Nutzung von Cloud Computing
Um eine Cloud-Nutzung kommt ein Unternehmen kaum mehr herum. Dabei dominieren hybride Cloud-Architekturen mit einem Anteil aus privater und öffentlicher Cloud. Das Angebot an verfügbaren Cloud-Diensten ist riesig und erstreckt sich von Software-as-a-Service (SaaS) über Infrastructure-as-a-Service (IaaS) bis hin zu Platform-as-a-Service (PaaS), um nur einige bekannte Dienste zu benennen.
Nach Nutzung einer klassischen On-Premises-Architektur sind Hersteller mittlerweile dazu übergangen, ihre Lösungen als hybride Architektur anzubieten. Viele von ihnen gehen einen Schritt weiter und bieten ihre Produkte ausschließlich mit einer Cloud-Architektur an.
Anders als die zunächst vorsichtige Nutzung mit nur unkritischen Daten werden vermehrt auch kritische Geschäftsinformationen in der öffentlichen Cloud verarbeitet und gespeichert. Dazu gehören ebenso Kommunikationsdaten, die mit Kunden ausgetauscht werden. Bei vergleichsweise neuen digitalen Technologien aus dem Bereich Internet of Things (IoT) und künstlicher Intelligenz (KI) wurde die Nutzung der Cloud bereits frühzeitig forciert.
Der Bildungssektor als ein Bereich, der bisher vergleichsweise weniger auf Cloud-Dienste zurückgegriffen hat, ist vom digitalen Wandel betroffen. Grund hierfür ist die seitens der Bundesregierung ins Leben gerufene Umsetzungsstrategie, die mit dem DigitalPakt Schule und einem Finanzvolumen von fünf Milliarden Euro über eine Laufzeit von fünf Jahren diesen Wandel beschleunigen soll (siehe [1]). Erste Implementierungen von Cloud-managed-WLAN, Schul-Messenger und Cloud-Speicher sind DSGVO-konform im Einsatz.
Mit der Datenverarbeitung und –speicherung in der Cloud und dem veränderten Nutzerzugriff findet eine Erweiterung und Verlagerung der Sicherheitsinfrastruktur statt. Doch die Absicherung von zentralen Komponenten der Cloud-Anbieter lässt sich vom Kunden kaum kontrollieren. Damit verlagern sich Verantwortungsbereiche für unternehmenskritische Umgebungen in die Zuständigkeit der Cloud-Anbieter.
Mit dem Inkrafttreten der EU-Datenschutz-Grundverordnung (DSGVO) im Mai 2018 und dem EuGH-Urteil zum US-Privacy-Shield im Juli 2020 (siehe [2]) sind besondere Anforderungen an die Datenverarbeitung und Nutzung von Cloud-Strukturen entstanden. Die Nutzer und Anbieter werden hier gleichermaßen in die Pflicht genommen, die Lösung rechtskonform zu nutzen.
Störungserkennung und Ursachenforschung
Stößt man bei der Nutzung von Cloud-Diensten auf ein Problem, muss zunächst die Frage beantwortet werden, wer die möglichen Verursacher sind. Stellt man bei der Fehleranalyse fest, dass man Probleme in der eigenen IT ausschließen kann, fällt der Fokus auf die Internet- und Cloud-Provider.
Mit dem lokalen Internet-Service-Provider (ISP) besteht prinzipiell ein Service-Vertrag, über den Störungen eingesehen und gemeldet werden können. Die nachgelagerten Internetknoten und Cloud-Infrastrukturen werden aus Monitoring-Sicht häufig als Black Box wahrgenommen.
Im März 2020 wurde in Frankfurt beim Deutschen Commercial Internet Exchange (DE-CIX) – der weltweit führende Betreiber von Internetknoten – ein neuer Weltrekord im Datendurchsatz an einem Internetknoten gemessen. Mit über 9,1 Terabit pro Sekunde wurde im Vergleich zum vorherigen Rekord im Dezember 2019 mit 8 Terabit pro Sekunde eine Steigerung um mehr als 12 Prozent beobachtet (siehe [3]). Daraus wird ersichtlich, dass zumindest die zentralen Knotenpunkte über ausreichend Kapazitätsreserven verfügen. Für die verteilten Provider-Infrastrukturen abseits der Hauptknotenpunkte trifft dies nicht unbedingt zu.
Es sollte nicht außer Acht gelassen werden, dass mit Hilfe von Premium-Routing-Diensten – also direktes / priorisiertes Routing zu den Cloud-Anbietern – die Performance verbessert und Ausfälle verringert werden können.
Der Internet-Performance-Report des Netzanalyse-Unternehmens ThousandEyes zeigt, dass die seit März 2020 angestiegene Verkehrslast durch die Cloud-Provider besser verarbeitet werden kann als durch die ISP-Netzwerke. Jedoch geht daraus auch klar hervor, dass sich eine Störung oder ein Ausfall innerhalb einer Cloud-Struktur eher auf die Benutzer auswirkt (siehe [4]).
Teilausfall oder Störung einer Cloud kann verschiedene Ursachen haben. Die folgenden Gründe sind zu nennen:
- Unzureichende Dimensionierung von Ressourcen
- Konfigurationsfehler
- Komponentenausfall
- Wartungsarbeiten
- Distributed Denial of Service (DDoS) als Angriff auf oder aus der Cloud-Infrastruktur
Für die Anwendungsbetreuer ist es wichtig, die Hintergründe einer Störung zu erfahren, um Transparenz für die Nutzer zu schaffen. Zudem lassen sich so Gegenmaßnahmen einleiten und mögliche Alternativen eruieren.
Skalierungsgrenzen und Ressourcenverteilung
Auf eine durch COVID-19 gesteigerte Cloud-Nutzung waren die Anbieter nicht vorbereitet. Prominentes Beispiel ist der Teilausfall der Kollaborationslösung Microsoft Teams am 16. und 17.03.2020, der viele Nutzer in Europa betraf. Anwender beklagten Probleme bei der Nutzung der Messaging-Dienste (siehe Abbildung 1). Ursache war laut Hersteller ein untergelagerter Dienst.
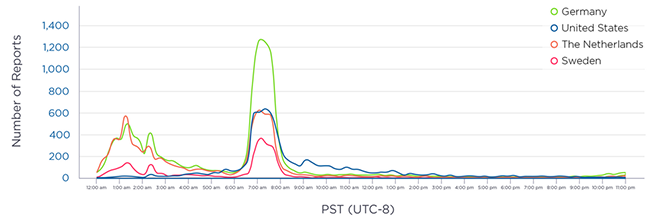
Abbildung 1: Microsoft-Teams-Störung, 16.03.2020 Quelle: Downdetector.com
Es sollte nicht unerwähnt bleiben, welche drastische Nutzungsänderung die aktuelle Pandemie zur Folge hatte. Nach Aussage des Herstellers erzielte Microsoft Teams Ende März 2020 einen neuen Tagesrekord von 2,7 Milliarden Besprechungsminuten. Im Folgemonat waren es dann sogar 4,1 Milliarden Minuten an Besprechungen. Vor dem Ausbruch der Pandemie wurden Tageswerte von üblicherweise 900 Millionen Minuten genannt (siehe [5]).
Ungeachtet eines konkreten Cloud-Dienstes sind die Ressourcen in der Cloud eben auch nicht unendlich, jedoch dafür umso skalierbarer. Allerdings gibt es auch hier Grenzen und eine gewisse Reaktionsverzögerung spielt ebenfalls eine Rolle. Wie bereits in der Vergangenheit geschehen, kann der Dienstanbieter die ihm obliegenden Ressourcen wie Netz- und Verarbeitungskapazitäten innerhalb der angebotenen Dienste dynamisch zuteilen. So können selbst genutzte Cloud-Applikationen trotz gesamtheitlich hoher Ressourcenverfügbarkeit durch den Anbieter benachteiligt werden. Die Steuerung und Gewichtung liegt in den Händen der Anbieter. Der Nutzer hat in der Regel keinen oder eher geringen Einfluss auf die interne Nutzung der Cloud-Ressourcen. Selbst Einblicke in dieses Regelwerk sind schwierig und auf Grundlage der fortschreitenden Automatisierung wenig transparent.
Fehlersuche in der Cloud am Beispiel Microsoft
Selbstverständlich kommt es auch bei den großen Cloud-Anbietern aufgrund laufender Migrationen, Erweiterungen und Ausfällen zu Störungen. Um nun im Fall einer Anwendungsstörung die Cloud-Infrastruktur als möglichen Verursacher zu identifizieren, stellen die Cloud-Anbieter für Administrations- und Supportmitarbeiter Oberflächen bereit, mit denen eine Korrelation zwischen den gemeldeten Vorfällen in der Cloud und den Kunden-internen Störungen festgestellt werden kann.
Für Anwendungen im Rahmen von Microsoft 365 können über die Portalseite der Dienststatus erfasst und mögliche Vorfälle und Hinweise verifiziert werden. Dabei wird auf Basis der angebotenen Dienste zwischen Vorfällen (= kritisches Dienstproblem) und Hinweisen (= Dienstproblem mit begrenztem Umfang oder Auswirkung) unterschieden (siehe Abbildung 2).
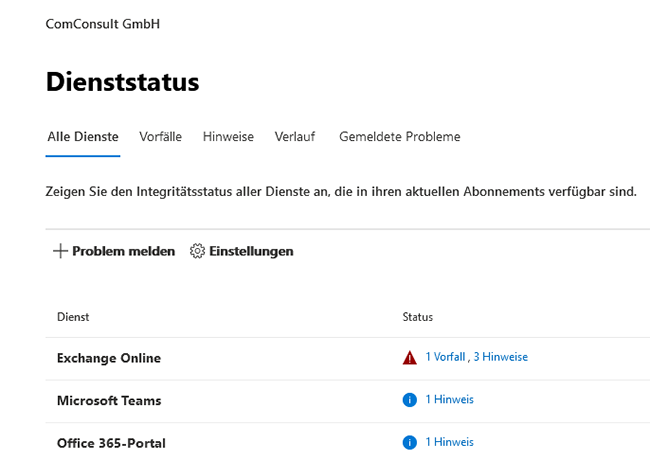
Abbildung 2: Microsoft-365-Dienststatus
In einer nachgelagerten Ansicht lassen sich u.a. der Verlauf, die damit verbundenen Auswirkungen und die eigentliche Ursache für die vergangenen 30 Tage erkennen. Darüber hinaus können auch eigene Probleme gemeldet und verwaltet werden.
Für Microsoft Teams steht eine weitere Administrationsoberfläche bereit, die eine spezifische Analyse von Problemfällen auf Basis eines Anrufverlaufs je Benutzer erlaubt (siehe Abbildung 3).
Neben Informationen zu den eingesetzten Endgeräten werden je Kommunikationsrichtung Parameter über das Laufzeitverhalten und der Paketverlustrate zur Auswertung angeboten. Die für eine Analyse wichtigen Informationen wie Zugangsverfahren (z.B. Ethernet, Wi-Fi, Mobile), damit verbundene Details wie MTU-Größe oder WLAN-Signalfeldstärke sowie Nutzung eines VPN-Zuganges sind hier enthalten. Auch die Angaben der beiden verwendeten Internetzugangspunkte und die verwendeten Medien-Relay-Server (MR), über die die Echtzeitkommunikation geführt wird, sind dargestellt. Wie die nachfolgende Abbildung zeigt, lässt sich mit den oben erwähnten Parametern die Paketverfolgung in großen Teilen abbilden.
Mit diesen und weiteren Informationen lassen sich viele typische Problemfelder identifizieren oder zumindest besser eingrenzen.
Anwendungsbeispiel App-Gebäudesteuerung
Im Folgenden wird als Beispiel ein Last- und Performance-Test zur Verifizierung der Skalierungsgrenzen und Engpässe im Umfeld einer Cloud-basierten Anwendung beschrieben. Bei der eingesetzten Lösung handelt es sich um eine Cloud-Digitalisierungsplattform, die in einem der großen Cloud-Provider-Strukturen gehostet ist. Mithilfe einer App können Gebäudekomponenten wie beispielsweise Zutrittskontrolle, Beleuchtung, Beschattung und Klimatechnik Cloud-basiert gesteuert werden.
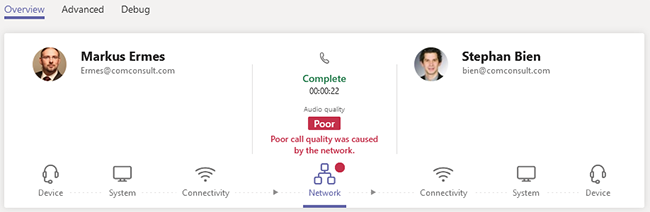
Abbildung 3: Microsoft Teams Admin Portal – Anrufanalyse
Damit Komponenten der Gebäudeleittechnik unterschiedlicher Hersteller mit einer zentralen Dritt-Software kommunizieren können, war eine speziell auf die Kundenumgebung angepasste Lösung vonnöten.
Die App ist auf dem mobilen Endgerät der Nutzer und Besucher installiert und nutzt die vorhandene Mobilfunk-Anbindung für den Zugriff in die Cloud, in der die Digitalisierungsplattform gehostet ist. Von dort aus läuft die Kommunikation zu einem Gateway, welches im zu steuernden Gebäude die externen Zugriffe verwaltet und entgegennimmt. Von diesem Gateway in der demilitarisierten Zone (DMZ) werden die internen Gebäudekomponenten über eine zweistufige Firewall-Architektur gesteuert. In der Gebäudesteuerung kommt eine Reihe von Kommunikationsprotokollen zum Einsatz, die weitere Gateways und Schnittstellen erfordern (siehe Abbildung 5).
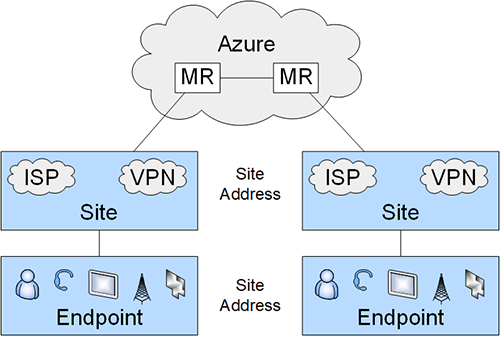
Abbildung 4: Schema der Microsoft-Teams-Sessionanalyse
Auf dem beschriebenen Kommunikationsweg, der sowohl bidirektional als auch unidirektional sein kann, lassen sich Prüffunktionen etablieren, um im Fall eines Belastungstests die möglichen Grenzen und Grenzüberschreitungen zu identifizieren. Sobald die Ursache eines Engpasses identifiziert ist, können Gegenmaßnahmen eingeleitet werden.
Die Nutzung der hier eingesetzten App erfordert eine Login-Sequenz, bestehend aus dem eigentlichen Login sowie dem Laden von Elementen, die für die Erstausführung der App relevant sind.
Die bei dem Login-Prozess erforderlichen Daten belaufen sich je Nutzer-Login auf einige hundert Kilobyte. Demzufolge ist eine ausreichend dimensionierte WLAN-Infrastruktur und / oder Inhouse-Mobilfunkversorgung bei einer hohen Nutzerdichte Grundvoraussetzung für eine reibungslose Nutzung einer solchen Lösung. Selbstverständlich sind die Bandbreitenanforderungen für die lokalen Internetzugänge einzubeziehen, da der Login-Prozess ein Anwendungsfall von vielen ist und die Internetzugänge für weitere Anwendungen und Dienste genutzt werden. Dabei lassen sich weitere Daten-fordernde Systeme wie eine Inhouse-Navigation identifizieren, die weitere Ressourcenanforderungen stellen.
In dem oben skizzierten Beispiel hat sich die Speicherverwaltung der Compute-Ressource in der Cloud als Engpass erwiesen. In der Softwareentwicklung verwaltet der Garbage Collector die Belegung und Freigabe von Arbeitsspeicher für eine Anwendung.
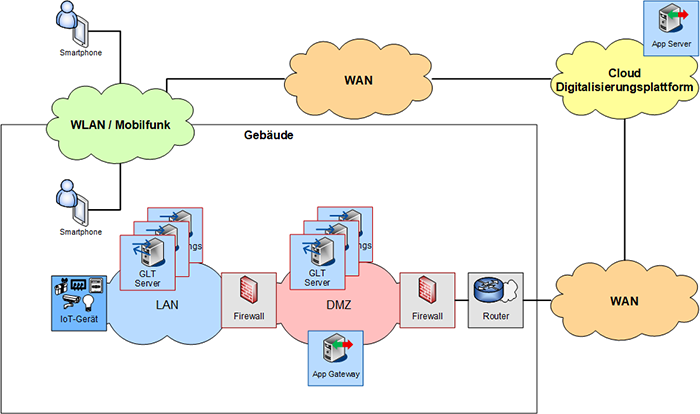
Abbildung 5: Cloud-Digitalisierungsplattform zur Gebäudesteuerung
Die Herausforderung besteht darin, die Daten zu identifizieren, die für die Anwender benötigten wiederkehrenden Datenquellen im Arbeitsspeicher zu belassen (Caching) und die nicht mehr verwendeten Daten zu verwerfen (Garbage Collection). Durch den Garbage Collector wird die CPU zusätzlich belastet, was zu einer Überlast der Umgebung führen kann. Bleibt die Kombination von Nutzeranzahl und Anmelderate niedrig, ist die Speicherauslastung unkritisch, und der Garbage Collector wird nicht tätig. Mit ansteigenden Nutzerzugriffen erweist sich dies als ein Problem, wie die folgende Abbildung beispielhaft zeigt. Während des Performance-Tests (roter Kasten) steigt die CPU- und Speicherauslastung an und überschreitet die definierten Schwellwerte. Dieser Umstand hält mehrere Minuten nach dem durchgeführten Test (orangener Kasten) an.
Nach der Testdurchführung und Identifizierung der Problematik ließen sich die Ergebnisse für die Anwendungsentwickler nutzen, um die Speicherverwaltung zu optimieren. Anstatt die Compute-Ressourcen aufzustocken, denn dies verursacht einen nicht zu vernachlässigenden Kostenfaktor, wurde eine effizientere Speicherverwaltung mit geringem Aufwand umgesetzt. Damit ließen sich mit gleichbleibenden Ressourcen höhere Skalierungsstufen in der Größenordnung von 50% erzielen.
Grenzen und Optionen der Überwachung
Die Überwachungsfunktionen der Anbieter konsolidieren meist mehrere Dienste und Applikationen auf ein Statuselement. Dabei werden Ausfälle und Störungen in einem Teilbereich nicht unbedingt als Störung dem Kunden-Support-Team gemeldet. Auch ist das Abfrageintervall in der Praxis so gewählt, dass kurzzeitige Ausfälle im Sekundenbereich nicht auffallen. Ein Anwender wird hingegen in einer Telefonkonferenz eine Störung von einigen Sekunden sehr wohl als Problem wahrnehmen. Demzufolge ist die Transparenz hier häufig nicht gegeben. Wenn derlei Problemfälle nun öfter auftreten, ist der Anwender unzufrieden und der lokale Netzwerkbetreiber und Anwendungsbetreuer hat kein probates Mittel zur Hand, um diese Störungen dem Cloud-Anbieter zuzuordnen. In der Praxis wird dann häufig die lokale Infrastruktur dafür verantwortlich gemacht. Diese Vermutung kann, muss aber nicht, zutreffen.
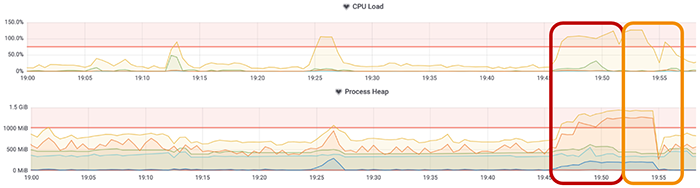
Abbildung 6: CPU- und Speicherauslastung der Cloud-Compute-Ressource
Eine mögliche Lösung dieses Problems ist der Einsatz eines verteilten Monitoring-Systems, das geschäftskritische Anwendungen aus verschiedenen Blickwinkeln (Netzumgebungen und Standorten) dezentral mit Hilfe einer Echtzeitanalyse überwacht.
ThousandEyes ist ein Beispiel einer solchen Umgebung, die im SaaS-Bereich in den Clouds der globalen Anbieter, im eigenen Rechenzentrum oder einfach auf Endgeräten als Agent seine Dienste verrichten kann. Das Unternehmen – mit Sitz in Kalifornien – existiert seit zehn Jahren und ist durch das rasante Wachstum seit rund einem Jahr auch hierzulande mit einer Niederlassung in München präsent (siehe [6]).
Die von ThousandEyes betriebene Plattform besitzt eine beeindruckende Übersicht auf die weltweiten Layer-3-Knotenpunkte der Internet- und Cloud-Provider. Damit lassen sich Performance-Engpässe und Unterbrechungen wie Latenz, Jitter oder Paketverlustrate erkennen und einem konkreten Provider zuordnen. Abbildung 7 veranschaulicht dies anhand einer Pfadvisualisierung zwischen verschiedenen Lokationen und den dazwischen liegenden Routern.
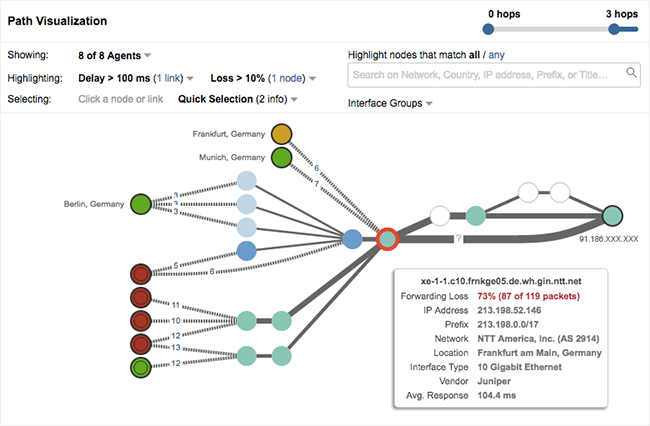
Abbildung 7: ThousandEyes – Pfadvisualisierung (Quelle [7])
Ebenso lässt sich eine veränderte DSCP-Markierung im IP-Paketheader aufdecken, die im weiteren Paketverlauf Einfluss auf den Transport haben kann. Größere Störungen können hiermit an den Service-Provider gemeldet werden.
Der steigende Bedarf an digitalen Diensten der Cloud-Provider erfordert für ein aussagekräftiges Ende-zu-Ende-Monitoring ein Mindestmaß an Sichtbarkeit der Netzzustände außerhalb der eigenen Netzstruktur. Der Netzwerk-Hersteller Cisco Systems zeigte mit seiner Akquisition von ThousandEyes im August 2020, dass dies ein wichtiger Wachstumsmarkt ist (siehe [8]).
Fazit
Die Cloud-Nutzung kann trotz der damit verbundenen Skalierbarkeit von Engpässen betroffen sein. Ein Last- und Performance-Test kann herangezogen werden, um diese zu identifizieren und Skalierungsgrenzen auch außerhalb der Cloud-Infrastrukturen aufzudecken. Hierzu ist eine umfängliche Überwachung der Teilabschnitte der Übertragungs- und Verarbeitungskette und der eigenen Ressourcen vonnöten.
Verweise
[1] https://www.bundesregierung.de/breg-de/themen/digital-made-in-de/digitalpakt-schule-1546598
[2] https://www.bfdi.bund.de/DE/Europa_International/International/Artikel/EU-US_PrivacyShield_Daten%C3%BCbermittlungenUSA.html
[3] https://www.de-cix.net/de/about-de-cix/media-center/press-releases/de-cix-sets-a-new-world-record
[4] https://www.thousandeyes.com/research/internet-performance
[5] https://news.microsoft.com/innovation-stories/azure-covid-19/
[6] https://www.thousandeyes.com/de/pressemitteilung/thousandeyes-startet-auf-dem-deutschen-markt
[7] https://www.thousandeyes.com/resources/richrelevance-case-study
[8] https://www.cisco.com/c/en/us/about/corporate-strategy-office/acquisitions/thousandeyes.html

