Cookies zum Tracking von Benutzeraktivitäten im Internet geraten immer mehr in die Defensive.
Der Bundesgerichtshof (BGH) hat mit einem weiteren Urteil zu Cookies festgestellt, dass jede Art des Benutzer-Trackings der vorherigen aktiven Zustimmung des Benutzers bedarf. Vorausgefüllte Formulare, Häkchen oder die lapidare Feststellung „Mit der Nutzung dieser Website stimmen Sie … zu.“ genügen nicht.
Wir diskutieren in diesem Artikel, wozu Cookies gebraucht werden, wie Benutzer-Tracking funktioniert, welche alternativen Formen des Trackings neben Cookies heutzutage genutzt werden und welche Auswirkung das BGH-Urteil auf das Design von Webseiten hat.
Wieder einmal hat sich der Bundesgerichtshof zu Rechtsgrundsätzen in Zusammenhang mit der Nutzung von Cookies auf Webseiten geäußert. Das Urteil vom 28.5.2020 [1] bekräftigt die bisherige strenge Auslegung des BGH und basiert auch auf der Rechtsauffassung des Europäischen Gerichtshofs, den die Karlsruher Richter zuvor konsultiert hatten. Kern der Entscheidung ist, dass die Einwilligung des Nutzers zum Setzen von Cookies auf seinem Rechner nur dann wirksam ist, wenn
- der Verbraucher weiß, dass seine Erklärung ein Einverständnis darstellt und
- er weiß, worauf sich sein Einverständnis im konkreten Fall bezieht.
Insofern sei die „Einwilligung … im Wege eines voreingestellten Ankreuzkästchens … eine unangemessene Benachteiligung des Nutzers“, wie es in der Pressemitteilung zu dem Urteil heißt.
Genauso sei es unzulässig, eine Einwilligung in einem anderen Zusammenhang wie beispielsweise einem Gewinnspiel einzuholen oder den konkreten Zweck und Umfang der Einwilligung hinter nachgelagerten Informationsseiten zu verschleiern (siehe zum Beispiel die Abbildungen 1 und 2)
Leider wird mit dem Urteil wieder einmal ein vornehmlich technisches Werkzeug wie Cookies mit dem berechtigten politischen Willen, Benutzerdaten und deren Surfverhalten vor Ausspähung zu schützen, gleichgesetzt. Das verwirrt aber den Markt und die Betreiber von Webseiten mehr, als dass es zur Rechtssicherheit beiträgt.
Hintergrund
Tatsächlich sind Cookies im Grunde eher harmlos: Sie werden auf den Endgeräten der Nutzer platziert und können daher durch den Nutzer und durch die Internet-Browser auf den Endgeräten vollständig kontrolliert werden. Trotzdem wissen viele nicht, was Cookies konkret sind und wie sie genutzt werden. Weitverbreitet ist die Erklärung aus vielen Datenschutzerklärungen: „Cookies sind kleine (manchmal auch winzige) Textdateien …“. Schon dieser Halbsatz führt in die Irre und ist in vielen Fällen auch noch schlicht falsch.

Abbildung 1: Nutzereinwilligung: die Friss- oder Stirb-Methode
Cookies sind sogenannte Key-Value-Paare, also Variablen, denen ein Wert zugewiesen wird wie beispielsweise „UserId = 4711“, und Teil des HTTP-Protokolls. Sie sind erfunden worden, um auf eine sichere Art und Weise Daten einer Website auf der Seite des Clients zu speichern. Cookies können bis zu 4096 Bytes umfassen, also ca. 1,5 Seiten Text. Die gespeicherten Cookies sind jeweils „ihrer“ Website, also die, die sie geschrieben hat, fest zugeordnet und werden in der Folge mit jeder Anfrage des Clients an diese Website zurückgesendet.
Auf diese Art und Weise ist sichergestellt, dass nur die Website (Domäne), die die Daten geschrieben hat, sie auch wieder lesen kann. Es gibt keine Möglichkeit, Cookies einer dritten Website auszulesen.
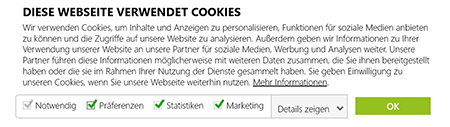
Abbildung 2: Nutzereinwilligung: Wer’s eilig hat, muss alles akzeptieren
Wie und wo die Cookies gespeichert werden ist allerdings nicht spezifiziert und hängt vom Browser ab. Das können Textdateien sein, Googles Chrome speichert aber Cookies beispielsweise in einer einfachen SQL-Datenbank.
Cookies werden klassischerweise in drei Szenarien genutzt:
- für sogenannte Sessions zur Verwaltung von Logins, Warenkörben etc.,
- zur Personalisierung von Webseiten (Farbgestaltung, letzter verwendeter Benutzername etc.) und
- zum Tracking des Benutzerverhaltens.
Hierfür ist es wichtig zu wissen, dass HTTP ein sogenanntes verbindungsloses Protokoll ist, das heißt, aus der Sicht des Webservers kommt jede neue Anfrage von einem ihm unbekannten Client. Der Webserver „weiß“ vom Konzept her nicht, ob der Benutzer sich auf der vorherigen Seite erfolgreich angemeldet oder ein bestimmtes Produkt in seinen Warenkorb gelegt hat. Um solche Funktionen umsetzen zu können, musste man also eine Art „Erinnerungsfunktion“ schaffen, damit der Server erkennt: „Diese Anfrage (z. B. „Zeige mir meine hinterlegten Profildaten an“) kommt von dem mir bekannten Client XY und muss daher anders behandelt werden als die gleiche Anfrage von einem anderen Client.“
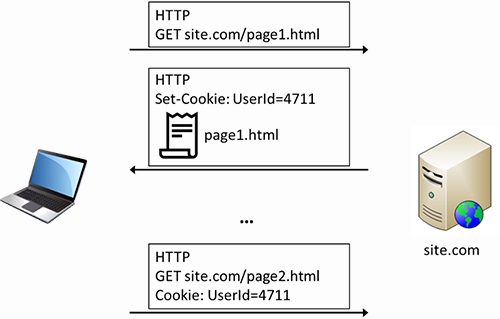
Abbildung 3: Funktionsweise von Cookies
Cookies realisieren eine solche Erinnerungsfunktion, indem der Server dem Client beispielsweise seine Kundennummer mitteilt und der Client bei jeder weiteren Kommunikation ein Cookie der Art „übrigens ich bin der mit der Kundennummer 4711“ an den Server mitschickt.
Session-Cookies
Allerdings sind gerade solche sicherheitskritischen Konzepte wie Login oder Warenkorb für die Nutzung klassischer Cookies eher ungeeignet. Cookies kann man nämlich leicht fälschen, daher wird geraten, sensible Informationen wie Passwörter oder Zahlungsdaten darin nicht zu speichern. Darüber hinaus ist es ineffizient, einen gesamten Warenkorb permanent hin- und herzuschicken.
Statusinformationen wie „Der Benutzer hat sich als XY authentisiert.“ oder „Der Benutzer hat einen Warenkorb 123 angelegt.“, auf denen solche Anwendungen basieren, sind meist ohnehin nur in einem mehr oder weniger engen zeitlichen Rahmen sinnvoll.
Es ist daher auch nicht zweckmäßig, solche Daten in Form eines Cookies auf der Festplatte zu speichern. Stattdessen werden hierfür sogenannte Session-Cookies verwendet. Für ein Session-Cookie wird üblicherweise zu Beginn der Sitzung eine aus Sicherheitsaspekten genügend lange, zufällige Session-ID generiert, die der Server dem Client als Cookie mitteilt und die der Browser ab dann bei jeder Anfrage mitschickt.
Diese ID ist nur für die Dauer der Internetsitzung gültig, sie trägt selbst keinerlei Informationen und kann (aufgrund ihrer Länge) auch nicht erraten oder probiert werden. Die eigentlichen und sitzungsrelevanten Daten wie der Inhalt des Warenkorbs oder der Login-Status des Benutzers bleiben auf dem Server und werden dort anhand der Session-ID identifiziert und der jeweiligen Kommunikation zugeordnet. Die Besonderheit bei diesem Vorgehen: Das Session-Cookie wird auf der Clientseite nur im flüchtigen Programmspeicher des Browsers verwaltet und die zugehörigen Datenstrukturen werden auf der Serverseite zeitgesteuert gelöscht. Damit sind die kritischen Daten nach einem Time-Out oder spätestens nach dem Neustart des Browsers weg, der Benutzer muss sich neu anmelden, sein Warenkorb ist leer und er muss mit einer neuen Sitzung neu beginnen.
Als Nichtjurist fällt es mir ehrlich gesagt schwer nachzuvollziehen, warum diese Nutzung von Cookies unter die Einschränkungen der DSGVO und der Zustimmung der Benutzer fallen soll. Auf Clientseite wird lediglich für eine kurze Zeit eine zufällige ID gespeichert. Alle anderen, gegebenenfalls kritischen Daten wie Benutzername, Passwort, Kontakt- und Zahlungsdaten liegen auf der Gegenseite vor. Der Speicherung und Verarbeitung dieser Daten muss gegebenenfalls zugestimmt werden, aber das hat nichts damit zu tun, dass die Session-ID je nach Implementierung – und noch nicht einmal notwendigerweise – über den Cookie-Mechanismus von HTTP zwischen Client und Server ausgetauscht wird. Sitzungsübergreifende Informationen können mit Session-Cookies nicht nachverfolgt werden.
Dass aber der einzelne Webshop zurückverfolgen kann, dass ein Kunde letzte Woche Produkt A und heute Produkt B gekauft hat, und daraus gegebenenfalls Konsequenz für sein Marketing zieht, liegt in der Natur des Geschäftsverhältnisses zwischen Kunde und Webshop und ist durch die DSGVO gedeckt und gerade nicht zustimmungspflichtig.
Tracking-Cookies
Klassische und dauerhaft beim Client gespeicherte Cookieswerden daher in erster Linie dazu genutzt, den Benutzer nachzuverfolgen und sein Surfverhalten aufzuzeichnen.
Das prinzipielle Vorgehen bei diesem Tracking ist ähnlich wie gerade beschrieben: Der Server generiert einmalig eine eindeutige ID, die der Client ab dann bei jedem Zugriff mitschickt. Der Server kann dann jeden Zugriff, jeden Klick, die Zeitdauer, die Sie auf einer Seite bleiben etc. dieser ID zuordnen und damit auch unabhängig von einem Login analysieren, wie sich einzelne Besucher auf seiner Site bewegen, wofür sich der Nutzer interessiert, auf welchen Seiten er länger verweilt, welche Seiten er schnell verlässt etc.
Der entscheidende Unterschied zu den kurzlebigen Session-Cookies ist, dass die hier generierte ID beim Client erhalten bleibt. So kann das Nutzerverhalten nicht nur während einer Sitzung analysiert werden, sondern über Tage, Wochen und sogar Monate hinweg. Was hierbei oft übersehen wird: Wenn Sie sich einmal auf einer solchen Website identifiziert haben, weil Sie z.B. einen Newsletter abonniert, ein Kontaktformular ausgefüllt oder eine Bestellung ausgelöst haben, ist die zunächst anonyme ID, die bis dahin „nur“ einem bestimmten Endgerät (genauer einem Browser) zugeordnet war, auf der Serverseite jetzt mit Ihrer echten Identität verbunden. Unddies solange, wie das Cookie auf Ihrem Endgerät erhalten bleibt.
Die Erkenntnisse über Ihr Surfverhalten, Ihre Interessen etc., die die Gegenseite so Ihrer echten Identität zuordnen konnte, können jetzt browser- und endgeräteübergreifend zusammengeführt und ausgewertet werden. Diese Daten gehen nicht verloren, nur weil Sie auf Ihrer Seite ein paar Cookies löschen.
Wenn dies nun eine einzelne Site quasi für den eigenen Hausgebrauch macht, ist das unter Datenschutzaspekten schon schwierig genug zu akzeptieren. Immer wieder aufgeführte Begründungen wie „Dadurch können wir ermitteln, welche unserer Artikel beliebt sind“ oder „So können wir das Angebot auf unserer Webseite attraktiver gestalten“ sind nichts als Schutzbehauptungen. Benutzerunabhängige Analysen kann jeder Webseitenbetreiber anhand der Logfiles seines Servers erstellen. Dafür braucht man keine Cookies. Bei solchen Tracking-Cookies geht es immer um den individuellen Benutzer.
Es gibt einige wenige Szenarien, in denen solche permanenten Cookies nicht für ein Tracking im engeren Sinn verwendet werden. Ein typisches Beispiel ist die in diesen Tagen wieder weitverbreitete Abfrage, ob Sie Cookies zustimmen. Denn Ihre Antwort auf diese Frage wird vielfach ihrerseits in einem Cookie gespeichert, selbst dann, wenn Sie Ihre Zustimmung zum Setzen von Cookies verweigert haben. Der Hintergrund ist, dass die Website so Ihre Antwort speichern kann und Sie zukünftig nicht erneut um Ihre Zustimmung bittet (bitten muss). Das klingt einleuchtend, ist aber im Grunde nichts anderes als eine etwas mildere Form des User-Trackings. Warum muss die Website wissen, dass ich das Setzen von Cookies abgelehnt habe. Sinnvoller im Sinne des Datenschutzes wäre es, wenn mein Browser sich das merken und Cookies von dieser Website zukünftig einfach ignorieren würde.
Websites bezeichnen solche Cookies übrigens gerne als „notwendig“.
Third-Party-Cookies
Richtig hinterhältig wird es, wenn diese Überwachung server- beziehungsweise domänenübergreifend erfolgt und die Erkenntnisse über eine Person bei den großen Social-Media-Providern und großen Werbenetzwerken zusammengeführt werden.
Wie funktioniert diese serverübergreifende Überwachung, wenn wir oben doch festgestellt haben, dass nur der Server, der ein Cookie gesetzt hat, dieses auch wieder auslesen kann?
Der Trick klappt, wenn Webseitenbetreiber fremden Code wie beispielsweise Werbeblöcke, Social-Media-Plugins oder vermeintlich hilfreichen JavaScript-Code auf ihren Webseiten einbetten. Dieser fremde Code wird dann von einer dritten Seite geladen. Diese dritte Seite hat damit die Möglichkeit, eigene Cookies beim Client zu platzieren – und diese Cookies können entsprechend auf anderen Seiten, die ebenfalls HTML-Code, Bilder oder Scripts vom selben Anbieter eingebettet haben, von ihm dann auch wieder ausgelesen werden. Unabhängig von den Sites, die der Benutzer augenscheinlich gerade besucht! Da solche Cookies nicht von der besuchten Webseite selbst, sondern von dritter Seite gesetzt werden, spricht man hier von Third-Party-Cookies. Das folgende Beispiel soll die Funktionalität beleuchten:
Nehmen wir als Beispiel eine Website XY mit der URL www.xy.com. Die Website finanziert sich über Werbung und lädt dynamisch Werbeblöcke eines Werbeanbieters. Dies geschieht beispielsweise über ein iFrame-Tag . Der Client, der beispielsweise die Seite http://www.xy.com/produkt-1.html besucht, lädt infolgedessen nicht nur das Dokument produkt-1.html von www.xy.com, sondern eben auch das Dokument ad.html von anbieter.com. In seine Antwort kann daher anbieter.com einen Set-Cookie-Header integrieren und ein eigenes Cookie beim Client setzen lassen (siehe Abbildung 4).
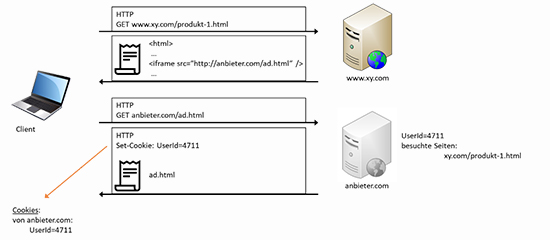
Abbildung 4: Third-Party-Cookies (Schritt 1)
Besucht derselbe Client jetzt Tage, Wochen oder auch Monate später eine andere Webseite, die ebenfalls Werbung von anbieter.com eingebettet hat, dann wird der Client bei seiner Anfrage an anbieter.com das gesetzte Cookie mitliefern und schon weiß der Werbeanbieter, dass der Nutzer vorher bei www.xy.com war, und kann auf der aktuellen Seite angepasste Werbung für den Benutzer schalten (siehe Abbildung 5).
Verschiedene weitere Tricks komplettieren hierbei den Informationsfluss zum Drittanbieter. So weiß der Werbeanbieter zwar im einfachsten Fall zunächst einmal nicht, von welcher Seite die Anfrage für den Werbeblock kommt. Hierüber gibt aber beispielsweise der Referer-Header der HTTP-Anfrage Auskunft, den die meisten Webbrowser regelmäßig mitschicken. Alternativ individualisieren viele Anbieter den eingebetteten Code-Schnipsel, so dass sie zumindest ihren Kunden und damit die Website erkennen. Wird JavaScript eingebettet, kann auch darüber der Link zum Werbeanbieter dynamisch so angepasst werden, dass der URL der übergeordneten Seite direkt mitübergeben wird.
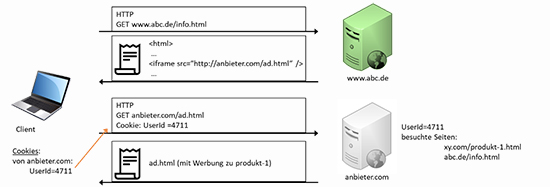
Abbildung 5: Third-Party-Cookies (Schritt 2)
Spannend sind in diesem Zusammenhang auch Aussagen in Datenschutzerklärungen wie „Wir arbeiten mit verschiedenen Werbepartnern zusammen …“ oder noch deutlicher „Wir geben Informationen … an unsere Partner weiter …“. Bei solchen Sites müssen Sie damit rechnen, dass auch Ihre Identität wie beispielsweise Ihre E-Mail-Adresse, die Sie über ein Kontaktformular an die besuchte Webseite schicken, gleichzeitig auch an die Werbeanbieter weitergegeben werden.
Die Zukunft des Trackings
Da gerade Third-Party-Cookies seit Jahren nahezu ausschließlich für das Tracking von Benutzern verwendet werden, haben sie einen entsprechend schlechten Ruf. Die DSGVO und immer strengere Datenschutzgesetze weltweit tun hierzu ihr Übriges. Der Widerstand gegen Third-Party-Cookies ist mittlerweile so groß geworden, dass ihr Ende so gut wie ausgemacht scheint.
Firefox blockiert schon seit 2019 (konkret seit der Version 70) per Default „bekannte“ Third-Party-Cookies im Rahmen der integrierten Anti-Tracking-Funktion („Enhanced Tracking Protection“, siehe https://blog.mozilla.org/press-de/2019/09/03/firefox-69-blockiert-standardmaessig-tracking-cookies-von-drittanbietern-und-cryptomining/). Firefox kombiniert hier den Schutz vor Trackingelementen mit dem Schutz vor Malware, blockiert aber in der Standardeinstellung dann doch bei weitem nicht alle Third-Party-Cookies.
Einen deutlichen Schritt weiter ist Apple gegangen. Apples in Safari integrierte Technologie „Intelligent Tracking Protection“ (ITP) blockiert schon seit einigen Jahren immer mehr Third-Party-Cookies. Mit der Version 13.1 von Safari und der Version 13.4 von iOS werden seit April 2020 diese Cookies vollständig blockiert. Darüber hinaus identifiziert ITP mit Hilfe von Machine-Learning-Techniken auch First-Party-Cookies, die zum Benutzer-Tracking genutzt werden, und löscht alle anderen First-Party-Cookies nach 7 Tagen Inaktivität, das heißt, wenn die Cookies seit 7 Tagen nicht genutzt wurden.
Google hatte für den Chrome-Browser ähnliche Schritte angekündigt, dann aber Anfang des Jahres einen Rückzieher gemacht. Als neue Zielvorgabe gibt Google jetzt an, spätestens ab 2022 keine Third-Party-Cookies mehr unterstützen zu wollen. Laut Google würden nämlich übereilte Ansätze das Geschäftsmodell vieler werbefinanzierter Websites untergraben. Gemeint ist wohl in erster Linie das eigene Geschäftsmodell: Bereits 2019 bezeichnete der Mutterkonzern Alphabet im Jahresbericht an die US-Börsenaufsicht Werbeblocker als direkte Bedrohung („Most of our Google revenues are derived from fees paid to us in connection with the display of ads online. As a result, such technologies and tools could adversely affect our operating results.“ – siehe https://www.sec.gov/Archives/edgar/data/1652044/000165204419000004/goog10-kq42018.htm).
Google, wie letztlich die gesamte Online-Werbeindustrie, hat also ein Problem: Es müssen immer striktere Richtlinien zum Schutz der Privatsphäre umgesetzt werden, und gleichzeitig wird das Geld durch Klicks auf die platzierte Werbung verdient (und nicht etwa durch die eingeblendete Werbebox allein). Das heißt, es ist für die Branche essenziell, dass die richtige Werbung dem richtigen Benutzer gezeigt wird, der sich tatsächlich dafür interessiert. Daher wird derzeit kräftig an Alternativen gefeilt, um Third-Party-Cookies und die technischen Einschränkungen der Browser zu umgehen. Und hiervon gibt es viele, sehr viele:
- Nutzung von First-Party-Cookies:
First-Party-Cookies werden von vielen Websites eingesetzt, um angeblich notwendige Funktionen umzusetzen. Sobald man zwischen persistenten Cookies und temporären Session-Cookies unterscheidet, relativiert sich die angebliche Notwendigkeit von permanenten Cookies deutlich. Trotzdem werden First-Party-Cookies von den meisten Browsern nicht behindert.Daher tarnen einige Werbenetzwerke gerade zur Unterstützung großer Kunden ihre Aktivität über First-Party-Cookies. Dies funktioniert durch die Nutzung von DNS-ALIAS oder DNS-CNAME-Einträgen. Das heißt, der fremde Code wird über eine vermeintliche Subdomain (z.B. adnet.firma.com) der besuchten Webseite geladen, der DNS-Eintrag verweist aber weiterhin auf die fremden Server des Werbeanbieters. Trotz First-Party-Cookie gelingt so trotzdem ein Informationstransfer zur fremden Site – mehr noch, das Skript der vermeintlichen Subdomain hat unter Umständen sogar Zugriff auf die echten First-Party-Cookies der besuchten Site, wo eventuell personenbezogene Daten gespeichert sind.
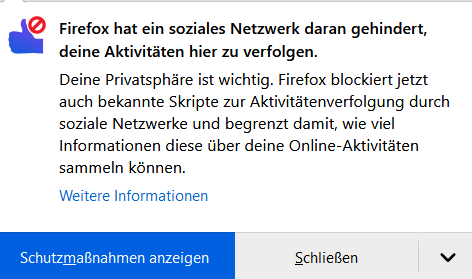
Abbildung 6: Meldung von Firefox über blockierte Social-Media-Skripte
- Nutzung der HTML5 Web Storage API:
Seit HTML5 gibt es neue Konzepte wie localStorage und sessionStorage, um Daten auf der Clientseite abzulegen. Mit Hilfe dieser Funktionen können insbesondere deutlich mehr Daten gespeichert werden als die vier KBytes, die ein Cookie enthalten kann. Gleichzeitig entfällt der automatische Austausch der Daten bei jedem Kommunikationsschritt.Trotzdem können localStorage und sessionStorage prinzipiell für die gleichen Tracking-Strategien genutzt werden wie Cookies.
- Fingerprinting:
Beim sogenannten Fingerprinting werden technische Merkmale des Endgeräts genutzt, um den Browser des Besuchers eindeutig identifizieren zu können. Hierzu sammelt ein JavaScript möglichst viele Informationen wie beispielsweise:
- die Browser-Software und deren Version,
- das Betriebssystem des Clients und seine Version,
- den Typ des Endgeräts,
- Landes- und Spracheinstellungen,
- die Zeitzone,
- die Auflösung und Farbtiefe des Bildschirms,
- die eingestellte Helligkeit,
- installierte Schriftarten,
- installierte Browser-Plug-ins
- u. a. m.Die gesammelten Daten werden dann in der Regel über ein Hash-Verfahren zusammengeführt, und der berechnete Hash als eindeutige Kennung an den Server übermittelt.
Fingerprinting ist momentan tatsächlich eine der größten Baustellen für den Datenschutz. Im Vergleich zum Tracking mit Cookies funktioniert die Methode praktisch immer, solange JavaScript erlaubt ist, selbst im privaten Surfmodus, und kann auch nicht durch Do-Not-Track, AdBlocker oder das Löschen von Cookies behindert werden.
- Übergreifende Logins
Eine weitverbreitete Funktion zum vereinfachten Login auf Websites ist sogenanntes Single Sign-On (SSO). Hierbei wird der Login-Request beim Zugriff auf eine geschützte Ressource wie beispielsweise ein Whitepaper vom Anbieter zu einem dritten sogenannten Identity-Provider umgeleitet. Dieser übernimmt die Authentisierung des Besuchers und beglaubigt dessen Identität gegenüber der besuchten Website. Diese Komfortoption – der Benutzer muss sich für die besuchte Site keinen eigenen Benutzernamen und kein separates Passwort merken, sondern erhält mit einer einzigen Identität Zugriff auf unterschiedliche Websites – kann natürlich auch zum Tracking missbraucht werden. Sie kennen vermutlich Login-Optionen wie „Melden Sie sich mit Ihrer Facebook-ID oder Ihrem Google-Account an“. Damit verknüpfen Sie aber ganz offensichtlich Ihre Social-Media-Identität beispielsweise mit Ihrer Pizza-Bestellung: Facebook weiß dann, wo und wann Sie Ihre Pizza bestellt haben und wird dies bekanntermaßen in Ihrem Profil aufzeichnen. Aber auch Ihr Lieferant kennt damit Ihre Facebook-ID, die Sie ja eindeutig identifiziert, und kann diese ID zum Beispiel mit herkömmlichen Cookies nutzen, um Sie bei späteren Besuchen wiederzuerkennen.Hiervon profitieren natürlich vor allem Social-Media-Netzwerke wie Facebook, Google u.a., da viele, wenn nicht die meisten, Benutzer einen User-Account bei zumindest einem dieser großen Netzwerke haben. Die Verlockung ist groß, diesen Account dann zum schnellen Login zu nutzen, ohne sich neu anmelden oder registrieren zu müssen.Eine oft übersehene Funktion in diesem Zusammenhang ist, dass ein Browserfenster über alle Tabs hinweg eine gemeinsame Session realisiert! Das heißt, wenn Sie sich in nur einem Tab bei einer bestimmten Website oder Netzwerk anmelden, dann sind Sie automatisch in allen anderen Tabs dort ebenfalls angemeldet – und dieser Status bleibt erhalten, selbst wenn Sie die Website schon längst wieder verlassen haben ohne sich abzumelden.Auch hiervon profitieren vor allem die großen Social-Media-Netzwerke. Die in vielen Webseiten eingebundenen Like- und Share-Buttons oder ähnliche Plug-Ins sind zunächst nichts anderes als von fremden Sites eingebundener Code. Sie funktionieren damit wie oben beschrieben, setzen in der Regel tatsächlich auch eigene Third-Party-Cookies und übertragen Informationen über Ihr Surfverhalten an das Heimatnetzwerk – im Übrigen unabhängig davon, ob Sie darauf klicken oder nicht!
Der wichtige Unterschied kommt dann aber zum Tragen, wenn Sie in Ihrem Netzwerk bereits angemeldet sind – was die meisten Nutzer von Facebook und Co. die meiste Zeit über sein dürften, weil sie beispielsweise irgendwann auf einen Like-Button geklickt und sich angemeldet haben. Damit sind Sie Ihrem Netzwerk nämlich mit Ihrer persönlichen Identität bekannt. Jetzt funktioniert Ihre Überwachung nicht nur tab- sondern sogar geräteübergreifend! Third-Party-Identifizierungs-Cookies, deren Nutzung Sie vielleicht sogar widersprochen haben, brauchen diese Provider dann nicht, da Sie sich in deren Netzwerk angemeldet haben und die (übergreifende) Session genügt völlig, um Sie zu identifizieren.
- Authentication Cache
Auch das HTTP-Protokoll selbst verfügt über Möglichkeiten, den Zugriff auf Server-Ressourcen zu schützen. Der Server antwortet in diesem Fall mit einem WWW-Authenticate-Header, und der Browser fordert den Benutzer auf, seine Zugangsdaten, im einfachsten Fall Benutzername und Passwort, einzugeben, die er an den Server übermittelt. Damit bei nachfolgenden Zugriffen auf dieselbe Site der Benutzer nicht jedes Mal seine Zugangsdaten erneut eingeben muss, hält der Browser diese Zugangsdaten in einem Cache vor und liefert sie bei jedem Zugriff erneut mit aus.Dieses Verfahren erinnert nicht nur fatal an Cookies, es wird auch für ähnliche Tracking-Methoden genutzt – mit dem Unterschied, dass Authentication Caching ein Standardverfahren und fest in allen Browsern eingebaut ist: Der Benutzer merkt davon nichts und wird auch nicht zur Zustimmung aufgefordert.Um den Authentication Cache zum Benutzer-Tracking zu nutzen, kann zum Beispiel folgendermaßen vorgegangen werden:
- Auf der Webseite wird über ein eingebundenes JavaScript auf eine geschützte Server-Ressource des Tracking-Providers zugegriffen. Das muss gar nicht besonders aufwändig sein, eine ein Pixel große Grafik genügt völlig.
- Da die Ressource gegen anonymen Zugriff geschützt ist, antwortet der Server mit dem Fehlercode 401 – Unauthorized und fordert vorgeblich via WWW-Authenticate Zugangsdaten an. Gleichzeitig liefert der Server mit dieser Antwort aber eine gültige Benutzername-Passwort-Kombination aus, über die der Benutzer eindeutig identifiziert werden kann.
- Das JavaScript auf der Clientseite wertet die Antwort des Servers aus und ruft die geschützte Server-Ressource direkt noch einmal ab – diesmal aber inklusive Benutzername und Passwort. Da jetzt der Zugriff klappt, legt der Browser diese Zugangsdaten in seinem Cache ab und ergänzt damit jeden weiteren Zugriff auf die Werbe-Site. Der Benutzer meldet sich also quasi bei jedem Zugriff mit einer eindeutigen ID dort an.
The show must go on
Die großspurig angekündigten Versprechen der Browser-Hersteller, die Privatsphäre der Nutzer durch die Ächtung von Third-Party-Cookies besser zu schützen, sind also letztlich genauso wirkungslos wie die Kreuzzüge der deutschen und europäischen Gerichtsbarkeit gegen Cookies im Allgemeinen. Die Werbebranche hat längst andere Wege gefunden, Nutzer sind bereits heute auch dann identifizierbar, wenn kein einziges Cookie mehr gesetzt wird. Selbst die strengsten Browser-Einstellungen täuschen im Grunde Privatsphäre nur vor und wiegen die Nutzer lediglich in Sicherheit.
Typisches Beispiel ist die „Do Not Track“-Funktion: Seit 2012 ist das Verfahren standardisiert und wird von praktisch allen modernen Browsern unterstützt. Europäische Datenschutzexperten sind sich darüber einig, dass ein gesetztes „Do Not Track“-Flag ein wirksamer Widerspruch gegen den Aufbau von benutzerspezifischen Profilen im Sinn des Art. 21 Abs. 5 der Datenschutzgrundverordnung ist. Und was passiert? Nichts. Das „Do Not Track“-Flag wird von vielen Websites schlicht ignoriert. Zitat aus einer aktuellen Datenschutzerklärung eines großen Werbenetzwerks: „Die ‚Do Not Track‘-Funktion wird auf unseren Server bislang nicht unterstützt.“
Auch das eingangs zitierte Urteil des Bundesgerichtshofs vom Mai 2020 ist selbst bei großen deutschen Websites nicht konsequent umgesetzt: Nach wie vor berufen sich viele Betreiber auf das in Deutschland geltende Telemediengesetz und sehen ihre alten Opt-Out-Lösungen (siehe Abbildungen 1 und 2) durch die dort formulierte sogenannte Widerspruchsregelung gedeckt. Der BGH hat jetzt zwar klargestellt, dass auch das Telemediengesetz im Sinne der DSGVO zu interpretieren ist und eine Out-In-Lösung fordert. Trotzdem setzen sich solche Lösungen nur sehr langsam durch.
Ein Grund hierfür ist sicherlich das weitverbreitete Standarddesign von Websites: Eingebetteter Code wird möglichst früh geladen, schon allein deswegen, weil die zusätzlichen Abfragen bei dritten Servern per se die Ladezeit der Seite verlängern. Das bedeutet aber, dass auch die Übergabe von Benutzerinformationen an Werbeanbieter oder Social-Media-Provider direkt beim Aufruf der Seite geschieht und damit vor irgendwelchen Aufforderungen, der Verwendung von Cookies und Tracking zuzustimmen. Opt-In fordert jetzt ein umgekehrtes Default-Verhalten von Webseiten: Zuerst fragen, dann überwachen. Die Websites müssen beim ersten Aufruf frei von Trackingmaßnahmen sein, erst nach einer aktiven Handlung des Nutzers (Häkchen setzen etc.) darf das Tracking starten.
Wobei die Frage erlaubt sein muss, warum ich mich überhaupt mit nervigen Cookie-Bannern auseinandersetzen muss, wenn ich beispielsweise das „Do Not Track“-Flag gesetzt habe? Leider hat sich der Bundesgerichtshof zu „Do Not Track“-Flags überhaupt nicht geäußert.
Google sucht derzeit einen eigenen Ausweg aus diesem Dilemma: die Privacy Sandbox.
Unter diesem Begriff entwickelt Google nach eigenen Angaben eine „attraktive Alternative“ zu Third-Party-Cookies. Die Open-Source-Initiative des Chromium-Projekts (siehe https://www.chromium.org/Home/chromium-privacy/privacy-sandbox) will erreichen, dass unter Wahrung der Privatsphäre des einzelnen Nutzers „ein ‚gesundes‘, werbefinanziertes Web aufrechterhalten werden kann, das Cookies von Drittanbietern überflüssig macht“ (Justin Schuh, Chrome Engineering Director) – quasi ein Spagat zwischen Privatsphäre und zielgerichteter Werbung.
Die Idee dahinter ist im Grunde eine Teilanonymisierung der Benutzerdaten. Websites erhalten über APIs des Browsers eingeschränkten Zugriff auf Benutzerdaten, so dass der Benutzer zwar einer Werbezielgruppe zugeordnet, aber nicht persönlich identifiziert werden kann. Außerdem kann der Benutzer jederzeit darüber informiert werden, wer welche seiner Daten haben möchte.
Das Projekt steckt derzeit noch sehr in den Kinderschuhen, technische Vorschläge zur Realisierung gibt es jedoch viele: vom Einsatz künstlicher Intelligenz und Machine Learning bis hin zur Definition offener Schnittstellen zu Identity-Providern, die hierüber Informationen über ihre Nutzer bekannt geben sollen. Googles Interesse liegt aber natürlich auch darin, die Alleingänge der anderen Browser-Hersteller zu stoppen und allgemein akzeptierte Standards durchzusetzen, die Googles Geschäftsmodell möglichst wenig beeinträchtigen.
Fazit
Es steht zu befürchten, dass sich an der globalen Überwachung von Internetnutzern wenig ändert. Die Idee, zukünftig verstärkt auf Sandboxing zu setzen, also Datenschutz durch Browser-APIs zu steuern, trägt das Potenzial, die Kontrolle über die Weitergabe seiner Daten dem Benutzer zu übertragen. Aber das ist bei Cookies schon so, und trotzdem gibt es bei keinem relevanten Browser eine leicht bedienbare Schnittstelle zu ihrer Steuerung.
Stattdessen werden weiterhin Nebelkerzen gezündet, die Nutzer von einer Flut von Zustimmungsbannern genervt und auch noch widersinniger Weise Cookies gesetzt, um den Widerspruch zum Setzen von Cookies zu dokumentieren. Und die Benutzer müssen sich blind darauf verlassen, dass ihre Wünsche von der Gegenseite tatsächlich auch berücksichtigt werden. Dass dem in vielen Fällen nicht entsprochen wird, zeigen Privacy-Einstellungen wie „Do Not Track“ oder die völlig willkürliche und wenig transparente Einteilung in angeblich „notwendige“ und optionale Cookies. Der Begriff des „notwendigen Cookies“ wird meist aus dem Telemediengesetz (§ 15 Nutzungsdaten) abgeleitet. Dort wird aber die Erlaubnis, personenbezogene Daten zu erheben und zu verarbeiten, auf den technischen Betrieb der Website beziehungsweise der Dienstleistung beschränkt. Wirtschaftliche Ziele wie Benutzer-Tracking oder Werbung gehören definitiv nicht hierzu, auch wenn viele Website-Betreiber momentan dazu neigen, alles Mögliche als notwendig zu deklarieren. Auch kenne ich keine Website, wo bereits gesetzte (optionale) Cookies bei einem Widerspruch gelöscht werden.
Es steht schlicht zu viel auf dem Spiel. Selbst der verbissenste Datenschützer wird zugestehen müssen, dass große Teile des Webs werbefinanziert sind und ein Internet, so wie wir es heute kennen und nutzen, ohne Werbung nicht denkbar ist. Es wäre aber ehrlicher endlich darüber zu sprechen, worum es wirklich geht, nämlich um Benutzer-Tracking:
- Was fällt eigentlich unter diesen Begriff? Eine notwendige Abgrenzung wird in den USA völlig anders beantwortet als in Europa.
- Was ist erlaubt und wo wird über ein vernünftiges Ziel hinausgeschossen?
Die Fixierung auf Cookies ist hier nicht zielführend, Cookies sind allenfalls ein Mittel zum Zweck – eines unter vielen – und manche Cookies sind überhaupt nicht zustimmungspflichtig. Nur dort wo Benutzer-Tracking eingesetzt wird oder personenbezogene Daten zustimmungspflichtig verarbeitet werden, muss klar darauf hingewiesen werden.
Die Werbebranche ist mit Methoden wie Fingerprinting und der Erstellung individueller Nutzerprofile weit über jedes akzeptable Ziel hinausgeschossen. Die derzeitige Praxis, die Zustimmung zum Tracking durch unnötig aufgeblähte Informationsboxen oder fadenscheinige Begründungen („Funktionale Cookies benötigen wir zwingend, damit bei Ihrem Besuch unserer Website alles gelingt.“) zu erschleichen, sorgt nicht dafür, das katastrophale Image der Branche zu verbessern.
Darüber hinaus taugen diese Lösungen auch nicht zu einem rechtssicheren Betrieb von Websites. „Viel hilft viel“ ist an dieser Stelle nicht der richtige Weg. Der BGH hat klargemacht, dass er eine aktive Zustimmung zum Tracking erwartet, bevor entsprechende Skripte gestartet werden, und dass der Nutzer verstehen muss, wozu er da seine Zustimmung erteilt. Ein „damit alles gelingt“ erfüllt meiner nichtjuristischen Meinung nach diese Anforderung nicht.
Und nebenbei bemerkt, der BGH hat auch klargestellt, dass Verstöße zumindest von Verbraucherschutzverbänden kostenpflichtig abgemahnt werden dürfen.
Verweise
[1] https://www.bundesgerichtshof.de/SharedDocs/Pressemitteilungen/DE/2020/2020067.html

