
aus dem Netzwerk Insider Juli 2021
Seit geraumer Zeit gibt es immer wieder Schlagzeilen, dass im Rechenzentrumsumfeld neue Technologien entwickelt werden, welche den Betrieb, den Aufbau und die Steuerung auf eine Stufe heben, die mit den bisherigen Designs nicht erreicht werden kann.
Die Frage, die sich daraus ergibt, lautet also: Muss ich mich mit diesen neuen Ansätzen vertraut machen, oder an wen richten sich diese neuen Technologien?
Zu den häufigsten Begriffen, die hier immer wieder diskutiert werden, gehören:
- SONIC, SAI, P4
- Bare-Metal-Hardware
- SDN
- Layer-3-Design
Was ist die Triebfeder hinter diesen neuen Entwicklungen? Die Antworten hierauf möchte ich anhand der genannten Buzzwords erläutern.
Doch zunächst zur Motivation derer, die diese Techniken forcieren. Allen voran sind dies die Betreiber riesiger, vernetzter RZ-Plattformen wie Amazon, Microsoft, Google oder Facebook. Deren Hauptanliegen besteht in der Bereitstellung eines maximal flexiblen Netzdesigns, welches in der Lage ist, pro Rechenzentrum mehreren zehntausend physischen Rechnern eine Anschlussmöglichkeit zu bieten.
An erster Stelle muss man Petr Lapukhov nennen, der sowohl bei Microsoft als auch bei Facebook diesen Designansatz etablierte und bei der IETF den RFC 7938 federführend betreute. Dieser Ansatz verwirft den Einsatz von Layer-2-Technologien aus einem einfachen Grund: Die Broadcastdomäne wird auf ein Minimum beschränkt. Dafür wird konsequent ein Netzdesign favorisiert, welches Layer 3 bis auf die Ebene des ToR-Switches (Top of Rack) erzwingt. Hierbei wird ein BGP-Netz zum Aufbau einer sehr großen Layer-3-Fabric eingesetzt. Dieser Aufbau wird im genannten RFC 7938 – Use of BGP for Routing in Large-Scale Data Centers erläutert.
Hierzu erschien bereits im Netzwerk Insider vom Juli 2017 ein Artikel von mir, in dem sich die nachfolgende Abbildung 1 ebenfalls wiederfindet.
Wie im oben genannten Artikel erwähnt, dient der RFC 7938 folgenden Zielen:
- Unterstützung von Routing im RZ
- Skalierbarkeit durch ein Scale-Out-Design
- Unterstützung des Nord-Süd-Verkehrs zwischen Clients und Servern
- Die im RFC 7938 vorgesehene Architektur ist als Clos-Design bekannt, benannt nach Charles Clos, dem Erfinder einer ähnlichen Architektur für Telefonnetze, entwickelt in den 1950er Jahren in Bell Labs.
Das im EFC 7938 vorgesehene Design sieht den Einsatz von Top-of-Rack-(ToR-)Switches vor. „Diese ToR-Switche können bei Bedarf überbuchungsfrei an den Leaf angeschaltet werden.“
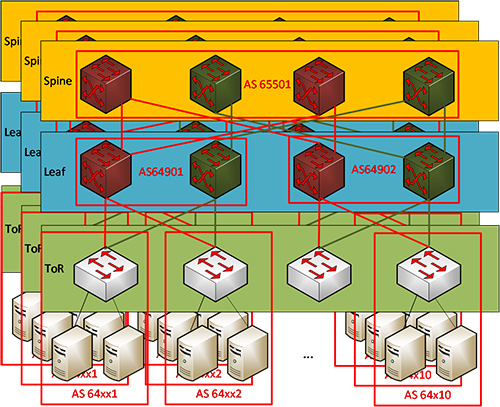
Abbildung 1: Spine-Leaf-Design
Warum sind Layer-2-Designs bei diesen Betreibern so verpönt?
Zum einen liegt es an der immensen Anzahl von Endpunkten, also Servern. Ein klassisches Netz mit VLAN und Spanning Tree führt in diesem Zusammenhang zu Netzen mit einem ungünstigen Broad- und Multicast-Verhalten. Wir wissen seit Jahrzehnten, dass zu viele Endgeräte in einer Broadcastdomäne zu einer Beeinträchtigung der Kommunikation, sogar bis hin zu einem Broadcaststurm führen, der jedwede Kommunikation unmöglich macht.
Ein weiterer Faktor sind die Layer-2-Mechanismen. Spanning Tree gilt bei der Fehlerumschaltung als sehr langsam. Rapid Spanning Tree behebt zwar diesen Mangel, doch auch dieses Verfahren bietet, wie sein Vorgänger, keine Lastverteilung, da es pro Netzsegment immer nur einen aktiven Pfad gibt.
Link Aggregation könnte in diesem Zusammenhang eine Alternative sein, zumal Multi-Chassis Link Aggregation (MC-LAG) bei allen großen Netzausrüstern zur Verfügung steht. MC-LAG ermöglicht die gewünschte Funktionalität des Equal Cost Multi-Pathing (ECMP), erfordert jedoch in der Distribution-Ebene den Einsatz von Switches desselben Herstellers. Das bedeutet, dass die Systeme, die das Multi-Chassis generieren, nicht frei wählbar bzw. kombinierbar sind.
Blieben noch die Verfahren Shortest Path Bridging (SPB) und Transparent Interconnect over Lots of Links (TRILL). Beide Lösungen bieten wie MC-LAC die geforderte Funktion der multiplen Wegewahl, können aber immer nur mit den Produkten desselben Herstellers oder gar bestimmten Produkten innerhalb eines Portfolios realisiert werden.
Dies führt uns zu einem weiteren wichtigen Punkt, der für die oben genannten großen RZ-Betreiber von Interesse ist: die Hersteller-Unabhängigkeit! Diese geht im Zweifelsfall soweit, dass die Firmen wie Facebook & Co. die verwendeten Netzwerkkomponenten nach eigenen Hardware-Designs fertigen lassen oder eben Bare-Metal-Lösungen einsetzen. Bare-Metal-Switche sind nach der Definition Switche, die ohne ein Betriebssystem von einem Hersteller vertrieben werden oder zumindest nicht an ein bestimmtes OS gebunden sind.
Als weiterer Begriff findet sich häufig der Name White-Box-Switches, da diese hauptsächlich aus Fabriken von No-Name-Herstellern stammen. Doch auch Markenhersteller verkaufen solche Systeme, die mit Betriebssystemen Dritter arbeiten können. Ebenso bieten die Produzenten der Ethernet-Chips selbst solche Switches an. Beispiele liefern Hersteller wie Broadcom, Intel oder Mellanox. Viele Anbieter im asiatischen Markt nutzen das Referenz-Design dieser großen Chip-Hersteller zur Entwicklung eigener Produkte, als Beispiel sei an dieser Stelle nur die Firma Accton erwähnt.
Wer jetzt aber glaubt, die hier eingesetzte Hardware wäre nicht State of the Art und würde sich am Mainstream orientieren, der sieht sich getäuscht.
Broadcom bedient an dieser Stelle alle seine gängigen ASICs. Angefangen bei Chips wie Helix oder Trident bis zum aktuellen Tomahawk, stehen alle Plattformen für einen solchen Bare-Metal-Switch zur Verfügung. Und die Leistungsdaten sind nicht ohne. Ein Trident3 ASIC bietet Unterstützung für bis zu 48x10G + 6x100G Ports, ein Tomahawk3 für bis zu 32x400G.
Andere Hersteller wie Cavium stellen mit der XPliantCNX880-Serie Chips zur Verfügung, die bis zu 32x100G unterstützen.
Und auch Intel hat entsprechend nachgelegt, indem man mit Barefoot einen führenden Ethernet-Chip-Hersteller übernommen hat. Deren Tofino-Chip-Design gilt als eines der modernsten am Markt, da es das reine ASIC-Design mit fest definierten Funktionen hinter sich lässt und eher als ein FPGA (Field Programmable Gate Array) zu verstehen ist. Dieser Chip-Typ bietet den großen Vorteil, in einem gewissen Rahmen frei programmierbar zu sein und somit die Möglichkeit bereitzustellen, an veränderte Parameter angepasst werden zu können. Eine Funktion, die klassische ASICs nicht bieten. Und auch hier sprechen die Leistungsdaten für den Chip. Bis zu 32x400G und eine Paketweiterleitungsrate von 12,8TB/s sind stolze Leistungsdaten.
Um dieses Feld zu bespielen, haben auch andere Chip-Hersteller Zukäufe getätigt. Allen voran Nvidia, die mit Mellanox ebenfalls einen der etablierten Chip-Anbieter übernommen hat.
Wohin die Reise führen wird, versteht man, wenn man sich die Studie von „Serve the Home“ ansieht. Demnach hat Facebook schon auf dem OCP Summit 2018 einen Switch vorgestellt, der 128x400G leisten soll: https://www.servethehome.com/intel-to-acquire-barefoot-networks-for-ethernet-switch-silicon/.
Diese Reise führt natürlich auch bei Herstellern wie Cisco zum Umdenken, die bisher nicht dafür bekannt waren, einen Switch ohne Software zu verkaufen. Seit der Einführung des Silicon-One-Chips haben sich auch hier die Zeiten geändert. Dieser wird in zwei Ausführungen, einer Q-Variante mit bis zu 12,8Tb/s und der G-Ausführung mit bis zu 25,6 Tb/s angeboten. Die Q-Lösung verfolgt dabei einen ähnlichen Ansatz wie der Tofino-Chip von Intel, wohingegen die G-Version eher als klassischer ASIC zu verstehen ist.
Treibende Kraft hinter all diesen Entwicklungen ist dabei das Open Compute Project (OCP). Es wurde 2011 auf Betreiben von Facebook, Intel, Rackspace, Goldman Sachs und vielen anderen ins Leben gerufen. Zielsetzungen des Projektes sind:
- die Reduzierung der Hardwarekosten um min. 24% sowie
- die Verringerung des Energiebedarfs um ca. 38%.
Definiert wurde der Aufbau einer RZ-Infrastruktur mittels „open standard, bare-metal hardware“.
Die aktuellen Projekte umfassen – mit Fokus auf DC Networking – folgende Themen:
- ONL (Open Network Linux)
- SONiC (Software for Open Networking in the Cloud)
- ONIE (Open Network Install Enviroment)
- SAI (Switch Abstraction Interface)
Begleitend gibt es noch einige Initiativen der Open Network Foundation (ONF). Diese wurde ebenfalls 2011 von Facebook, der Deutschen Telekom, Verizon und anderen Providern geründet und verfolgt ähnliche Ziele hinsichtlich der Nutzung von White-Label-Hardware und Open-Source-Software. Projekte dieser Gruppe sind unter anderem:
- OpenFlow
- P4
- ONOS
Da aber reine Hardware kein lauffähiges Netz ermöglicht, benötigt man zusätzlich noch die passende Software. Das führte bei Unternehmen wie Facebook oder Microsoft zu der Entscheidung, ein eigenes Betriebssystem für das Rechenzentrum zu entwerfen.
Seit 2016 arbeitet Microsoft an einem eigenen NOS (Network Operation System). Dieses ist, was seine Layer-3-Funktionen anbelangt, vergleichbar mit Cisco’s IOS. Die Entwicklungsdauer des NOS und der zugehörigen Schnittstellen dauerte ein Jahr – unter der Beteiligung von 10 Vollzeit-Software-Entwicklern. Das System basiert auf einem Debian-Kernel.
Dieses wurde auf den Namen SONiC (aka Azure Cloud Switch) getauft und findet weltweit immer mehr Zuspruch bei DC-Betreibern. SONiC kann, im Rahmen des Open Compute Project, als Open-Source-Lösung genutzt werden. Erste Nutzer der Lösung sind seit 2016 die Microsoft Azure Cloud und LinkedIn.
Mit der Zeit haben auch andere Cloud-Anbieter wie Alibaba oder Tencent dieses NOS in ihren Rechenzentren etabliert. Die Hardware-Unterstützung ist dabei sehr umfangreich. Erste Projektpartner waren von Anfang an:
- Dell
- Broadcom
- Mellanox
- Nvidia
- Intel (Barefoot)
ASIC-Hersteller wie Broadcom, Mellanox oder Barefoot stellen hierfür mit SAI eine Schnittstelle zur Verfügung. Dieses Switch Abstraction Interface, eine in C geschriebene API, wird genutzt, um die Daten an einen Switch zu übergeben. SAI wird auch von SONiC genutzt, um die Funktionen anwendbar zu machen. Im Zuge dieser Entwicklung haben auch erste Internet Service Provider Fallstudien für die Nutzung von SONiC in Auftrag gegeben. Hauptanliegen dabei ist die Trennung von Control und Data Plane. Bei herkömmlichen Lösungen, egal ob Router oder Switch, liegen diese lokal auf jedem Gerät.
Im Rechenzentrum der Zukunft wird jedoch auf eine Trennung der beiden hingearbeitet. Dies endet dann zwangsläufig in einer SDN-Struktur. Software-Defined Networking besagt im Kern, dass logische Netzstrukturen auf Software-Basis realisiert werden. SDN im engeren Sinne zentralisiert die Steuerung des Netzes auf sogenannten Controllern.
Ähnlich wie bei modernen WLAN-Umgebungen, wo ein Controller mehrere Access Points verwaltet, wird im RZ der Zukunft ein Controller die FIB (Forwarding Information Base) für alle Layer–2- und Layer-3-Entscheidungen berechnen und verwalten und diese dann an die Switche und Router verteilen. Dabei können diesem Controller administrative Vorgaben gemacht werden, wie eine solche FIB aufgebaut werden soll und wie die Einträge zustande kommen. Mittels des SAI können die Ergebnisse dieser Berechnungen dann an den lokalen Netzwerkknoten übergeben werden, oder mittels P4 zur Ausführung gebracht werden.
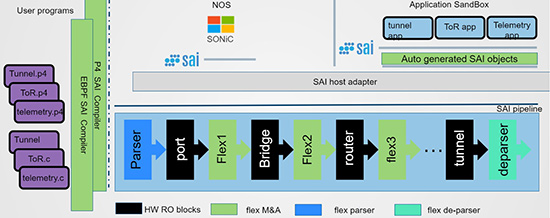
Abbildung 2: P4 Funktionsweise;
Quelle: https://github.com/Azure/SONiC/blob/gh-pages/doc/SAIf2f_SAI_programablity_4.pdf
Im April 2018 bin ich in meinem Artikel auch auf P4 eingegangen. P4 steht für Programming Protocol-Independent Packet Processors. Nachfolgend sind die wichtigsten Informationen zu P4 aufgeführt:
- P4 ist eine Programmiersprache und Laufzeitumgebung für Netzkomponenten.
- Bei P4 steht Hardware-Unabhängigkeit im Vordergrund.
- P4 soll für verschiedene Prozessoren und Chips genutzt werden.
- Mittels einer Programmierschnittstelle werden Administration und Konfiguration von Netzkomponenten standardisiert.
An SAI wird seit 2015 gearbeitet. Es wurde ebenfalls von Microsoft entwickelt und eingeführt, um einem NOS mittels einer definierten Schnittstelle die Möglichkeit zu geben, mit einem ASIC eines beliebigen Herstellers zu kommunizieren. Zu diesem Zweck werden vom ASIC-Hersteller SDK‘s und Treiber für das NOS zur Verfügung gestellt. Da die führenden NOS in der Regel auf Linux oder Debian basieren, ist dies leicht zu bewerkstelligen. Das SAI nutzt nun die Einbindung der Hardware ins Betriebssystem, um Informationen an das ASIC zu übergeben, die z.B. durch eine Routing-Anwendung wie Quagga oder GoBGP berechnet werden.
Die hier geschilderten Technologien sind zugegebenermaßen noch eine recht junge Entwicklung, was jedoch nicht bedeutet, dass sie keine Anwendung finden. Sowohl die Rechenzentren von Google wie auch von Facebook basieren auf den geschilderten Verfahren. Google nutzt P4 sehr intensiv, um seine Infrastrukturen zu steuern und zu administrieren. Betriebssysteme wie FBOSS (Facebook Open Switch System), Cumulus oder BigSwitch basieren auf einem Standard-Linux-Kernel.
Letztendlich geht es bei den vorgestellten Verfahren um eine Vereinfachung und Automatisierung des Netzes. Verfahren für IMAC (Install, Move, Add & Change) sollen beschleunigt werden. Die Bereitstellung einer Ressource, egal ob Server, Storage oder NVF-Dienst, soll mit der Eingabe „eines“ Parametersatzes komplett realisiert werden können, ohne dass, wie so oft, mehrere Fachabteilungen involviert sind, um die einzelnen Arbeitsschritte umzusetzen.
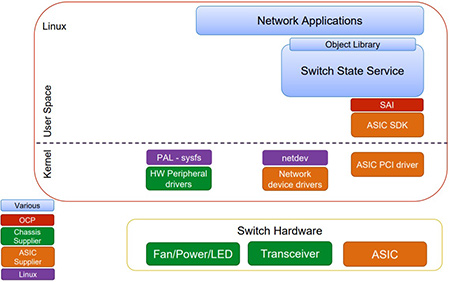
Abbildung 3: SAI als Schnittstelle zwischen NOS und Hardware;
Quelle: https://github.com/Azure/SONiC/wiki/SAI-SONiC-OCP-Summit-Mar16-share.pdf
Dabei ist entscheidend, dass man hierfür mittels Linux-Scripte sowohl den Betrieb der Server als auch des Netzes beherrschen kann. Es besteht in diesem Kontext nicht mehr die Notwendigkeit, auf die Managementschnittstellen einzelner Hersteller Rücksicht zu nehmen oder sich nach proprietären Verfahren zu richten.
Dies führt immer zu der Erkenntnis, dass große RZ-Betreiber den Einfluss einzelner Systemhersteller minimieren wollen. Im Idealfall ist dabei eine ausgefallene Hardware durch irgendein – technisch jedoch gleichwertiges – Produkt zu ersetzen, sodass Abhängigkeiten gar nicht erst entstehen können. Der Netzwerk- und Serverausrüster wird somit zu einem beliebigen Komponentenlieferanten.
Bleibt die Frage: Bin ich als Anwender, der ein RZ betreibt, von dieser Entwicklung betroffen?
Aktuell wohl eher nicht, da diese Lösungen explizit von und für Hyperscaler entworfen wurden. Langfristig wird man allerdings auch als normaler RZ-Betreiber profitieren, da Produkte und Funktionen vergleichbarer werden und der Wettbewerb somit belebt wird. Dies bringt naturgemäß eine bessere Verhandlungsposition sowie bessere Marktpreise mit sich.
Zudem wird es für Netzwerkanbieter immer schwieriger, dem informierten Kunden eine Lösung zu verkaufen, die final in einem Vendor-Lock-in endet. Daher bleibt es weiterhin spannend, auch diese Technologien zu verfolgen, da sie zukünftig zu neuen Marktteilnehmern führt. Die Zeit der „Closed-Shop“-Systeme neigt sich somit langsam, aber sicher, dem Ende entgegen.



Kontakt
ComConsult GmbH
Pascalstraße 27
DE-52076 Aachen
Telefon: 02408/951-0
Fax: 02408/951-200
E-Mail: info@comconsult.com