiden, gerade bei Cloud-basierten Lösungen.
Und wo wir schon mit Verschlüsselung anfangen: Es gibt noch einige weitere Funktionen, die im Bereich der IT-Sicherheit helfen können:
- Benachrichtigungen auf Bucket-Ebene:
Viele Lösungen unterstützten eine Protokollierung und/oder Benachrichtigung bei bestimmten Ereignissen. Wird zum Beispiel immer wieder ein Objekt aktualisiert, dass eigentlich statisch sein sollte, kann das ein Indikator für einen Angriff sein. - Object Lock:
Bei der „Object Lock“-Funktion handelt es sich um eine Object-Storage-Version von „Write Once Read Many“ (WORM), wie man es vielleicht aus der Welt der Bandlaufwerke noch kennt: Daten können einmal geschrieben und beliebig oft gelesen, jedoch nicht mehr geändert werden. Markiert man ein Objekt in dieser Weise, wird es in keinem Fall geändert oder gelöscht und somit vor Manipulation, zum Beispiel durch Ransomware, geschützt. Im Gegensatz zu WORM-Tapes, die entsorgt werden, wenn sie nicht mehr benötigt werden, unterstützt Object Storage ein Ablaufdatum für die mit Object Lock versehenen Daten. Diess Ablaufdatum wird pro Objekt vergeben, und nach Ablauf dieses Datums können die Daten gelöscht und der Speicherplatz wieder anderweitig genutzt werden. Dabei wird zwischen zwei Modi unterschieden:
– Governance: Hier können die Nutzer, die die Daten ablegen, diese vor dem Ablaufdatum nicht mehr verändern oder löschen, Administratoren aber haben diese Möglichkeit.
– Compliance: In diesem Fall ist auch für die Administratoren eine Veränderung oder Löschung der Daten nicht möglich.
Damit haben wir jetzt die wichtigsten und einige spannende, weitere Funktionen kennengelernt. Es wurde bereits darauf eingegangen, dass bestimmte Funktionen von der genauen Lösung abhängen. Daher sollen im nächsten Abschnitt die Unterschiede etwas genauer beleuchtet werden.
Object-Storage-Varianten und ihre Unterschiede
Zuallererst soll hier noch mal wiederholt werden, was bereits weiter oben erwähnt wurde: Es gibt nicht „den einen Object Storage“, sondern verschiedene Varianten und Ausprägungen. Die vielleicht verbreitetsten Varianten dabei sind AWS S3 und Azure Blob Storage. Beide sind, wie der Name schon andeutet, von Cloud-Herstellern entwickelt worden und vor allem in der Cloud verfügbar.
Ein weiterer Object Storage, der bei einigen Kunden im Einsatz ist, ist Ceph. Dieser vor allem unter Linux verbreitete Object Storage wird typischerweise über Systeme angesprochen, die Ceph-spezifische Funktionen liefern und für Spezialaufgaben genutzt werden. Er bietet einige Funktionen, die für Object Storage untypisch sind, z. B. eine gezielte Änderung, dafür fehlen andere Funktionen. Man kann Ceph zwar über entsprechende Gateways über andere Protokolle ansprechen, darunter auch S3. Von den Vorteilen hat man dann aber nichts. Typische Beispiele für den Einsatz von Ceph sind hyperkonvergente Systeme (HCI – Hyper-Converged Infrastructure) und Supercomputing oder HPC (High Performance Computing).
Zusätzlich gibt es noch anderen Storage, der technisch gesehen zwar ein Object Storage ist, auf den aber immer nur über Abstraktionsschichten zugegriffen wird. Diese werden nicht weiter betrachtet.
Die Unterschiede zwischen den verschiedenen Versionen liegen vor allem in den genutzten Protokollen und – bei HTTPS-basiertem Object Storage – im genauen Format und dem Inhalt von Anfragen und Antworten.
Nicht alle Anbieter unterstützen dabei jeden „Dialekt“, und auch nicht jede Lösung ist on Premises verfügbar. Daher soll im nächsten Abschnitt betrachtet werden, wo und wie sich Cloud und on Premises unterscheiden.
Object Storage in der Cloud vs. on Premises
Direkt vorweg: Azure Blob Storage von Microsoft ist nur in der Azure-Cloud verfügbar. Es gibt zwei Ausnahmen:
- Für Tests und für Entwickler gibt es den Microsoft Azure Storage Emulator, der jedoch weder im Bereich Performance noch bei der Redundanz die Anforderungen einer typischen Unternehmensanwendung erfüllen kann.
- Hat man Azure Stack Hub im Einsatz, bietet dieses natürlich auch Storage-Technologien aus der Azure Cloud, und damit auch Azure Blob Storage. Diese sind zwar direkt im eigenen Rechenzentrum verortet, aber stark an Microsoft gebunden.
Das heißt, egal wie man es dreht und wendet: Will man Azure Blob Storage einsetzen, ist man auf Microsoft beschränkt.
Ganz anders sieht es beim Platzhirsch im Bereich Object Storage aus: S3-Storage ist in vielen Farben und Formen sowohl in der Cloud als auch on Premises realisierbar. Natürlich denkt man bei S3 unweigerlich als erstes an AWS – daher kommt es schließlich auch. Aber auch andere Cloud-Anbieter bieten S3-kompatiblen Storage. Und damit nicht genug: Auch on Premises gibt es von allen namhaften (und einigen weniger namhaften) Herstellern und Entwicklern S3-basierten Object Storage. Auch kleinere Hersteller können hier einen Blick wert sein.
Eine Alternative zu großen Herstellern kann Open Source sein, vorausgesetzt, die Hardware ist vorhanden, und die Möglichkeit für eine Einarbeitung besteht. Hier ist vor allem minIO zu erwähnen, welches eine sehr weitgehende Unterstützung der Funktionen von S3 liefert.
Open-Source-Beispiel: minIO
minIO ist die wohl verbreitetste Open-Source-Lösung für S3-basierten Object Storage. Es unterstützt alle oben genannten Architekturen (Single Node Single Drive, Single Node Multiple Drives, Multiple Nodes Multiple Drives) und bietet eine sehr umfangreiche und verständliche Dokumentation. Was besonders nützlich ist: minIO dokumentiert sehr offen, welche Funktionen von S3 nicht unterstützt werden und generell, welche Einschränkungen sonst bestehen. Auch ist die Dokumentation von minIO sehr deutlich darin, welche Szenarien nicht empfohlen werden, entweder aus Performance- oder aus Sicherheitsgründen.
Daher ist minIO gut dafür geeignet, erste Erfahrungen mit Object Storage zu sammeln und um Object Storage für Testzwecke bereitzustellen. Will man ein Produktiv-System für Object Storage auf Basis von minIO nutzen? Darauf gibt es die übliche Berater-Antwort: Es kommt darauf an. Technisch und hinsichtlich des Funktionsumfangs ist minIO gut aufgestellt, jedoch bedeutet ist es wahrscheinlich mit einem höheren Aufwand bei der Installation und beim Betrieb verbunden.
(Do Not) Use Cases
Als nächstes soll betrachtet werden, wofür Object Storage (gut oder nicht so gut) geeignet ist. Ja, es ist eine interessante Technologie., Das heißt noch lange nicht, dass ich damit meinen bisherigen Storage ablösen kann.
Fangen wir zunächst mit Bereichen und Use Cases an, für die Object Storage gut geeignet ist. Einige dieser Use Cases waren sogar die ursprüngliche Motivation für die Entwicklung von Object Storage:
- Big Data und KI:
Der erste Einsatzzweck von Object Storage war die Ablage großer Datenmengen, die sich selten bis gar nicht ändern, um diese dann auf leistungsstarken Servern zu analysieren. Hier war am Anfang „Big Data“ ein Kandidat für die Nutzung von Object Storage. Mittlerweile sind noch einige Use Cases hinzugekommen, die ähnliche Anforderungen stellenund andere Namen haben. Als aktuell prominentestes Beispiel sei hier Künstliche Intelligenz und insbesondere deren Training genannt. Hier werden Unmengen an Daten benötigt, die sich nicht ändern. Es werden lediglich weitere Daten in großen „Paketen“ hinzugefügt – die Paradedisziplin von Object Storage. - Backup und Archivierung:
Wenn man an große Datenmengen denkt, die selten geändert werden und bei denen die Performance nicht das Allerwichtigste ist, ergibt sich ein weiterer Use Case quasi von selbst: Backup und Archivierung. Man hofft, dass man eigentlich nur sichern und niemals wiederherstellen muss, also ist Object Storage ein vielversprechender Kandidat. In Verbindung mit der recht flexiblen WORM-Funktionalität, die nicht so endgültig ist wie bei WORM-Tapes, ergibt sich auch ein guter Schutz vor versehentlicher oder vorsätzlicher Manipulation und damit vor dem aktuellen Schreckgespenst der IT: Ransomware. Das haben auch die Entwickler von Backup-Software erkannt. Gerade die im professionellen Umfeld gängigen Backup-Lösungen unterstützen als Ziel Object Storage, egal ob on Premises oder in der Cloud. - Auslagerung alter Daten (Tiering):
Eine weitere Funktion, die Object Storage übernehmen kann, ist das Vorhalten alter Daten, die so selten genutzt werden, dass sie auf dem (teuren) Primär-Storage nur Platz wegnehmen, der eigentlich besser für andere Daten geeignet wäre. Damit sind wir in der auch nicht so neuen Welt des Storage-Tierings. Wo früher von SSD auf HDD ausgelagert wurde, bieten heute viele Storage-Systeme ein Tiering auf Object Storage an. Teilweise herstellerunabhängig, meistens jedoch mit einer optimierten Integration in die Object-Storage-Systeme des jeweiligen Herstellers. Ein kleiner Hinweis an dieser Stelle: Diese gute Integration lassen sich manche Hersteller in Form von zusätzlichen Lizenzen extra bezahlen!
Sollte ich mich für einen Cloud-basierten Object Storage entscheiden und diesen auch von meinen lokalen Systemen aus benutzen wollen, muss ich daran denken, dass die Daten auch übertragen werden müssen. Nicht umsonst bin ich auf einen möglichen Flaschenhals im Netz eingegangen. Bei Cloud-basiertem Object Storage kann dieser noch viel unangenehmer werden. Nicht umsonst bieten die großen Cloud-Anbieter auch die Möglichkeit an, Daten per Post zu verschicken und in den jeweiligen Object Storage zu übertragen. Hier greift ein Zitat von Andrew S. Tanenbaum: „Never underestimate the bandwidtch of a station wagon full of Tapes hurtling down the highway.“ Oder, frei übersetzt: „Unterschätze niemals die Bandbreite eines Kombis voller Tapes auf der Autobahn.“
Ich möchte auch nicht verschweigen, für was ein Object Storage nicht gut geeignet ist:
- Sobald ein System, welches externen Storage nutzt, viele Änderungen an den Daten vornimmt, ist ein Object Storage nicht gut geeignet. Selbst bei einer Aufteilung in viele Teile kann dies für die Änderung eines Blocks einen Upload von mindestens 5 MB bedeuten. Und bei Objektgrößen jenseits von 50 GB werden die jeweiligen Teile der Daten unweigerlich größer. Bei Datenbanken zum Beispiel kann dies zu enormen Performance-Problemen führen.
- Bei der Ablage vieler kleiner Dateien/Objekte läuft man in eine andere Herausforderung: Jedes Objekt muss in einem eigenen Request hochgeladen werden. Der Overhead für den Verbindungsaufbau kann hier signifikant sein. Sind dann noch viele Metadaten an das Objekt angehängt, wird das Verhältnis zwischen zu übertragenden Daten und den eigentlichen Nutzdaten noch ungünstiger.
Die Sicherheit von Object Storage
Ein weiteres Thema, das ich ansprechen möchte, ist die Sicherheit von Object Storage. Denn man liest immer wieder davon, dass S3 Buckets im Internet gefunden werden, auf denen vertrauliche Daten liegen, auf die komplett ohne weitere Authentisierung zugegriffen werden kann. Daraus könnte man schließen, dass Object Storage inhärent unsicher ist. Das ist nicht der Fall. Object Storage bietet viele Sicherheitsmechanismen, auch was die Zugriffsregelung angeht. Und wir haben mit dem Object Lock auch schon ein weiteres Puzzle-Stück gesehen, das sich positiv auf die Sicherheit auswirken kann. Woher kommen also diese ganzen Datenlecks, von denen man auf einschlägigen Newstickern immer wieder liest?
Ganz einfach: Die Sicherheitsmechanismen von Object Storage müssen auch konfiguriert und genutzt werden. Es nutzt mir nichts, ein großartiges RBAC zu haben, wenn ich keine Authentisierung verlange, sondern alle Anfragen beantworte!
Früher war die Situation bei AWS nicht ganz optimal, da viele Sicherheitsmechanismen für S3 Buckets im Standard deaktiviert waren. Hier hat sich einiges getan, und die wichtigsten Mechanismen inklusive Authentisierung sind mittlerweile per Default aktiviert. Das hilft jedoch nicht, wenn man die Mechanismen dann aus Bequemlichkeit wieder abschaltet!
Wie bei so vielen Systemen und Maßnahmen in der IT bedeutet das also: Ich kann es sicher betreiben, muss mir aber Gedanken dazu machen und die Mechanismen, die mir zur Verfügung stehen, auch konsequent einsetzen.
Fazit
Zusammenfassend kann man über Object Storage sagen, dass es eine sehr interessante und nützliche Technologie ist. Object Storage insgesamt ist gekommen, um zu bleiben, denn es bietet eine einfache und vergleichsweise günstige Möglichkeit, mit großen Datenmengen umzugehen.
Wird Object Storage unseren bisherigen Storage ablösen? Definitiv nicht, denn die Art und Weise, wie Daten abgelegt und verarbeitet werden, passt einfach nicht zu allen Use Cases. Im Bereich Big Data, KI und Backup haben wir mit Object Storage etwas, was bisherige Technologien mindestens ergänzen und in einigen Fällen sogar ablösen kann.
Ist es sinnvoller, Object Storage aus der Cloud oder lokal zu beziehen? Das hängt maßgeblich davon ab, welche Datenmenge übertragen wird und wo meine „Clients“ für den Object Storage verortet sind. Habe ich alles in der Cloud, ist eine On-Premises-Lösung wenig sinnvoll. Umgekehrt bietet mir ein Object Storage in der Cloud, den ich von lokalen Systemen aus nutze, eine gewisse Redundanz und Standort-Unabhängigkeit. Hier muss auch die Bandbreite meiner Cloud-Anbindung mitspielen!



Kontakt
ComConsult GmbH
Pascalstraße 27
DE-52076 Aachen
Telefon: 02408/951-0
Fax: 02408/951-200
E-Mail: info@comconsult.com
![]()