Der Begriff „DevOps“ wird in der IT an vielen Stellen genutzt. So werden in Stellenanzeigen beispielsweise keine „System-Administratoren“ mehr gesucht, sondern „DevOps Engineers“. DevOps wird von Entwicklern angepriesen. Hersteller erklären ihre Produkte für „DevOps-Ready“. Durch die unterschiedlichen Herangehens- und Sichtweisen kann der Eindruck entstehen, dass DevOps alles und nichts ist.
Zusätzlich fallen in diesem Umfeld häufig ein oder (meistens) mehrere der folgenden Begriffe:
- Agilität
- SCRUM
- Microservices
- Container
- Cloud
- Continuous Integration bzw. Continuous Delivery
Es ergibt sich also eine große Zahl von Begriffen, die mehr oder weniger klare Definitionen haben. Trotzdem ist nicht immer klar, was an welcher Stelle gemeint ist. Wie kommt es dazu?
Leider werden manche Begriffe trotz eigentlich klarer Abgrenzung gemischt oder sogar synonym verwendet. Dadurch ergibt sich ein mitunter chaotisches Gemenge aus Begriffen, Definitionen und Buzzwords. (siehe Abbildung 1)

Abbildung 1: Gemengelage der Begriffe im Umfeld DevOps
In diesem Artikel werden die einzelnen Begriffe bzw. deren Ursprung erläutert, um ein übersichtliches und strukturiertes Gesamtbild zu zeichnen.
Zunächst wird der Grundsatz der Agilität erläutert und darauf aufbauend die Möglichkeiten für die Softwareentwicklung. Als Beispiel für eine agile Projektabwicklung wird auf SCRUM eingegangen, welches auch bei vielen unserer Kunden angewandt wird.
Danach werden die eher technischen Aspekte der Microservices erläutert und die momentan dafür wohl am häufigsten eingesetzte Technologie: Container. Dabei wird auch die Rolle der Cloud in diesem Bereich beschrieben.
Um einen der großen Vorteile agiler Entwicklung, die Geschwindigkeit, nicht beim Bereitstellen von Software zu verlieren, wird auch auf Continuous Integration und Continuous Delivery eingegangen.
Zu guter Letzt wird beschrieben, wie Dev-Ops all diese Bereiche zusammenbringt und wie sich dadurch der betriebliche Alltag (zum Besseren) wendet.
Agile Produktentwicklung
Der Begriff „Agile Development“ ist heute sehr weit verbreitet und wird für alle möglichen Produkte genutzt. Auch im Netzwerk Insider wurde Agilität schon behandelt, aber aus der Sicht der Infrastrukturbetreiber [1]. Der Begriff kommt aber eigentlich aus der Softwareentwicklung. Ihren Ursprung hat die agile Softwareentwicklung in den 1990er Jahren. Zu dieser Zeit kamen vermehrt leichtgewichtige Tools hierfür auf den Markt, die eine beschleunigte Entwicklung erlaubt haben. 2001 hat eine Reihe von Entwicklern das „Manifest für Agile Softwareentwicklung“ veröffentlicht [2]. Dieses beschränkt sich auf vier Thesen:
- Individuen und Interaktionen sind wichtiger als Prozesse und Werkzeuge
- Funktionierende Software ist wichtiger als umfassende Dokumentation
- Zusammenarbeit mit dem Kunden ist wichtiger als Vertragsverhandlungen
- Reagieren auf Veränderung ist wichtiger als das Befolgen eines Plans
Diese einfache Formulierung hat die Kritik durch Traditionalisten ausgelöst. Darunter zum Beispiel, dass der zweite Punkt nur dem Wunsch von Entwicklern entsprach, möglichst keine Dokumentation schreiben zu müssen. Dem wird von Anhängern der agilen Softwareentwicklung entgegnet, dass es sich bei den Thesen nicht darum ging, die „weniger wichtige“, rechte Seite komplett abzuschaffen, sondern im Zweifelsfall die Prioritäten zugunsten der linken Seite zu verschieben. Bezüglich der Dokumentation kann man beispielsweise den Entwicklern folgenden Ratschlag geben:
„Die Dokumentation sollte das beinhalten, was ein Entwickler braucht, wenn er morgen in das Team aufgenommen wird.“
Aber woher kamen diese Thesen? Dazu ein kurzer Ausflug in die „klassische“ Entwicklung. Dabei kommt sehr häufig das „Wasserfall“-Modell zum Einsatz. Hier werden nacheinander die folgenden Schritte durchgeführt:
- Aufnahme und Dokumentation der Kundenanforderungen
- Design der Lösung
- Programmierung und Tests
- Tests des Gesamtsystems
- Tests der Nutzererfahrung (UAT – User Acceptance Tests)
- Fehlerbehebung
- Auslieferung
Insbesondere der erste Schritt, die Formulierung der Anforderungen, stellt eine enorme Herausforderung dar. Je nach Ansprechpartner beim Kunden oder der Menge der involvierten Personen sind zu Beginn eines Projekts nicht alle Anforderungen vollständig erfassbar. Dadurch kommt es im späteren Verlauf häufig zu Anpassungen oder Erweiterungen der Anforderungen. Je nach Fortschritt und gewählter Architektur kann dies nachträglich erhebliche Änderungen erfordern, die eine fristgerechte Auslieferung der Software erschweren oder gar unmöglich machen. Zusätzlich bedeutet es, dass auf Seite des Entwicklers und evtl. auf Seite des Kunden deutliche Mehrkosten entstehen. An anderen Stellen können Schwierigkeiten auftreten, insbesondere wenn die Vorgehensweise sehr streng eingehalten wird und der Kunde das Produkt erst zu einem sehr späten Zeitpunkt zu Gesicht bekommt. Wenn das Produkt dann nicht den Erwartungen des Kunden entspricht, ergeben sich neue Herausforderungen.
Genau diese Nachteile sollen durch agile Entwicklung vermieden werden. Die erste und die dritte These stellen dabei einen Lösungsansatz für die o.g. Herausforderung dar: Interaktionen, ganz besonders mit dem Kunden, sind wichtiger als ein starrer Vertrag und starre Prozesse. Beispielhaft sind die Unterschiede zwischen klassischer und agiler Entwicklung in Abbildung 2 dargestellt.
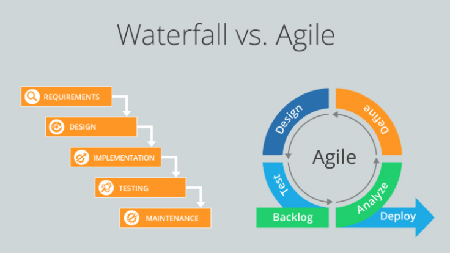
Abbildung 2: Vergleich von Entwicklungsphilosophien: Waterfall gegen agil
Agile Softwareentwicklung verringert also die Kluft zwischen Kunde und Entwickler. Sie stellt einen effektiven und effizienten Ansatz der Softwareentwicklung dar, ohne eine bestimmte Technologie vorzuschreiben.
Um diese schnellere Anpassung an sich ändernde Kundenanforderungen zu ermöglichen, werden dem Kunden häufiger Zwischenergebnisse präsentiert. Die Kernpunkte dieser Zwischenergebnisse, z.B. Funktionen einer Software, werden dabei vom Kunden priorisiert. Ein häufig genutztes Verfahren für die Umsetzung ist SCRUM:
SCRUM – die wohl bekannteste Umsetzung der agilen Entwicklung
SCRUM ist ein Verfahren, das in vielen Bereichen zum Einsatz kommt. Auch für die Betrachtung und Einführung von Technologien hat sich dieses Verfahren bewährt. Was genau ist SCRUM? Woher kommt es? Welche Begriffe muss man kennen?
Fangen wir chronologisch mit der Frage nach der Herkunft an: Der Begriff SCRUM in Verbindung mit Softwareentwicklung trat erstmals 1986 auf, ist also noch wesentlich älter als das Agile Manifesto. Der Begriff kommt übrigens ursprünglich aus dem Rugby-Sport. Dort bezeichnet es eine Ansammlung von Spielern, die „ihre Köpfe zusammenstecken“ und um den Ball streiten. (siehe Abbildung 3) In der Softwareentwicklung ist es ein kompaktes Verfahren, Projekte umzusetzen. Auch hier werden häufig und intensiv die Köpfe zusammengesteckt.

Abbildung 3: Ein Scrum beim Rugby
Bei SCRUM gibt es eine ganze Reihe von Begriffen, die klar definiert sind und die man zumindest in Grundzügen verstehen sollte. Dabei kann man die Begriffe in verschiedene Bereiche aufteilen: Begriffe, die sich auf Personen beziehen, Ereignisse in SCRUM und die sog. SCRUM-Artefakte.
Die Rollen innerhalb eines SCRUM-Teams verteilen sich wie folgt:
- Der Product Owner:
Der Product Owner ist – wie der Name schon suggeriert – für das Produkt verantwortlich. Er ist für die Formulierung der Anforderungen und Änderungen der Anforderungen zuständig und priorisiert einzelne Arbeitsschritte. Damit hat er auch die Möglichkeit, das Endprodukt optimal zu gestalten. Wichtig: Der Product Owner ist eine einzelne Person und keine Gruppe!
- Das Entwickler-Team:
Das Entwickler-Team ist für die Umsetzung der Anforderungen verantwortlich. Dabei ist es absolut entscheidend, dass innerhalb des Entwickler-Teams keinerlei Hierarchien oder Gruppen gebildet werden. Die Mitglieder des Teams können zwar spezialisiert sein, aber man arbeitet trotzdem gemeinsam und ist gemeinsam für das Produkt verantwortlich. Dies ist ein entscheidender Unterschied zu der im IT-Betrieb häufig gesehenen „Silobildung“. Bei Silos ist jeder für einen kleinen Teilbereich verantwortlich und soll weder in die Arbeit der anderen Silos involviert werden, noch ist eine „Einmischung“ von außen gewünscht.
- Der SCRUM Master:
Der SCRUM Master stellt, grob gesagt, die Schnittstelle zwischen Product Owner und Entwickler-Team dar. Er stellt sicher, dass das Entwickler-Team die Anforderungen des Product Owner versteht. Im Gegenzug muss er auch dafür sorgen, dass der Product Owner die Sichtweise der Entwickler versteht.
Diese Personen nehmen an einem oder mehreren der folgenden SCRUM-Events teil:
- Der Sprint:
Der Sprint ist ein Zeitfenster von wenigen Wochen, in denen eine funktionsfähige Version eines Produkts entsteht. Dabei soll nicht nach dem ersten Sprint das vollständige Produkt fertig sein. Es sollen von Sprint zu Sprint Verbesserungen an der funktionsfähigen Version stattfinden, die sogenannten „Increments“. Die führen am Ende zu einem vollständigen, funktionsfähigen und qualitativ hochwertigen Produkt.
- Der „Daily SCRUM“:
Ein täglich reserviertes, typischerweise 15-minütiges Zeitfenster, an dem die Arbeit für den nächsten Tag geplant wird. Dabei wird auch auf die Ergebnisse des letzten Tages sowie auf mögliche Herausforderungen bei der Erreichung des Sprint-Ziels hingewiesen.
- Der „Sprint-Review“:
Wie der Name vermuten lässt, handelt es sich hierbei um einen Rückblick auf einen abgeschlossenen Sprint. Es wird darauf eingegangen, welche Ziele erreicht wurden und welche nicht, sowie auf eventuelle (unerwartete) Herausforderungen. Zusätzlich werden ggf. Änderungen in den Anforderungen diskutiert sowie der Zeitplan und das Budget überprüft.
Zudem sollen noch der „Product Backlog“ und der „Sprint Backlog“ erwähnt sein. Der „Product Backlog“ enthält alle Aufgaben, die für die vollständige Entwicklung eines Produkts notwendig sind. Für den „Product Backlog“ ist ausschließlich der Product Owner verantwortlich.
Der „Sprint Backlog“ wird für jeden Sprint neu definiert und beinhaltet diejenigen Elemente des Product Backlog, die das Team im nächsten Sprint erledigen will. Wichtig dabei: Der „Sprint Backlog“ kann sich bei unvorhergesehenen Ereignissen auch während des Sprints verändern!
Zur Veranschaulichung: Ein typischer Sprint-Ablauf ist in Abbildung 4 dargestellt.
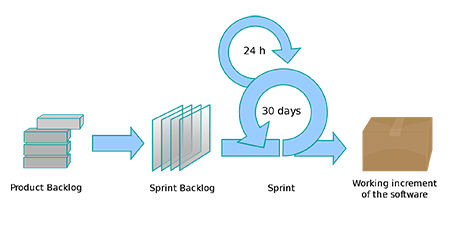
Abbildung 4: Typischer Ablauf eines Sprints: Auswahl von Aufgaben aus dem Product Backlog für den Sprint Backlog, Sprint mit „Daily SCRUMS“ und das aus dem Sprint entstandene Ergebnis, der Increment
Es gibt noch einige weitere Punkte im Umfeld von SCRUM, die aber den Rahmen dieses Artikels sprengen würden. Der Kernpunkt von SCRUM ist, dass alle Beteiligten offen und transparent mit ihren Aufgaben, Ergebnissen und auch Fehlern umgehen, ohne dabei einen Schuldigen zu suchen. Durch die zusätzliche, enge Einbeziehung des Kunden in Form des Product Owner kann auch sehr viel schneller auf sich ändernde Rahmenbedingungen eingegangen werden. Beispielsweise bedeutet dies sich ändernde Anforderungen des Kunden durch Änderungen am Markt.
Zusammengefasst stellt SCRUM einen beliebten und erfolgreichen Ansatz dar, einen agilen Entwicklungsprozess zu gestalten, unabhängig von Produkt und Technologie.
Aber wie lassen sich die Ergebnisse eines Sprints erfolgreich umsetzen und in den kurzen Zeitintervallen eines Sprints auch erfolgreich zusammenstellen und testen? Hier können Continuous Integration und Continuous Delivery helfen!
Continuous Integration und Continuous Delivery – Minimierung der Release-Zyklen
Continuous Integration (CI) stellt ein Prinzip dar, in dem der Code der Entwickler mindestens täglich zusammengeführt und gebaut (der „Build“) wird, um eine jederzeit funktionierende Version einer Software zu ermöglichen. Zusätzlich sollen während des Build automatisiert Tests durchgeführt werden, so dass ein Entwickler schnell Rückmeldung über die Funktionsfähigkeit seines Codes erhält.
Die Überlegung hinter dieser Idee: Wenn ein Softwareentwickler aus dem zentralen Code Repository eine lokale Kopie erstellt und auf Basis dieser entwickelt, ist seine lokale Kopie möglicherweise sehr schnell veraltet. Nach wenigen Tagen hat sich vielleicht schon etwas an Funktionen verändert, die er häufig einsetzt. Je agiler die Entwicklung, desto wahrscheinlicher wird diese Änderung. Wenn dann der Code zu einem späteren Zeitpunkt wieder in das Repository zurückfließt, ergeben sich dadurch Inkompatibilitäten und der Entwickler muss seinen Code anpassen. Also: Neue Kopie, Anpassungen und wieder zurück in das Code Repository. Je nach Aufwand für die Änderungen ist seine lokale Kopie eventuell wieder veraltet. Haben nun mehrere Entwickler für verschiedene Komponenten eine ähnliche Herangehensweise, kann ein erheblicher Mehraufwand entstehen.
Werden die Änderungen der Entwickler häufig in das zentrale Repository zurückgeliefert, minimiert dies die Gefahr von Inkompatibilitäten. Tests gegen den Gesamtcode haben ebenfalls Vorteile gegenüber lokalen Tests der Entwickler: Sie beinhalten Nebeneffekte durch Wechselwirkungen zwischen den einzelnen Abschnitten und Arbeitsschritten verschiedener Entwickler.
Durch diesen iterativen und schnellen Ansatz für den Build und die Tests passt Continuous Integration sehr gut zur agilen Entwicklung und minimiert Fehler durch Inkompatibilitäten.
Das Ergebnis des jeweiligen Build ist eine funktionierende Version der Software und kann theoretisch auch an den oder die Kunden ausgeliefert werden. Damit kommen wir in den Bereich der Continuous Delivery:
Continuous Delivery (CD) ist ein Ansatz der Softwareentwicklung, der darauf abzielt, (quasi) jederzeit ein funktionierendes Produkt ausliefern zu können, statt auf lange Entwicklungs- und Release-Zyklen zu setzen. Das Prinzip ist in Abbildung 5 dargestellt und beschrieben.
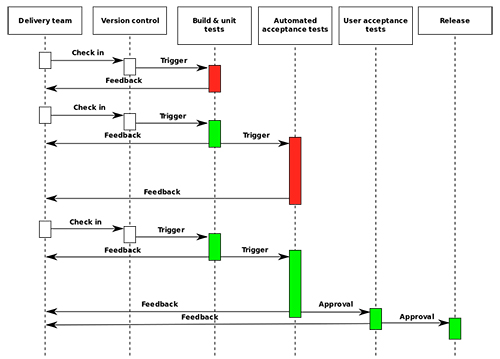
Abbildung 5: Prinzip von Continuous Delivery: Das Delivery-Team nutzt eine Verwaltung für den Code, aus dem automatisiert die Software gebaut wird. Diese Software wird durch automatisierte Tests überprüft und danach für User Acceptance Tests freigegeben. Diese können beispielsweise in Form von „Canary Releases“ bereitgestellt werden.
Wie aus der Abbildung ersichtlich wird, ergeben sich einige Ähnlichkeiten zu Continuous Integration. Insbesondere die Nutzung einer Code-Verwaltung sowie automatisierte Builds und Tests haben wir eben schon bei CI gesehen.
Daher ist die Kombination aus Continuous Integration und Continuous Delivery sinnvoll und durchaus verbreitet. In Kombination ergibt sich daraus die wahrscheinlich bekannte Abkürzung „CI/CD“.
Welche Ansätze und technische Möglichkeiten gibt es, so schnelle Releases, wie sie in der agilen Softwareentwicklung durchaus gewünscht sind, umzusetzen? Eine Aufteilung der Software in kleine Teile, sog. Microservices, passt prinzipiell sehr gut zu CI/CD. Hier sind Inkompatibilitäten zwar unwahrscheinlicher, durch die eventuell unterschiedliche Entwicklungsgeschwindigkeit einzelner Komponenten ist ein Test gegen die Gesamtumgebung sinnvoll. Stellt sich die Frage: Was sind Microservices?
Microservices – Modulare Software für die agile Softwareentwicklung
Ein weiterer Begriff, der im Umfeld moderner Softwareentwicklung und DevOps häufig fällt, ist der Begriff der Microservices. Er wird oft synonym mit Container-Technologie verwendet, was aber der Idee von Microservices nicht ausreichend Rechnung trägt.
Microservices stellen einen Ansatz für eine modulare Softwarearchitektur dar. Dabei wird jede Funktion einer Software von einem eigenen „Microservice“ abgebildet. Diese einzelnen Microservices sind dabei, wie der Name schon sagt, vom Umfang her sehr klein. „Sehr klein“ ist dabei von Produkt zu Produkt und von Funktion zu Funktion relativ flexibel. Es gibt Microservices, die einen vollständigen Webserver darstellen, aber auch solche, die nur eine einzelne mathematische Berechnung durchführen. Es ergibt sich aber immer eine Reihe von grundlegenden Eigenschaften:
- Ein einzelner Service kann einfach und schnell ersetzt werden.
- Jeder Service wird von einem eigenen Team entwickelt, welches die vom Service zur Verfügung gestellten Dienste klar kommuniziert.
- Die zur Verfügung gestellten Dienste sind über definierte Schnittstellen ansprechbar.
Dabei ist wichtig: Die Interna des jeweiligen Services sind vollständig von den Schnittstellen entkoppelt. Dadurch kann theoretisch jeder Microservice in einer anderen für das jeweilige Problem optimal geeigneten Programmiersprache entwickelt oder auch jederzeit durch eine neue Version ersetzt werden. Dem können organisatorisch Grenzen gesetzt werden, um die Komplexität und den Know-how-Bedarf zu reduzieren.
Die eigentliche Anwendung besteht dabei aus der Vernetzung der Microservices. Durch diese ergibt sich ein weiterer, interessanter Vorteil: Sollten Services unterschiedlich skalieren müssen, können sie dies auch individuell.
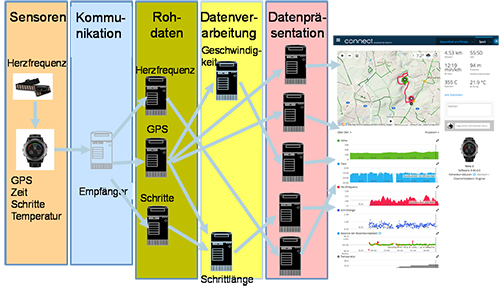
Abbildung 6: Aufbau eines Cloud-Dienstes durch Microservices am Beispiel Fitness-Tracker
Ein Beispiel hierfür sind die Cloud-Dienste für Fitness-Tracker. Diese umfassen eine ganze Reihe von Funktionen. Von der Berechnung der zurückgelegten Strecken über die Anzahl und Weite der eigenen Schritte bis hin zu Abschätzungen des Kalorienverbrauchs und der Darstellung der Informationen. Dabei wird typischerweise jede Aufgabe in Form eines eigenen Microservice realisiert, wie in Abbildung 6 dargestellt.
Microservices erlauben eine Aufteilung von Software in einzelne Bausteine und stellen so eine elegante Möglichkeit dar, Software agil und flexibel auszuliefern und zu skalieren.
Es gilt: Nicht jede Software ist für Microservices geeignet. Gerade bei hohen Performance-Ansprüchen kann der Overhead der Kommunikation zwischen den Services inakzeptabel sein!
Die technische Umsetzung dieser Microservices ist nicht strikt vorgegeben. Sie kann auf Basis von virtuellen Maschinen, Klassen, Unterprozessen oder Ähnlichem realisiert werden und ist nicht auf die Nutzung von Containern angewiesen, auch wenn dies ein sehr häufig begangener Weg ist.
Container – eine erfolgreiche Technologie für den Einsatz von Microservices
Container stellen eine interessante Technologie dar, um Microservices zu realisieren. Dabei werden kleine Dienste in sog. Images geschnürt. Diese Images haben eine gewisse Ähnlichkeit zu den Festplatten-Images virtueller Maschinen, sind aber sehr viel kleiner. Sie beinhalten die eigentliche Software, die gestartet werden soll, sowie etwaige Abhängigkeiten wie z.B. Bibliotheken zur Verschlüsselung.
Sie werden, anders als virtuelle Maschinen, nicht auf einem Hypervisor, sondern direkt auf dem Host-Betriebssystem ausgeführt. Dadurch reduziert sich die Startzeit auf Millisekunden bis wenige Sekunden. Die Isolierung der Container voneinander ist allerdings auch weniger stark als bei virtuellen Maschinen.
Beim Einsatz von vielen Containern und der Nutzung in Produktivumgebungen ergeben sich weitere Anforderungen, zum Beispiel bezüglich Redundanz und Verfügbarkeit. In diesem Fall kommen zusätzliche Tools zum Tragen, die das Management der Container übernehmen, inklusive der Vernetzung. Das wohl bekannteste Tool in diesem Umfeld ist Kubernetes.
Um diesen Artikel nicht mit den Spezifika der Container-Technologie zu überfrachten, sei auf frühere Artikel im Netzwerk Insider verwiesen:
- Die Grundlagen wurden im April 2016 betrachtet [3].
- Die Sicherheitsaspekte und –risiken wurden im Februar 2017 analysiert [4].
- Die Speicheranbindung und die Möglichkeit der „stateful Container“ wurden im Februar 2019 dargestellt [5].
Container und deren Orchestrierungstools bieten eine einfache, ressourcensparende Möglichkeit, Microservices auszuführen. Theoretisch ist es möglich, Software in Containern bereitzustellen, die nicht auf Microservices basiert!
Container-Umgebungen – lieber im eigenen Rechenzentrum, oder der Cloud?
Container haben einige Vorteile für die Bereitstellung von Software. In diesem Zusammenhang hört man immer wieder, wie gut„die Cloud“ für Container-Lösungen geeignet ist. Aber ist das wirklich der Fall? Betrachten wir zunächst die Herkunft der momentan verbreitetsten Container-Verwaltung – Kubernetes. Danach werden einige Vor- und Nachteile einer lokalen bzw. einer Cloud-basierten Container-Lösung dargestellt.
Die wohl bekannteste Lösung zur Orchestrierung und Verwaltung von Containern ist Kubernetes. Es wurde ursprünglich von Google für die eigenen Dienste entwickelt und 2014 als Open Source veröffentlicht. Seitdem hat es einen Siegeszug sowohl in der Cloud als auch in Rechenzentren (RZs) angetreten. Aber welche Lösung ist die richtige für die eigenen Container? Das eigene Rechenzentrum oder die Cloud?
Für das eigene RZ spricht natürlich die Kontrolle, die man dabei hat. Man weiß genau, welche Hardware genutzt wird, man weiß wann und wo die eigenen Daten gespeichert sind und wohin sie fließen. Gerade bei der Verarbeitung von kritischen Daten ist die eigene Kubernetes-Umgebung im eigenen RZ alternativlos.
Eine eigene Lösung hat aber auch ihre Tücken: Die Hardware muss geplant und beschafft, die Software installiert und auf dem neuesten Stand gehalten werden. Außerdem gibt es viele Aspekte, die genau überlegt sein wollen. Das reicht vom Storage für die Umgebung über die eigene Container-Registry, an dem die Images abgelegt werden, bis hin zu Netzwerk-Addons sowie Logging und Monitoring. All diese Punkte müssen dann nicht nur aufgebaut, sondern auch betrieben werden. Das bedeutet große Herausforderungen für nahezu alle Bereiche!
In der Cloud hingegen ist vieles automatisiert. Die notwendigen Systeme sind in Minuten bereitgestellt, und um Updates muss man sich kaum kümmern. Die Umgebungen sind gut aufeinander abgestimmt und der Support vorhanden. Allerdings, wie eben schon erwähnt, gebe ich in der Cloud ein Stück weit die Hoheit über meine Daten ab. Ob das die vereinfachte Installation und das vereinfachte Patch-Management Wert ist, muss im Einzelfall geklärt werden.
Die Entscheidung, ob eine Container-Umgebung lokal oder in der Cloud betrieben werden soll, hängt von vielen Faktoren ab und muss individuell entschieden werden. Sogar hybride Lösungen können sinnvoll sein.
Egal ob Cloud oder eigenes RZ, in jedem Fall will die Lösung jenseits der Installation und des Patch-Managements betrieben werden. In vielen Fällen von den Entwicklern getrieben, liegt der Betrieb der Lösung aber meist in einem anderen Bereich, der sich mit der Technik erst vertraut machen und diese beherrschen muss. Zwar sind in den meisten Fällen die Entwickler in der Lage, die Umgebung zu betreuen. Aus dem „sonstigen“ Betrieb oder der IT-Sicherheit hört man häufig den Einwand, dass der Bereich Entwicklung eventuell für diese Aufgabe nicht die richtige Sichtweise hat.
Genau an diesem Punkt setzt DevOps ein. Die Betreuung einer Container-Umgebung ist dabei ein Paradebeispiel. Auch bei anderen Entwicklungs- und Betriebsmodellen kann DevOps helfen.
DevOps – ein Mindset, keine Technologie!
Nach all diesen Begriffsklärungen und der Auflösung von Beziehungen zwischen den Begriffen kommen wir jetzt zum eigentlichen Kernpunkt: DevOps.
So sehr einige der Begriffe im Umfeld von DevOps technisch geprägt sind, so wenig hat DevOps an sich mit einer bestimmten Technologie zu tun. DevOps ist eine Philosophie und eine Organisations- und Betriebsmethode. Die grundlegende Idee lässt sich am ehesten bei einem Vergleich mit SCRUM erläutern:
SCRUM dient dazu, die Kommunikation mit dem Kunden zu optimieren und den Graben zwischen dem Kunden und den Entwicklern zu schließen. Was auch immer die Entwickler produzieren, muss zumindest intern getestet und dem Kunden demonstriert werden.
Dafür ist Infrastruktur notwendig, die in vielen Fällen von einem separaten Betriebsteam verwaltet wird, das seinerseits wieder aus verschiedenen Bereichen besteht. Ist das bei Ihnen nicht der Fall, sondern arbeiten bei Ihnen Entwickler und Betrieb Hand in Hand, eventuell in Form eines gemeinsamen (agilen) Teams, dann haben Sie die Grundidee von DevOps schon umgesetzt. Doch wie kann man diesen Punkt erreichen? Dazu zwei Extrembeispiele aus dem Projektgeschäft der ComConsult:
Zunächst ein Negativbeispiel: Um DevOps in einer „Silo-Umgebung“ umzusetzen, reicht es nicht, dass von oben bestimmt wird: „Wir sind jetzt agil und wir machen jetzt DevOps!“. Es gibt Beispiele aus unseren Projekten, wo genau das gemacht wurde, aber die Mitarbeiter, die das Ganze „ausbaden“ durften, nicht wirklich involviert wurden. Das Ergebnis waren unzufriedenere Teams, da jeder das Gefühl hatte, dass sich viel zu viele Kollegen aus anderen Bereichen einmischen.
Wir haben auch schon das Gegenteil erlebt: Entscheidungsfinder waren sich voll und ganz darüber im Klaren, dass die DevOps-Philosophie zuallererst von den Mitarbeitern getragen werden muss. Dazu wurden gemeinsame Workshops mit allen Teams abgehalten. Dabei konnten die einzelnen Bereiche darstellen, wo die Herausforderungen ihres Alltags waren, was sie von den anderen Abteilungen erwarten oder benötigen und was sie sich von DevOps erhoffen. Bei diesen Workshops kommen immer wieder falsche oder überzogene Erwartungen heraus, die man gemeinsam und frühzeitig adressieren muss, um ein optimales Gesamtverständnis zu erreichen. Zusätzlich trifft man hier auf Punkte, die für eine erfolgreiche Umstellung auf DevOps hinderlich sind:
- Konflikte zwischen den Teams: In vielen, vor allem historisch gewachsenen, Organisationsstrukturen haben sich im Laufe der Jahre Rivalitäten gebildet. Zum Beispiel wird im Fehlerfall häufig eine Abteilung für vieles verantwortlich gemacht, obwohl eine genaue Überprüfung meist eine andere Ursache zeigt. Oder eine Abteilung hat das Gefühl, „am Ende der Nahrungskette“ zu sein. Das heißt, diese Abteilung schafft die Voraussetzungen für verschiedenste Projekte und Produkte, wird aber kaum wahrgenommen oder wertgeschätzt.
- Durch eine engere Zusammenarbeit, bis hin zur völligen Auflösung der alten Teams, haben einige Mitarbeiter Angst, nicht mehr gebraucht zu werden, und wehren sich deshalb gegen Umstrukturierungen.
Diese beiden Aspekte stellen die größten Herausforderungen dar. Wie geht man damit um?
- Die internen Konflikte lassen sich durch Gespräche, Teambildungsmaßnahmen und viel Verständnis lösen. Dies ist mehr eine psychologische Arbeit als alles andere!
- Die Angst, nicht mehr gebraucht zu werden, lässt sich mit sachlichen Argumenten entkräften. Nur weil die Organisationsstruktur verändert wird und eventuell neue Tools eingeführt werden, verringert das nicht die Arbeitslast. Aus der Erfahrung der ComConsult lässt sich sagen, dass sich die Aufgaben zwar ändern, aber selten weniger Arbeit vorhanden ist. Neue betriebliche Situationen erlauben meist eine Verbesserung des Service und mehr innovative Projekte, die das Unternehmen als Ganzes voranbringen können.
In diesem Zusammenhang ähnelt die Einführung von DevOps den betrieblichen Aspekten bei der Einführung von hyperkonvergenter Infrastruktur oder der Umstellung auf ein „Software-Defined Data Center“, wie es im Oktober 2019 im Netzwerk Insider beschrieben wurde [6]. Es kommen nur zusätzlich die Entwickler mit ins Boot.

Abbildung 7: DevOps als Brücke zwischen Entwicklung und Betrieb, analog zu SCRUM als Brücke zwischen Kunden und Entwicklung
Damit ergibt sich für DevOps eine ähnliche Rolle wie für SCRUM: Statt Brücken zwischen Kunde und Entwickler zu bauen, baut DevOps Brücken zwischen Entwicklern und Betrieb und sogar zwischen verschiedenen Abteilungen innerhalb des Betriebs. Damit ergibt sich das in Abbildung 7 dargestellte Prinzip.
Unterstützung von DevOps durch Technologien
Hat man einmal die Philosophie hinter DevOps verstanden und entsprechende Prozesse und Strukturen etabliert, will man diese technisch unterstützen. Neben den Containern, die in diesem und anderen Artikeln ( [3], [4], [5]) schon beschrieben wurden, gibt es eine ganze Reihe von Tools, die laut Hersteller für DevOps geeignet sind oder DevOps vereinfachen. Die eigentliche Kernfunktion der Tools kann dabei sehr unterschiedlich sein. Eine umfassende Betrachtung der häufigsten und bekanntesten Tools ist leider zu umfangreich, um sie in einem einzelnen Artikel darzustellen. Daher sollen im Folgenden nur grundlegende Ideen hinsichtlich der Tool-Auswahl für DevOps beschrieben werden.
Zunächst findet bei der Tool-Auswahl häufig die Vermengung der verschiedenen Begriffe statt. Weil einige Tools als besonders DevOps-freundlich beworben werden, oder im Extremfall als das Dev-Ops-Tool, werden viele unterschiedliche Aspekte vermischt.
All die in diesem Artikel aufgeführten Philosophien, Techniken und Begriffe haben ihren Platz in einer DevOps-Umgebung und können durch unterschiedliche Tools unterstützt werden. Für jemanden, der in diesem Bereich noch wenig Erfahrung hat, ist diese Vermischung durchaus verständlich.
Eine detaillierte Betrachtung muss dieses anfänglich erwähnte Gewirr aus Begriffen genau differenzieren. Dazu gehört nicht nur die Begriffsklärung, wie sie verkürzt in diesem Artikel dargestellt ist. Eine genaue Analyse der bestehenden Umgebung und der bekannten, vielleicht schon im Einsatz befindlichen Tools ist hier enorm wertvoll. In vielen Unternehmen werden bereits Tools eingesetzt, die DevOps unterstützen können, wenn die Organisation sich darauf einlässt. Hier sind Workshops zur Ist-Analyse sehr wertvoll, um unnötige Investitionen und Mehraufwand zu vermeiden.
Ein Beispiel:
Sie nutzen bereits erfolgreich ein Orchestrierungstool für Ihre Infrastruktur, haben es aber seinerzeit nicht mit dem „Ziel“ DevOps angeschafft. Beim Übergang zu DevOps stoßen Sie nun auf Tools, die explizit mit ihrer „DevOps-Kompatibilität“ werben, deren Kernfunktionen identisch mit der schon bestehenden Lösung sind. Ist es da wirklich sinnvoll, eine neue Lösung einzukaufen, zu implementieren und zu betreiben, inkl. des notwendigen Know-how-Aufbaus? Hier ist eine vorhergehende genaue Analyse der richtige Weg.
Es gibt unzählige Tools zur Unterstützung von DevOps. Welche die richtigen für ein Unternehmen sind, ist eine sehr individuelle Frage, die nur gemeinsam mit allen Stakeholdern beantwortet werden kann.
Hier ist eine Zusammenarbeit aller Beteiligten der Schlüssel, ähnlich wie es bei der Umsetzung von DevOps im Unternehmen ist.
Fazit
Agile Entwicklung und DevOps können ein Unternehmen bei der Softwareentwicklung und beim Ausrollen der Software unterstützen, indem sie
- die Entwicklung flexibler mit den sich ändernden Anforderungen der Kunden umgehen lässt,
- es den Entwicklern ermöglicht, in kürzeren Abständen funktionsfähige Software-Versionen bereitzustellen,
- den eigentlichen Betrieb enger mit den Entwicklern verzahnt und gemeinsame Ansätze zur Bereitstellung von Software ermöglicht und
- alte Rivalitäten und Verständnisschwierigkeiten zwischen Abteilungen und Kollegen reduziert.
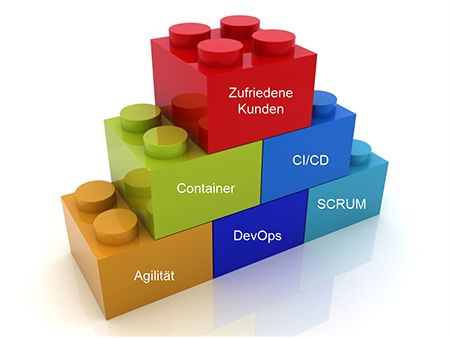
Abbildung 8: DevOps als Grundbaustein für Technologie und Prozesse
Dabei ist aber die Quelle von „gutem“ DevOps nicht eine Technologie oder Software, sondern ein Mindset, das von allen Betroffenen geteilt werden muss. DevOps kann nicht von heute auf morgen von oben befohlen, sondern muss von Tag 1 mit allen Beteiligten gemeinsam geschaffen werden!
Das heißt: DevOps und Agilität sind die Grundsteine einer erfolgreichen, kundenorientierten Entwicklung, auf denen Tools und Prozesse aufbauen, die am Ende gute Software und zufriedene Kunden hervorbringen, wie in Abbildung 8 dargestellt.
Verweise
[1] J. Suppan, „Herausforderung Agilität,“ Der Netzwerk Insider, Oktober 2016.
[2] K. Beck, M. Beedle, A. van Bennekum, A. Cockburn, W. Cunningham, M. Fowler, J. Grenning, J. Highsmith, A. Hunt, R. Jeffries, J. Kern, B. Marick, R. C. Martin, S. Mellor, K. Schwaber, J. Sutherland und D. Thomas, „Manifest für Agile Softwareentwicklung,“ 2001. [Online]. Available: http://agilemanifesto.org/iso/de/manifesto.html. [Zugriff am 25 Mai 2020].
[3] M. Schaub, „Container: Hire and Fire im Rechenzentrum,“ Der Netzwerk Insider, April 2016.
[4] S. Hoff, „Sicherheitsrisiko Container?,“ Der Netzwerk Insider, Februar 2017.
[5] S. Muthmann, „Persistenter Speicher für Container – Microservices jetzt auch stateful,“ Der Netzwerk Insider, Februar 2019.
[6] M. Ermes und C. Höchel-Winter, „Konsolidierung im Rechenzentrum weitergedacht – Converged und Hyperconverged Infrastructure,“ Der Netzwerk Insider, Oktober 2019.
