Wie immer bei diesen Analysen muss man davon ausgehen, dass sie einerseits nicht vollständig sind und andererseits mit einem Unsicherheitsfaktor versehen sind. Die Entwicklungen, die wir hier beschreiben, sind häufig mit exponentiellen Technologien verbunden. Was ist das? Stellen Sie sich vor, Sie gehen um die Welt und verdoppeln mit jedem Schritt ihre Schrittlänge. Je nach Schrittlänge sind Sie dann mit 28 bis 30 Schritten um die Welt gegangen. Das spannende ist dabei der letzte Schritt: er bringt Sie um die halbe Welt. Überträgt man das auf neue Technologien, dann kann man sagen, dass wir Technologien sehen und auch ihr Potenzial erkennen, disruptiv zu sein, dass wir aber nicht genau wissen, ob sie kommen oder nicht. Aber wenn sie denn kommen, dann sind sie auf einmal da und verändern Märkte und Produkte in einem signifikanten Umfang sehr schnell. Viele dieser Technologien kommen aber nie bis zu diesem Punkt, sie setzen sich einfach nicht so durch wie man vorher angenommen hatte. Naturgemäß sind deshalb exponentielle Technologien extrem schwierig vorherzusagen.
Es gibt unzählige Beispiele für solche Entwicklungen. Der Übergang von einer Anlagen-basierten Telefonie hin zu IP-Telefonie gehörte genauso dazu wie die Einführung von SSD-Speichertechnologie oder allgemeiner der Übergang von Spezialhardware hin zu Softwarelösungen auf Standard-Hardware. Manchmal stockt die Entwicklung auch, wie zum Beispiel bei der Ablösung von Spiegelreflexkameras durch spiegellose Kameras. Aber dann gibt es auf einmal einen technologischen Durchbruch wie in diesem Beispiel beim Autofokus und die Welle rollt wieder.

Abbildung 1: Richtungsentscheidungen sind gefragt
Kommen wir zu unseren Prognosen für die nächsten Jahre. Die Reihenfolge der angesprochenen Themen ist dabei rein willkürlich.
Digitalisierung, Automatisierung, Internet of Things
Digitalisierung, oder an dieser Stelle auch aus der Perspektive des Internet of Things gesehen, ist so ein Thema, bei dem man manchmal denkt, alle reden darüber und keiner geht hin. Aber das ist bei näherer Betrachtung nicht korrekt. Es gibt unzählige Projekte, die den Markt verändert haben, man nimmt sie nur nicht immer sofort wahr. Ein typisches Beispiel sind Flug-Cancellations. Es gibt führende Fluggesellschaften, die heute einen Zustand erreicht haben, bei dem 95% der Flüge stattfinden. Und die verbleibenden 5% Ausfälle sind Wetterbedingt. Dies sind aber gigantische Projekte, die Jahre an Optimierungen erfordert haben. Aber ohne Digitalisierung und den intensiven Einsatz von Technologien wie “predictive” Maintenance hätte man das nicht geschafft. Und auch am Wetter arbeitet man. IBM entwickelt im Moment Lösungen, die Turbulenzen 60 Minuten im voraus berechnen können. Ausreichend Zeit, um die Flugroute anzupassen. Oder aus demselben Markt stammen die Verbesserungen, die Qantas erreicht hat. Früher liefen Programme zur Optimierung von Flugrouten zwischen Australien und den USA 2 Monate. Heute sind wir bei 2 Stunden. Anders formuliert: Flugrouten auf Langstrecken könnten bei Bedarf in Realzeit angepasst werden. Dann können wir nur hoffen, dass die Bundesbahn auch bald mal damit anfängt.
Wenn wir über Digitalisierung oder das Internet of Things sprechen, dann gibt es eine zentrale Frage, die sich aufdrängt und auch sicher die Mehrheit der deutschen Entscheider betrifft: was ist jetzt eigentlich anders als vor einigen Jahren? Was unterscheidet Digitalisierung von Themen wie kontinuierlicher Verbesserung? Warum reden wir gerade jetzt darüber?
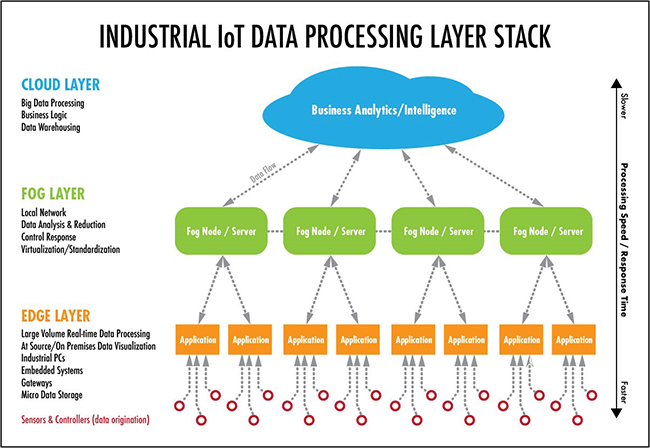
Digitalisierung oder synonym das Internet of Things sind erst einmal in den meisten Fällen identisch mit neuen Ansätzen zur Automatisierung von Abläufen, die es so vorher nicht gab oder die bisher nicht gut gelöst werden konnten. Um auf die Frage nach dem “warum jetzt” eine Antwort zu geben, muss ein kleiner Umweg über den Aufbau von Automatisierungssystemen gewählt werden. Die Abbildung 2 zeigt eine typische Systemarchitektur.
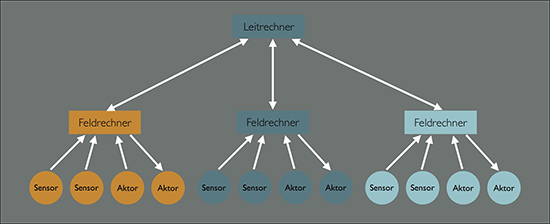
Abbildung 2: Aufbau eines Automatisierungs-Systems
Generell werden in Automatisierungslösungen Daten ermittelt, die dann entweder direkt oder über den Umweg einer Verdichtung (zum Beispiel zur Mittelwertbildung oder zum Aufbau kleiner lokaler Regelkreise) in auf den Daten aufsetzende Berechnungen einfließen. Je nach Ergebnis der Berechnung werden dann Handlungen ausgelöst. Parallel werden “Dashboards” mit Prozessübersichten und Alarmen gefüttert. Für tiefergehende Analysen wird ein umfassendes Reporting unterstützt. Damit sind immer folgende Elemente einer Automatisierungslösung gegeben:
- Daten
- Berechnung / Auswertung
- Darstellung
- Handlung
- Reporting / Analyse
Typisch für Automatisierungs-Lösungen ist dabei auch, dass es historisch gesehen häufig geschlossene Lösungen für genau eine Aufgabe sind. Anders formuliert stehen die Daten, die in einer Automatisierungslösung anfallen, nicht für andere Lösungen zur Verfügung.
Diese Situation ist nicht neu und es macht Sinn, an dieser Stelle den Blick in die Vergangenheit zu werfen. Wir hatten ca. um 1985 herum den Versuch, Fertigungs-Automatisierung auf eine neue Basis zu stellen. Das war zu der Zeit ein unglaublicher Hype. Die Kernidee war dabei, Daten zu öffnen und generell für verschiedene Nutzungsbereiche zugänglich zu machen. Dabei wurden auch Probleme angesprochen wie die Frage, woher eine fremde Applikation eigentlich weiß, über welche Daten wir hier sprechen und in welchem Umfang sie davon abhängig ist, wenn sich die Daten-liefernde Applikation ändert. Um dies zu verwirklichen, wurden mehrere namhafte Standards entwickelt:
- Das Manufacturing Automation Protocol MAP
- Das Manufacturing Message Specification MMS
Das Ergebnis war technisch sehr weitgehend, aber extrem komplex. Diese Komplexität und der Ansatz auf der Daten-ebene mit dem Versuch, die benutzten Daten zu standardisieren, haben sicher dazu beigetragen, dass der breite Markt-erfolg dieser Lösung nicht so ausfiel wie ursprünglich erwartet. Auch verweigerten sich die Hersteller von Automatisierungs-Lösungen schlicht der Bereitstellung ihrer Daten für andere Anwendungen anderer Hersteller.
Betrachtet man diese Situation, dann lässt sich die Frage, warum es jetzt anders ist als früher und warum wir heute Lösungen entwickeln können, die es bisher nicht gab, in folgende Bereiche einteilen:
- Die Komplexität der Lösung
- Die erreichbare Offenheit der Lösungsarchitektur
- Die Menge an verfügbaren Daten
- Die Fähigkeit, Daten in geeignet kurzer Zeit auszuwerten und auf der Basis der Auswertung Handlungs-Entscheidungen zu treffen
- Die Möglichkeiten zur Umsetzung qualitativ hochwertiger Dashboards und die Standort-übergreifende Nutzung derselben
- Die bestehenden Transport- und Kommunikationsmöglichkeiten
Zum Thema Cloud und Offenheit hat sich seit 1985 viel verändert. Wir haben das Internet, neue Möglichkeiten der Programmierung (Objekt-Architekturen) und die Cloud. Die Cloud basiert auf dem Grundgedanken, verschiedene Applikationen miteinander kombinieren zu können. Platform as a Service-Umgebungen, aber auch Spezialanbieter wie Zapier oder IFTTT sind Beispiele für eine andere Markt- und Technologie-Situation (auch wenn die hier realisierten Schnittstellen für Automatisierung nur sehr bedingt nutzbar sind). Beim Internet of Things haben wir eine ganze Reihe von Cloud-basierten Frameworks, deren Hauptaufgabe in der Verbindung verschiedener Applikationen und der damit verbundenen Bereitstellung von Daten liegt. Davon werden die meisten auch wieder verschwinden, für den Kunden ist daher im Moment eher die Frage relevant, wie die Zukunftssicherheit einer solchen Plattform aussieht. Auch die insgesamt auf einer Plattform angebotenen Möglichkeiten zur Gestaltung von Anwendungen (die Qualität und die Funktionalität der Entwicklungsumgebung) sollte dabei berücksichtigt werden. Und aus dieser Gesamtsicht heraus haben Anbieter wie Amazon, Microsoft und Oracle sicher Vorteile gegenüber der Konkurrenz. Die dabei gegebene Hersteller-Bindung ist ein generelles Problem solcher Lösungen. (siehe Abbildung 3)
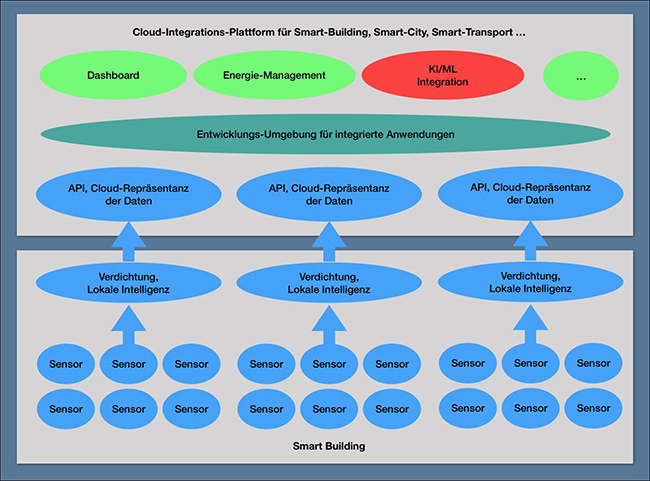
Abbildung 3: Moderne Architektur für Gebäudeautomatisierung
Damit haben wir heute im Bereich der Systemarchitekturen und ihrer Komplexität und Offenheit eine völlig andere Situation als noch vor wenigen Jahren. Dies bedeutet aber nicht, dass es generell einfach ist, solche Lösungen zu entwickeln. Viele Anbieter traditioneller Technologien (zum Beispiel Heizung-Klima-Lüftung oder Transport) haben erkannt, dass der Wunsch zum Zugang auf ihre Daten besteht. Die Umsetzung ist aber häufig Low-Level auf der Basis von APIs. Auch wenn ein Hersteller seine Produkte auf der API-Ebene für Dritte öffnet, muss das nicht automatisch eine ausreichende Basis für eine tragfähige Systemarchitektur sein. Von der Qualität, die MAP/MMS mit seinen Objektdefinitionen geliefert hat, sind wir hier weit entfernt. Dies generiert erhebliche Herausforderungen im Bereich des Facility Managements, das auf einem mit einem komplexen Change Management konfrontiert wird, das es so früher nicht gab.
Der nächste große Punkt der Änderung ist die Verfügbarkeit von Daten. Wir erleben im Moment eine Explosion des Angebots an Sensorik. Und wir stehen erst am Anfang dieser Entwicklung. Betrachten wir den Bereich der Gebäudeautomatisierung, so werden wir wohl erst in drei bis fünf Jahren auf der Höhe der Entwicklung sein. Bis dahin werden wir noch viele neue Anbieter kommen und gehen sehen. Aber Tatsache ist, dass wir über unsere Prozesse heutzutage viel mehr Daten bekommen als in der Vergangenheit. Ein typisches Beispiel sind die Lampensysteme von Philips, die über Power over Ethernet eine offene Schnittstelle für Sensoren in den Deckenleuchten liefern. Die Kombination aus Power over Ethernet und einer offenen Sensor-Schnittstelle ist dabei ein generell spannendes Thema, da es eine spätere Nachrüstung von Sensoren und Aktoren erlaubt und zugleich den Strom dafür bereitstellt.
Dies führt dann direkt zu der Frage der Auswertbarkeit dieser Daten. Diese hängt extrem von der Natur der Anwendung ab. Manchmal reicht es schon, mehr Daten zu haben, um daraus dann auf der Basis relativ einfacher Entscheidungsmodelle zu Handlungen zu kommen. Die Frage der notwendigen Menge an Daten für neue Auswertungsverfahren ist dabei absolut zentral. Manchmal können wir die Daten aber nur sinnvoll mit künstlicher Intelligenz oder Machine Learning auswerten, dazu später mehr im Abschnitt über Machine Learning. Wichtig ist dabei an dieser Stelle, dass Machine Learning im aktuellen Stand der Technik erhebliche Datenmengen braucht, um zu akzeptablen Ergebniswahrscheinlichkeiten zu kommen. Die Forschung arbeitet an neueren Verfahren, die mit geringeren Datenmengen auskommen. Diese neuen Verfahren sind aber bisher nicht verfügbar. Brauchen wir aber sehr viele Daten, dann entstehen immer zwei Fragen: haben wir diese Daten in einem ausreichenden Umfang für signifikante Ergebnisse? Wie bekommen wir sie transportiert?
Rechenleistung ist heutzutage kaum ein Problem. Wir können diese sowohl lokal in einem fast beliebigen Umfang bereitstellen oder auf Angebote in der Cloud zurückgreifen. Die Frage ist da eher, wo Daten anfallen und wie wir sie an den Ort der Auswertung transportiert bekommen. Dies ist speziell ein Problem, wenn wir über Echtzeitanforderungen sprechen (zu diesem Begriff eine Warnung: die Anforderung an Echtzeit wird immer wieder als wesentliches Kriterium für ein Systemdesign angeführt. In der Realität erfordern aber nur wenige Anwendungen wirkliche Echtzeit. Hier sollte man sich von dem scheinbar sinnvollen Begriff nicht in die Irre führen lassen. Bei Cloud-Nutzungen hat der Begriff aber eine andere Dimension. Wenn einzelne Cloud-Anbieter ihre Lösungen zum Beispiel nur in einem Rechenzentrum in Irland anbieten, dann haben wir eine erhebliche Laufzeit bis nach Irland zu berücksichtigen. Cloud bedeutet eben auch, dass wir prüfen müssen, wo wir tatsächlich physikalisch die Daten verarbeiten, wenn wir an Echtzeit interessiert sind. Mehr dazu später unter dem Begriff Edge-Computing).
Neben den Daten dominiert eher die Frage der auswertenden Algorithmen und wo diese zur Verfügung stehen. In den meisten Fällen wird man im Moment geeignete Frameworks für KI und ML eher in der Cloud finden (das muss aber nicht so sein, wenn lokal ein ausreichendes Wissen über solche Verfahren existiert. Auch kann sich das schnell ändern, wenn einzelne Anbieter wie IBM oder Microsoft eine Marktlücke für hybride Szenarien sehen).
Bei der Frage der verfügbaren Kommunikationswege gibt es mehrere Faktoren zu berücksichtigen:
- Die Verfügbarkeit und Stabilität eines Weges
- Bandbreite und Latenz
- Kosten
- Sicherheit
Bei dem Design der notwendigen Kommunikations-Lösungen dominieren in der Praxis drei zentrale Probleme:
- Die Integration von Anschlusspunkten in Netzwerke, ohne dass dafür umfangreiche Konfigurationen auf der Netzwerkseite erforderlich sind. Wir sprechen hier potenziell über Tausende von Anschlüssen. Die Idee, diese einzeln zu konfigurieren, ist einfach nicht tragfähig. Das ist auch mit der Frage verbunden, wer die entsprechenden Konfigurationen durchführen würde. Wir wollen in der Regel nicht, dass ein Techniker im Feld, dessen Erfahrung eher auf HKL fokussiert ist, auf einmal vor dem Problem steht, komplexe Konfigurationen in Netzwerken auszuführen.
- Den Schutz verschiedener Anwendungsbereiche gegeneinander. So muss die generelle Regel sein, dass eine wie auch immer geartete Störung in einem Bereich keinerlei Rückwirkungen auf andere Anwendungen haben darf. Schon die Diskussion von Netzwerk-Flutungen durch fehlerhafte Endpunkte in Kombination mit Funkanbindungen zeigt dabei wie kritisch diese Anforderung ist. Wir brauchen auf der Übertragungsebene so etwas wie eine Übertragungsgarantie und einen Schutz gegen andere Nutzer. Man beachte, dass dies bei der heutigen WLAN-Technik IEEE 802.11ac nicht gegeben ist
- Der gesamte Sicherheitsbereich. Wenn wir Tausende von neuen Teilnehmern in die Netzwerke nehmen, sind wir nicht in der Lage, das sichere Verhalten jedes einzelnen Anschlusses zu garantieren. Und das Beispiel des Mitarbeiters, der an der Kaffeemaschine mit seiner Firmenkarte bezahlt, die gleichzeitig seine Zugangsberechtigungen innerhalb der Firma enthält, zeigt wie komplex es werden kann. Oder der tolle automatische Staubsauger aus China, der vorsichtshalber mit seiner Kamera die gesamte Umgebung scannt und die Beschriftungen von Whiteboards in Besprechungsräumen direkt ins Reich der Mitte überträgt. Viele der größeren intelligenten Sensoren und Aktoren sind auch ggf. anfällig gegen Übernahmen durch Hacker. Wir müssen dieses Risiko einfach unterstellen. In dieser Situation bleibt nur ein geeigneter Ansatz: wir müssen jeden einzelnen Endpunkt als unsicher einstufen. Multipliziert man das mit der Mengen an Kommunikationsvorgängen, dann ist auch klar, dass die bisher bestehenden Sicherheitseinrichtungen dabei nicht skalieren werden
Damit nicht genug, gibt es weitere Herausforderungen. Je nach Technologiebereich waren in der Vergangenheit Automatisierungslösungen eher statisch. Das “Smart-Building” war häufig genauso smart wie am Tag der Übergabe an den Bauherrn. Danach gab es keine Änderungen mehr. Und das System hätte Änderungen auch gar nicht verkraftet. Dies ist aber heute nicht mehr möglich. Da wir die wirkliche Spitze der Entwicklung von Sensorik noch erwarten, müssen unsere Lösungen offen gegenüber zukünftigen Änderungen sein.
Anders formuliert:
- Wir brauchen eine Infrastruktur für Sensorik und Aktoren, die unabhängig von der Sensorik selber ist und die Plattform für zukünftige Erweiterungen legt.
Die Zeiten, in denen eine Heizungssteuerung ein spezielles Thermostat mit einem speziellen Kabel an eine spezielle Steuerung angebunden hat, sind vorbei. Auch kann nicht mehr jeder wie er will eigene isolierte Funksysteme für seine Sensoren aufbauen. Diese sollten als Infrastruktur bereitstehen. Einzelne Automatisierungsbereiche dürfen nicht mehr isolierte Infrastrukturen ohne Berücksichtigung des Gesamtbildes anlegen. Anders ist die Situation, wenn eine Infrastruktur wie 5G genutzt wird, die ja genau mit diesem Ziel aufgebaut wird und entsprechend skaliert (hoffentlich). Auch wenn 5G für viele Automatisierungen zu teuer und zu komplex sein wird, zeigt es doch in die richtige Richtung: wir brauchen eine autonome und skalierbare Infrastruktur für alle Automatisierungsbereiche.
Viele der Diskussionen um Digitalisierung und IoT muss man mit einer gewissen Vorsicht betrachten. Neben der Frage der benötigten Daten und vor allem auch der Anzahl der Daten gibt es noch die Herausforderung, die Handlungen, die sich aus diesen Daten ableiten, auch umsetzen zu können. Am einfachsten dürfte dies bei der Optimierung menschlicher Prozesse sein. Aber technische Prozesse wie die Optimierung des Energieverbrauchs von Gebäuden erfordern, dass auch etwas geschaltet werden kann. Und genauso granular wie man die Daten sammelt, möchte man im Zweifelsfalle auch schalten. Dies dürfte in vielen Fällen für bestehende Gebäude sehr komplex und teuer sein.
Fasst man diese Ausführungen zum Bereich Digitalisierung/IoT zusammen, dann entsteht folgende Liste zu lösender Aufgaben im Bereich von IT-Infrastrukturen:
- Vorbereitung der Netzwerk-Infrastruktur auf sehr hohe Mengen von Endpunkten
- Automatische Einfügung eines neuen Endpunkts zum Netzwerk mit Zuweisung entsprechender Netzwerkeigenschaften
- Aufbau einer Sensor-Infrastruktur-Kommunikations-Plattform
- Verkabelung
- Funk
- Power over Ethernet
- Aufbau einer Sicherheitslösung für unsichere Endpunkte
- Aufbau eines Betriebs mit automatischer Erkennung von Anomalien
- Gestaltung eines Desaster-Reaktionskonzepts für ausgewählte Störsituationen
- Aufbau eines geeigneten Cloud-Zugangs
- Auswahl einer geeigneten Cloud-Plattform
- Klärung der juristischen Rahmenbedingungen bei der Nutzung der Cloud
- Aufbau eines umfassenden Sicherheitssystems, das speziell die Cloud abdeckt
Künstliche Intelligenz KI und Machine Learning ML
Die Abkürzungen KI und ML haben sich in den letzten Jahren zu einem Hype entwickelt. Wer sie nicht kennt, ist out. Tatsächlich sprechen wir hier über eine typische exponentielle Technologie. Das Potenzial ist groß, aber die Entwicklung ist etwas undurchschaubar. Es besteht das Risiko, dass wir in Zukunft auf einmal mit neuen Lösungen überschwemmt werden, die wirklich funktionieren.
An dieser Stelle soll keine Grundlagen-Einführung in KI und ML erfolgen. Das würde hier völlig den Rahmen sprengen. Wir haben dazu spezielle Veranstaltungen und auch Vorträge auf dem ComConsult Netzwerk Forum im März. Wer tiefer graben will, den verweisen wir auf diverse Kurse bei Coursera [1] oder speziell auch die Vorlesungsmitschnitte von Andrew Ng auf YouTube aus seiner Zeit an der Stanford University.
Ein Problem, das wir bei KI und ML haben, ist, dass es modern geworden ist, jede Form der einfachen mathematischen Berechnung mit diesem Siegel zu versehen. Vermutlich sind mehr als 90% der Lösungen, die als ML angeboten werden, traditionelle Mathematik.
Was auch nicht übersehen werden darf, ist, dass diese Lösungen in der Regel kein eindeutiges Ergebnis liefern. Im andauernden Kampf um die beste Spracherkennung liegen wir im Moment bei 95% Erkennungsrate (was herausragend ist). Es scheint auch nicht untypisch zu sein, dass in anderen Bereichen nur 80% Genauigkeit erreicht werden. Das ist gerade bei Predictive Maintenance ein Problem. Wer will schon eine Maschine austauschen, wenn nicht 100% sicher ist, dass sie wirklich ein Problem hat. Es gibt natürlich Bereiche wie die Flugzeugindustrie, in denen man diesen Weg gehen wird, aber bei mehr alltäglichen Problemen wie einem Motor in einer Rolltreppe oder einem Aufzug, sieht die Lage schon anders aus.
Diese Genauigkeit des Ergebnisses ist aber tatsächlich der Grund, warum wir über KI und ML überhaupt sprechen. Die vor noch 5 Jahren eingesetzten Verfahren waren fast generell nicht in der Lage, präzise und verwertbare Ergebnisse mit einer ausreichenden Präzision zu liefern. Dies hat sich in den letzten Jahren geändert. Mit einer kleinen Einschränkung: die meisten guten Verfahren funktionieren nur, wenn wir extrem viele Daten als Basis haben.
Die berühmte Grafik von Andrew Ng verdeutlicht diesen Zusammenhang. Dies schränkt aber die Nutzung von KI und ML in der Praxis stark ein. Zum einen ist es nicht ungewöhnlich, dass wir diese Datenmengen nicht zur Verfügung haben. Zum anderen müssen wir sie dann auch dort verfügbar haben, wo wir die Berechnungsverfahren durchführen wollen. (siehe Abbildung 4)
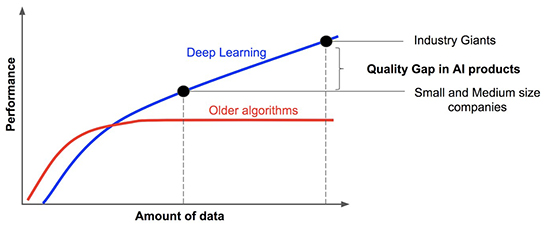
Abbildung 4: Warum Machine Learning heute viel besser funktioniert und gleichzeitig damit ein Problem für Anwender ist: es werden zu viele Daten benötigt
So ist es nicht verwunderlich, wenn man intensiv daran forscht, dass diese neuen Verfahren auch mit kleinen Datenmengen arbeiten (man spricht von Small Data Verfahren). Auch versucht man, Daten und Berechnung einander räumlich näher zu bringen. Dazu mehr unter Edge Computing.
Ein anderer Ansatz der Lösung des Small Data Problems sind Cloud-Services, die Daten Kundenübergreifend und zum Teil auch international sammeln und so zu sehr großen Datenmengen kommen. Diese können dann wieder auf den einzelnen Kunden mit ML-Berechnungen übertragen werden. Solche Lösungen werden gerade auch in Bereichen diskutiert, in denen die Wartungskosten sehr hoch sind und die Wirtschaftlichkeit der gesamten Lösung gefährden. Windräder gehören zu diesem Bereich. (siehe Abbildung 5)
Dieser AssetCare-Ansatz dürfte einer der Wege sein, um für Smart-Buildings oder Smart-Cities das Small-Data Problem zu lösen. Er wird hier auch als Beispiel genannt, da er zeigt, dass solche Fortschritte aus einer Kombination aus Cloud und ML entstehen. Es dürfte zum jetzigen Zeitpunkt realistisch sein, die größten Potenziale von KI und ML gerade in Verbindung mit IoT in der Cloud zu sehen.

Abbildung 5: AssetCare der Firma mCloud sammelt kundenübergreifend Heizungs- und Lüftungsdaten und steuert auf der Basis der insgesamt gewonnen Information die Heizungssysteme der einzelnen Kunden
Man sieht an diesem Beispiel oder generell beim Thema Smart-Building aber auch, dass wir am Anfang einer Entwicklung stehen, die man im Moment vielleicht noch als unreif ansehen muss, die aber in den nächsten Jahren sehr schnell an Bedeutung gewinnen wird.
Kann man also die Entwicklung in Ruhe abwarten? Die Antwort ist aus mehreren Gründen ein klares Nein. Zum einen reden wir hier über eine exponentielle Technologie. Wenn der letzte Schritt dieser Entwicklung vollzogen wird, wird er mit einem Schritt die Hälfte des Gesamtweges zurücklegen. Sprich: dann geht es auf einmal sehr schnell. Wer dann nicht vorbereitet ist, wird ggf. einen Nachteil gegenüber Konkurrenten haben, die sich hier besser aufgestellt haben. Zum anderen geht es bei KI und ML nicht nur um Prozessoptimierungen. Wir sprechen hier auch über sehr ernstzunehmende Sicherheitsrisiken. Diese Verfahren werden zunehmend auch im Angriff von Hackern eingesetzt. Und der einzige Schutz wird vermutlich darin bestehen, selber auch auf KI und ML zu setzen.
Die aktuelle Situation bei KI und ML führt zu folgender Liste von Aufgaben:
- Identifizieren Sie die Bereiche, in denen KI und ML einen Zugewinn bringen können
- Schaffen Sie eine Ausgangslage mit einer ausreichenden Datenmenge. Auch wenn wir heute über Small Data sprechen, werden dies, wenn es denn jemals kommt, immer noch sehr große Datenmengen sein. Noch einmal: KI und ML brauchen Daten, der Rest ist Handwerk. Ohne Daten geht gar nichts. Wer sich gegenüber einer zukünftigen Dominanz dieser Technologien vorbereitend absichern will, der stellt sicher, dass Daten vorhanden sind. Siehe dazu die Ausführungen unter Digitalisierung
- Bereiten Sie sich auf eine Cloud-Nutzung für solche Anwendungen vor, dies beinhaltet auch die Frage des Zugangs zur Cloud und die daraus abzuleitenden Sicherheitsrisken
- Bauen Sie Know How in diesem Bereich auf
- Entscheiden Sie, wie und wo sie die diese Datenmengen verarbeiten wollen
- Diese extrem großen Datenmengen müssen transportiert werden. Alle darauf bezogenen Anforderungen finden sich unter dem Abschnitt über Digitalisierung
Die Cloud
Über dieses Thema haben wir in den letzten 12 Monaten schon relativ viel geschrieben. Deshalb hier nur eine sehr kurze Ausführung.
Wir unterscheiden traditionell Infrastructure as a Service IaaS (Rechenleistung, Speicher, Netzwerke, …), Platform as a Service PaaS (Entwicklungsumgebungen, Datenbanken, Baukästen zur Kopplung mit anderen Cloud-Anwendungen, …) und Software as a Service SaaS. Als die Cloud startete, gab es einen Fokus auf IaaS verbunden mit der Diskussion, ob die Cloud preiswerter ist oder nicht. Das hat sich dann schnell gelegt, da wir wirtschaftlichen Vorteile bei IaaS in der Praxis bis auf Spezialfälle gar nicht so groß sind bzw. waren.
Was wir in den letzten zwei bis drei Jahren erleben, ist ein zunehmender Schwerpunkt der Entwicklung auf PaaS und SaaS. Die Zahl der Projekte in beiden Bereichen explodieren geradezu.
PaaS hat dabei sehr unterschiedliche Anwendungsbereiche:
- Aufbau von Anwendungen für Kunden im Rahmen neuer oder deutlich verbesserter Vertriebs- und Service-Prozesse (allgemein gesprochen von Anwendungen, die sich an Nutzer außerhalb des Unternehmens wenden)
- Ablösungen der bisherigen DMZ-Anwendungen
- Auslieferung von digitalen Medien im großen Stil
- Kopplung zwischen verschiedenen Cloud-Anwendungen (man betrachte den beginnenden Hype zu CPaaS im UC-Markt) auch unter Einbeziehung spezieller Dienste, die sich auf den Kopplungsbereich konzentrieren (IFTTT, Zapier zum Beispiel)
- Verringerung von Projekt- und Auslieferungszeiten von Software um dramatische Dimensionen (Beispiele erzielen hier Verbesserungen von 2 Jahren auf 2 Monate, wir sprechen also über extreme Verbesserungen)
Der Sinn oder Unsinn von IaaS oder PaaS kann vermutlich je nach Standpunkt und Unternehmenstyp verschieden gesehen werden. Aus unserer Sicht haben die großen PaaS-Lösungen wie Amazon AWS, Microsoft Azure oder Oracle inzwischen eine Leistung erreicht, die so lokal kaum zu erreichen ist, auch wenn es hybride Szenarien gibt. Oracle macht selber zum Beispiel keinen Hehl daraus, dass seine Zukunft in der Cloud liegt und die Cloud alle ERP On-Premise-Installationen ablösen wird (siehe aktuelles Interview vom 15.1.2019 von Bloomberg Technologies mit Oracle Chef Mark Hurd [2].
Dies ist die Situation bei PaaS. Was sich aber kaum diskutieren lässt, ist die Tatsache, dass der Software-Markt sich in Richtung SaaS bewegt. Die technischen und wirtschaftlichen Vorteile für die Hersteller von Software sind so groß, dass eine traditionelle Entwicklung oder Lieferung kaum noch in Betracht kommt.
Dazu unsere Prognose:
- Standard-Software wird in Zukunft komplett aus der Cloud kommen, dies umfasst nicht nur einfache Office-Anwendungen, sondern geht bis in den ERP-Bereich. Die Frage hier ist nicht ob, sondern wann. Dies mag ein Prozess von 10 Jahren sein, aber er ist bereits so weit, dass er nicht mehr aufgehalten werden kann.
Parallel entsteht eine neue Welt von Applikationen im Umfeld Team-Kollaboration. Hier geht es darum, Kommunikations- und Kollaborations-Funktionalität bereit zu stellen, die sich nicht auf ein Unternehmen oder einen Standort reduziert. Dies wird im Markt heute als Cloud-Thema gesehen und technisch gesehen gibt es auch kaum Alternativen zu einem Cloud-Ansatz. Google hat diese Tür ursprünglich mit seiner G-Suite geöffnet, dann haben Anbieter wie Slack, Asana oder Trello neue Typen von Software in der Cloud geschaffen, die es so On-Premise nicht mehr gibt. Und spätestens die Diskussion über Office 365 zeigt, dass für die absolute Mehrzahl der Kunden eine Zukunft ohne Cloud nicht mehr existieren wird. Interessant sind auch Anbieter von Videokonferenzlösungen wie Zoom, BlueJeans oder HighFive. Die komplette Fokussierung auf die Cloud hat hier zu so großen Wettbewerbsvorteilen geführt, dass traditionelle Anbieter wie Cisco hiervon überrascht worden sind. Zoom gilt in seinem Bereich aus unserer Sicht heute als qualitativer Maßstab für den Markt. Und diese Qualität kann zu dramatisch niedrigeren Kosten geliefert werden. Wer hier nicht folgt, der geht unter. Für Cisco ist damit klar, dass so viele Dienste wie möglich in die Cloud müssen. Der Ausbau von Web-Ex und der Kauf von Broadsoft zeigen deutlich wohin der Markt geht. In die gleiche Richtung gehen Avaya und Unify.
Mit dieser Entwicklung haben sich gleichzeitig die Grenzen zwischen IaaS, PaaS und SaaS aufgeweicht und sind deutlich weniger klar. Damit muss auch die ursprüngliche eher skeptische Bewertung von IaaS neu überdacht werden. Wer heute Office 365 macht, der wird auch über Workflow-Automatisierung nachdenken und das mit einer intelligente Kopplung mit anderen Cloud-Anbietern verbinden. Wer Salesforce oder eine andere Cloud-basierte CRM-Lösung nutzt, wird eine Kopplung zum jeweils genutzten ERP-System suchen. Dabei müssen in der Regel neue Datenobjekte angelegt werden, Funktionen geändert oder neu geschrieben werden und entsprechende Kopplungen umgesetzt werden. Dies geht nicht ohne PaaS.
Um es auf den Punkt zu bringen:
- unsere Prognose ist an dieser Stelle, dass die Mehrheit aller deutschen Unternehmen in den nächsten drei Jahren in írgendeiner Form in der Cloud aktiv sein wird
- betrachten wir einen Zeitraum von 10 Jahren und beziehen die aktuellen Aktivitäten von Anbietern wie Oracle und SAP ein, dann werden auch komplexe Software–Lösungen aus der Cloud kommen
Damit kommen wir zu den Herausforderungen, vor denen Führungskräfte stehen, die ihr Unternehmen in die Cloud führen wollen. Diese sind
- technisch
- wirtschaftlich
- juristisch
Im technischen Bereich erfolgt der Weg in die Cloud häufig zu blauäugig. Es wird übersehen, dass eine signifikante und dauerhafte Infrastruktur benötigt wird, um diesen Weg zu gehen. Und diese Infrastruktur muss so gestaltet sein, dass sie in der Zukunft skaliert. Dienste wie Office 365 starten in der Regel harmlos, explodieren aber bei erfolgreicher Einführung innerhalb von 12 bis 18 Monaten im Bandbreitenbedarf. Wer versucht, solche Dienste mit alten und bestehenden Infrastrukturen zu fahren, wird diese Infrastrukturen zum Kollaps bringen. Auch darf diese Infrastruktur nicht Projektspezifisch für eine einzelne Anwendung sein. Sie muss eine wirkliche Infrastruktur sein, auf der alle Cloud-Zugänge des Unternehmens in Zukunft aufsetzen.
Dies bedeutet auf der technischen Seite, dass eine ganze Reihe von Themen abgedeckt werden müssen. Dies sind mindestens und ohne Anspruch auf Vollständigkeit:
- Bandbreite
- Latenz
- Sicherheit
- Benutzerverwaltung
- Reporting
- Betrieb und Trouble Shooting
Für Unternehmen mit mehreren Standorten wird es zum Beispiel normal sein, dass ein zentraler Internet-Zugang auf der Basis einen Corporate WAN aufgegeben und durch dezentrale Zugänge ersetzt wird. Wie man sich leicht vorstellen kann, ist der Betrieb einer damit verbundenen verteilten Firewall-Lösung deutlich aufwendiger als die Konzentration auf genau einen Zugang.
Das Latenz-Thema ist kritisch und je nach Anwendung auch umfangreich. Es reduziert sich nicht auf den eigenen Zugang zur Cloud. Dazu muss auch analysiert werden, wo das Gegenstück in der Cloud ist und wie man dahin kommt. In Abhängigkeit vom Bedarf kann das eine direkte Verbindung zu einem Cloud-Provider unter Umgehung des Internets erfordern. Der allgemeine Trend ist aber, dass die Cloud näher zu den Anwendern kommt. Ein Element dieser Entwicklung ist Edge-Computing, über das wir später noch sprechen werden.
Ein Thema, das in diesem Zusammenhang absolut kritisch ist, sind die juristischen Rahmenbedingungen der Cloud-Nutzung. Dies gilt nicht nur für Betreiber kritischer Technologien wie Krankenhäuser oder Stromerzeugung, sondern betrifft der DSGVO und dem Cloud Act der Amerikaner sei Dank nahezu jeden, der in die Cloud will. Vereinfacht ausgedrückt, kann man kaum noch vermeiden, in die Grauzone bestehender Gesetze zu geraten. Die gesammelte Inkompetenz, mit der hier Politiker das Leben der Unternehmen erschweren, lässt sich kaum noch überbieten (man hat hier wirklich das Gefühl, dass wir alle Vollidioten, die wir lokal für unerträglich halten nach Brüssel schicken, damit die dann dort ihr Unheil anrichten können). Sie können natürlich zum Füller und zum Papier zurückgehen und das Problem vermeiden. Wer aber Kollaboration, Videokonferenz oder auch nur Email nutzen will, der kommt bereits in diese Grauzonen. Und wollen Sie in Zukunft ERP-Lösungen von Oracle ausschließen, nur weil das ein amerikanischer Anbieter ist? Aus unserer Sicht besteht die Frage dann auch nicht darin, gar nichts zu tun, sondern eine Lösung zu schaffen, bei der man nachvollziehen kann, dass man bestimmte Probleme gesehen hat und versucht hat, diese zu minimieren. Im Rahmen der DSGVO sollte diese Dokumentation in den jeweiligen Verfahrenshandbüchern erfolgen. Und natürlich sollten absolute “No-Go” Bereiche wie WhatsApp, Facebook Messenger oder Snapchat auf Unternehmens-Smartphones vermieden und nachweislich unterbunden werden. Aus unserer Sicht ist BYOD mit der DSGVO gestorben. Sie müssen die komplette Kontrolle und Einbindung in entsprechend dokumentierte Verfahren über ein Gerät, das Anwendungen mit Personendaten nutzt (Email), sicherstellen.
Dieses juristische Thema ist komplex und die Suche nach einer Lösung erfordert detaillierte Kenntnisse über die Rechtslage. Wir haben deshalb eine Sonderveranstaltung zu diesem Thema im März aufgesetzt. Die Plätze sind hier begrenzt und wir empfehlen eine schnelle Buchung.
Auf der wirtschaftlichen Seite haben wir damit zu kämpfen, dass die Kunden glauben, die Cloud wäre umsonst oder preiswerter als bisherige Lösungen. Sprich, man würde viel Geld als Nebenwirkung der Cloud-Nutzung sparen.
Das ist für die Mehrzahl aller Fälle einfach zu beantworten, um auch an dieser Stelle jeden Zweifel zu vermeiden:
- Die Cloud ist in der Regel teurer als bisher
- Sie erfordert mehr und spezialisiertes Personal
- Sie erfordert einen intensiven Betrieb, der sich auch mit Themen wie Sicherheit auseinandersetzt
Damit sind wir bei der Aufgabenliste der Cloud:
- Es muss eine mittelfristige Perspektive aufgebaut werden, welche Cloud-Bereiche im Sinne von IaaS, PaaS und SaaS über alle Abteilungen des Unternehmens hinweg in den nächsten drei bis fünf Jahren zur Debatte stehen und wie diese zusammenhängen könnten
- Sie müssen mit der Hypothese arbeiten, dass Ihr Unternehmen in 10 Jahren komplett in der Cloud sein wird und Ihre Infrastrukturen auf diese Entwicklung vorbereiten
- Die juristischen Rahmenbedingungen sind schriftlich zu analysieren zu klären. Bestehende Konflikte wie Widersprüche zwischen europäischem Recht und dem Cloud-Act müssen dokumentiert werden
- Zur Einhaltung der juristischen Rahmenbedingungen muss es ein besonderes Verfahrenshandbuch zum Umgang mit der Cloud geben, dieses sollte als Teil des mittelfristigen Projekts und der juristischen Klärung entwickelt werden
- Es muss geklärt werden, wer die Cloud-Nutzung plant und später betreibt. Dazu muss ein Budget bereitgestellt werden, um die voraussichtlich über die Zeit steigenden Betriebskosten abzudecken. Es gibt erstaunlich große Projekte, in denen diese Mittel- und Personal-Bereitstellung vergessen wurde
- Es muss festgelegt werden was Basis-Infrastrukturen zum Cloud-Zugang sind und wie diese über die Zeit skalieren können
• Bandbreite
• Latenz
• Firewalls
• Spezielle Services wie Cloud-Security (ZScaler als Beispiel)
- Direktzugänge von Cloud-Anbietern wie Microsoft sind zu prüfen, dabei müssen auch Edge-Varianten der diversen Edge-Dienstleister berücksichtigt werden
- Eine Cloud-spezifische Zugangssystematik zur Cloud im Rahmen der Benutzerverwaltung muss umgesetzt werden
• MFA
• SSO
• Geräte-Sicherheit
• Standort-abhänge Konfiguration
- Der Betrieb muss vorbereitet werden
• Qualitätsdefinition
• Monitoring und Reporting
• Alarm-Handling, Reaktion auf Desaster-Situationen
- Ein umfassendes Sicherheitssystem muss aufgebaut werden. Die Cloud ist generell nicht mehr oder weniger sicher als eine lokale IT, aber sie erfordert eine Cloud-spezifische Sicherheitslösung, die aufwendig und teuer sein kann