Failover
Georedundanz ist eine häufige Forderung bei dem Betrieb von Rechenzentren. Folgt man dem Bundesamt für Sicherheit in der Informationstechnik (BSI) so soll die Entfernung zwischen zwei georedundanten Rechenzentren mindestens 200km und in speziellen Ausnahmefällen zwischen 100km und 200km liegen. Wie in dem Blog Artikel „RZ-Georedundanz: kurze oder lange Entfernung?“ [3] von Dr. Moayeri sehr schön herausgearbeitet, stellt diese Bedingung Rechenzentrumsbetreiber vor ein Problem: durch die hohe Latenz, die sich aus dieser Entfernung ergibt, ist es schwer bis unmöglich die Daten in den Rechenzentren synchron zu halten.
Als Lösung schlägt Dr. Moayeri vor, drei Rechenzentren zu betreiben: zwei, die nahe beieinanderliegen und die meisten Ausfälle abfangen können (bspw.: Stromausfall in einem RZ) und eines als Backup für den Fall, dass es zu einem regionalen Problem kommt, das beide aktiven RZs betrifft (bspw.: regionaler Stromausfall).
Diese Architektur lässt sich sehr gut auf die Cloud übertragen. Innerhalb einer Region betreiben die meisten Cloud-Provider mehr als ein Rechenzentrum, Availability Zones genannt. Diese sind jedoch relativ nah beieinander. Von den Providern gehostete Datenbanken (Database as a Service, DBaaS) können beispielsweise IP-Adressen aus allen Availability Zones derselben Region zugeordnet werden. Zudem kann man oft auch gezielt Replikationen einer Datenbank in unterschiedlichen Zonen hosten lassen. Die Daten-Synchronität der Anwendungen in unterschiedlichen Availability-Zonen wird somit vom Provider innerhalb der angebotenen Service Level Agreements (SLA) gewährleistet.
Die Forderung des BSI nach größerer Distanz kann man mit der Cloud dadurch erfüllen, dass man in unterschiedlichen Regionen des Cloud-Providers virtuelle Netzwerke aufbaut und Anwendungen und Daten zwischen diesen Regionen synchronisiert. Betreibt man eine Region als Backup, so kann man zwar die Daten-Synchronität wegen der Latenz nicht durchgängig garantieren, jedoch ist man BSI-konform und auch gegen größere Katastrophen gewappnet.
Was hat das jetzt mit DNS zu tun?
Es reicht nicht, die Anwendungen 3x vorzuhalten und die Daten zu synchronisieren. Um einen Ausfall auffangen zu können, muss man auch dafür Sorge tragen, dass die Anwendung weiterhin erreichbar bleibt. An dieser Stelle nun greift das regelbasierte DNS der Cloud Provider. Unter dem Schlagwort „Failover-Routing“ bietet AWS die Möglichkeit, den DNS-Dienst, Route 53 genannt, mit einer Funktionsüberwachung zu kombinieren. [4] D.h. vom DNS werden nur IP-Adressen zu solchen Diensten publiziert, die auch wirklich erreichbar sind.
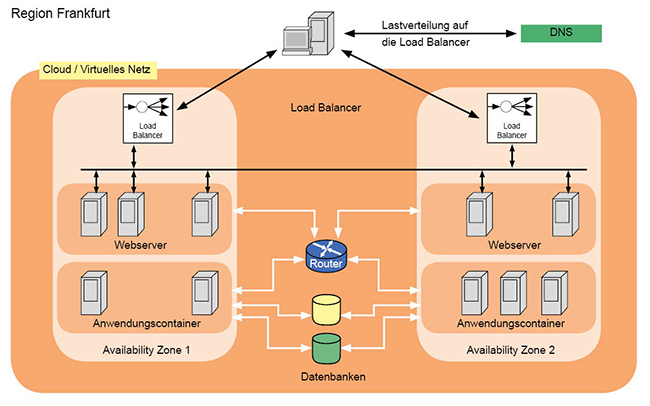
Abbildung 3: Redundanz innerhalb einer Cloud-Region
Damit kann man die von Dr. Moayeri vorgeschlagene Architektur perfekt umsetzen:
- Im ersten Schritt (Abbildung 3) baut man innerhalb einer Cloud-Region eine redundante Struktur verteilt auf zwei Availability-Zonen auf.
Um die Daten redundant und synchron zu halten, kann eine vom Provider gehostete Datenbank genutzt werden. Dabei wählt man dann die Option „Automatische Datenreplikation“ oder aber wählt von vornherein eine Datenbank, die immer mit einer automatischen Redundanz daherkommt, wie beispielsweise Amazons „Aurora“ Datenbank. [5]
- Die eigenen Anwendungen verteilt man so auf beide Availability-Zonen, dass jede für sich autark arbeiten kann.
- Wenn nötig, werden innerhalb der Availability-Zonen Load Balancer genutzt, um die Last zu verteilen. Dabei kann diese die Last auch über die eigene Zonengrenzen hinweg verteilet werden.
- Da Load Balancer einer Availability-Zone zugeordnet sind, fallen diese auch aus, wenn die ganze Zone ausfällt. Das unterscheidet sie grundsätzlich vom DNS. Deswegen werden von außen kommende Anfragen per DNS auf die Load Balancer aufgeteilt.
- Der DNS-Dienst selbst kann wiederum so konfiguriert werden, dass er die Funktion der Load Balancer überwacht. Bei einem Ausfall wird nur noch die IP-Adresse des weiterhin aktiven Load-Balancers an die Clients weitergeleitet.
- Da DNS-Anfragen von Clients und anderen DNS-Servern gecachet werden, sollten die Timer der DNS-Einträge hinreichend klein gewählt werden.
- Wird der ausgefallene Load Balancer wieder aktiv, wird das DNS seine Adresse nun auch wieder aktiv propagieren.
Diese Art des Failover-Routings nennt sich „active/active“, da beide Availability-Zonen gleichzeitig aktiv sind und ihnen auch Client-Anfragen weitgeleitet werden.
Abbildung 4 zeigt den zweiten Schritt hin zur vollständigen Georedundanz:
- Zusätzlich zur primären Region nimmt man eine zweite Region des Cloud-Providers hinzu, die den Anforderungen der Georedundanz genügt. Im Beispiel wären das die beiden Regionen Irland und Frankfurt, die beide deutlich mehr als 200km voneinander entfernt liegen.
- In Irland wird nun dieselbe Anwendung wie in Frankfurt in Betrieb genommen. Hierbei sollte eine Güterabwägung getroffen werden. Da man Irland nur als Notfall-Backup betreibt, wird es in vielen Fällen ausreichen, wenn die Anwendung dort nicht genau so skaliert wie in Frankfurt. Dadurch wird eine signifikante Einsparung möglich. Im Beispiel wurde auf die Redundanz innerhalb der Irland-Cloud verzichtet.
- Die Daten werden zwischen den beiden Regionen synchron gehalten, zumindest soweit es die Latenz zulässt. Dabei kann man auf die von den Providern angebotenen Verbindungstypen zurückgreifen, um eine möglichst geringe Latenz, hohen Durchsatz und Datensicherheit zu erreichen.
Da Irland nur aktiv werden soll, wenn Frankfurt ausfällt, wählt man bei der DNS-Failover-Konfiguration in diesem Fall die Option „active/passive“ aus, wobei Frankfurt aktiv und Irland passiv ist.
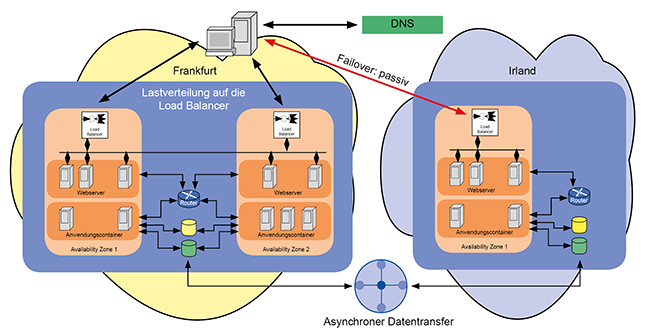
Abbildung 4: Georedundanz mit der Cloud und DNS-Failover
Die Failover-Funktionalität des DNS-Dienstes lässt sich natürlich nicht nur nutzen, um Georedundanz zu verwirklichen. Wann immer man Dienste überwachen möchte und bei deren Ausfall auf eine Alternative wechseln will, kann man diese Funktion in Betracht ziehen. Dabei sollte man allerdings stets überprüfen, ob es nicht andere, sinnvollere Alternativen gibt. Beispielsweise können Load Balancer die Webserver monitoren und bei Bedarf sogar weitere hinzunehmen oder überflüssige herunterfahren. Damit geht deren Kontrolle weit über die des DNS-Failover hinaus. Man ist also gut beraten, bei seinem Cloud-Provider für eine bestimmt Anforderung alle Optionen zu recherchieren und gegeneinander abzuwägen.
Gewichtetes DNS
Im Georedundanz-Beispiel in Abbildung 3 wurden die beiden Availability-Zonen gleichzeitig aktiv betrieben. Nun kann es sein, dass man die Anfragen zwar auf unterschiedliche Instanzen verteilen möchte, jedoch nicht im selben Maße. Beispielsweise möchte man ein neues Design seines Webauftritts testen und sehen, wie gut es ankommt, oder ob man es besser bleiben lassen möchte. [6]
Abbildung 5 zeigt, wie das umgesetzt werden kann:
- Neben dem Server mit dem aktuellen Webdesign, wird ein neuer Server mit dem neuen Design in Betrieb genommen.
- Beide Server bekommen denselben Namen.
- Im DNS wird eine Regel eingeführt, dass der Server mit dem neuen Design jeden 10. Client zugewiesen bekommen soll.
- Die Marketing-Abteilung muss dann Mittel und Wege finden, aus den Logfiles die gewünschten Statistiken zu erzeugen.
Der Wunsch, DNS-Anfragen zu nutzen, um eine gewichtete Lastverteilung zu erreichen, ist nicht neu. Bereits mit der Einführung des Server-Records (SRV-Record) wurde genau diese Möglichkeit im DNS eingeführt. [7] Das Problem ist jedoch, dass SRV-Records von Clients nicht genutzt werden, um simple Adressabfragen vorzunehmen. Dafür wird nur die schlichte Adress-Auflösung (A-Record) genutzt, die diese Funktion nicht aufweist.
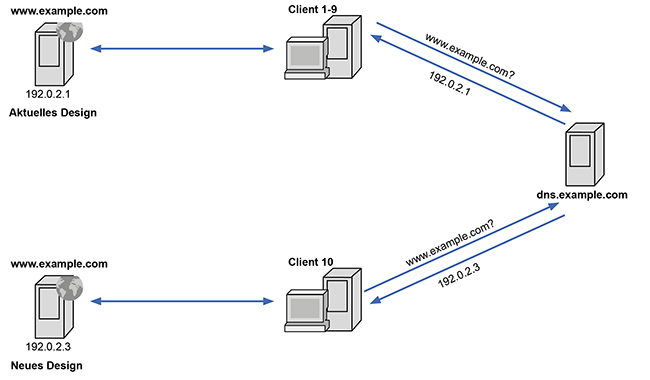
Abbildung 5: A/B-Test mittels gewichtetem DNS
Die Cloud-Provider können diese Gewichtung dadurch erreichen, dass sie Server-seitig einfach jede 10. Anfrage mit einer anderen IP-Adresse beantworten als die anderen 9. Bei einer großen Menge an Anfragen sollte sich so eine entsprechend gewichtete Verteilung ergeben.
Für die Gewichtung gilt, was bereits für das Failover galt: es gibt meist Alternativen. Anders als beim Failover, das bei einigen Lösungen die beste Variante ist, existieren für eine gewichtete Lastverteilung fast immer deutlich bessere Lösungen. Allerdings spricht für das DNS, dass es bei kleinen Umgebungen oftmals die kostengünstigste Variante ist: so ist es deutlich preiswerter den oben beschriebenen Test mittels DNS zu realisieren, als nur dafür einen sonst nicht benötigten Load Balancer in Betrieb zu nehmen.
Latenzbasiertes Routing
Bereits beim Beispiel der Georedundanz wurde eine Anwendung in zwei Regionen installiert. Dabei war eine jedoch rein als Backup vorgesehen. Für Unternehmen, die weltweit Kunden haben, die auf ihre Anwendungen zugreifen, wird das jedoch nicht ausreichen. Vielmehr werden diese ihr Angebot in weltweit verteilten Regionen anbieten wollen, um den Anwendern ihre Anwendungen möglichst performant anbieten zu können. Das ist nun mal nicht möglich, wenn man es mit Latenzen zu tun hat, die allein durch die Physik bei der Übertragung von Japan nach Europa entstehen.
Für die Verteilung statischer Inhalte kann man in solchen Fällen auf die Content Delivery Networks (CDN) zurückgreifen. Bei dynamischen Inhalten ist das hingegen nicht möglich. Dafür benötigt man andere Lösungen.
Gerade für Anwendungen, die man per Browser ansteuert, aber auch für Apps auf Smartphones oder Tablets gilt, dass der Dienst per Namen gesucht und dann per IP abgerufen wird. Der User ist jedoch gewöhnt, stets auf dieselbe Domain zuzugreifen, also beispielsweise example.com, egal ob er in Brasilien oder auf Spitzbergen ist. Das traditionelle DNS wird für example.com jedoch unabhängig vom Abfrageort immer dieselbe Antwort liefern. Um dem Nutzer eine möglichst performante Anwendungserfahrung zu bieten, sollten seine Anfragen in die nächstgelegene Cloud geroutet werden.
Hierfür bieten die Cloud-Provider „latenzbasiertes“ oder auch „leistungsorientiertes“ Routing an. [8] Gemeint ist damit kein IP-Routing, sondern vielmehr, dass das DNS eine latenzbasierte Antwort bekommt. Im Beispiel bekommt der Nutzer in Brasilien die IP-Adresse der Anwendung, die diese in der Cloud in Rio hat, der Nutzer aus Spitzbergen die IP-Adresse aus London.
Um das zu realisieren, pflegen die Cloud-Provider Latenz-Datensätze. Diese geben an, wie hoch die Latenz zwischen den Cloud-Standorten und dem anfragenden Client ist. Als IP-Adresse bekommt der Client diejenige genannt, die die geringste Latenz zwischen ihm und der Cloud darstellt.
Abbildung 6 zeigt schematisch, wie man sich das vorstellen kann:
- Ein User ruft eine Anwendung auf, die in den Regionen Sydney, Vancouver und Irland verfügbar ist.
Das DNS stellt anhand der IP-Adresse des vom User genutzten rekursiven DNS-Servers fest, dass dieser auf Madagaskar ist.
- Das DNS berechnet nun die schnellste Verbindung zu der gesuchten Anwendung. Das Ergebnis im Beispiel wäre Irland.
- Der Client bekommt die IP-Adresse der Anwendung in Irland genannt.
Es ist wichtig, dabei im Hinterkopf zu haben, dass diese Latenz-Datensätze aus Algorithmen des Cloud-Providers stammen, die ständig aktualisiert werden. Deshalb kann es passieren, dass User nicht immer dieselbe IP-Adresse für dieselbe Cloud genannt bekommen, obwohl die User sich nicht von der Stelle bewegen. Nehmen wir im Beispiel an, dass es ein neues Unterseekabel zwischen Kapstadt und Sydney gibt: dann wäre diese Verbindung womöglich schneller als die alte nach Irland.
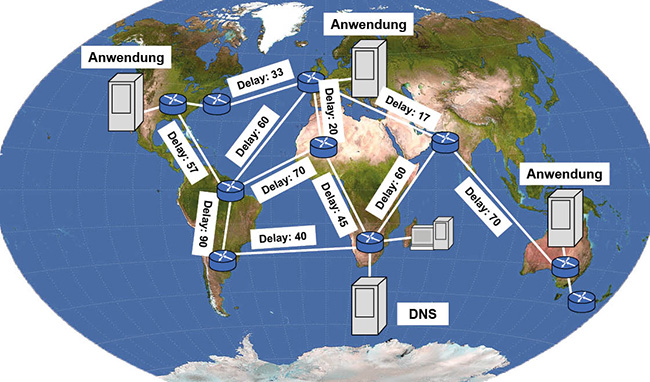
Abbildung 6: Latenzbasiertes DNS-Routing Quelle: NASA Earth Observatory (NASA Goddard Space Flight Center) [Public domain]
Arbeitet man nur mit wenigen Regionen, kann das dazu führen, dass es bei einer geringen Verschiebung der Latenz-Datensätze zu einer massiven Umverteilung der Anfragen nach einer eigenen Anwendung kommt. Nehmen wir an, man betreibt zwei Cloud-Regionen, eine in Europa und eine in Nord-Amerika. Durch ein neues Unterseekabel wird die Verbindung zwischen Indien und Amerika plötzlich schneller als die bislang favorisierte Strecke Indien-Europa. Dann greifen über 1,3 Milliarden potenzielle Kunden plötzlich auf ein anderes Rechenzentrum zu.
Arbeitet man also mit dieser Variante des DNS, dann sollte man die Zugriffsverteilung auf die Cloud-Regionen monitoren und sein Angebot ggf. anpassen.
Geolokalisierung
Neben latenzbasiertem DNS-Routing gibt es noch eine ähnliche Variante: das DNS-Routing auf Basis der Geolokation. [9]
Das Prinzip ähnelt dabei dem des latenzbasiertem Routings:
- Ein Client fragt die IP-Adresse zu einem DNS-Namen ab.
- Der DNS-Server ermittelt anhand der IP-Adresse des rekursiven DNS-Servers den ungefähren Standort des Clients.
- Gemäß einem hinterlegten Regelwerk liefert er dem Client dann eine entsprechende Antwort zurück. Kommt die Anfrage aus einem EU-Land, bekommt er die IP-Adresse der Anwendung in Frankfurt, der Rest der Welt bekommt eine IP-Adresse aus Ohio.
Dabei muss einem klar sein, dass dieses Verfahren keine Lösung für die Verarbeitung personenbezogener Daten gemäß der Datenschutzgrundverordnung (DSGVO) ist. Zwar kann man so die Daten innerhalb der EU halten, solange der Client sich ebenfalls in der EU befindet. Sobald er jedoch den Rechtsraum der EU verlässt, kann es je nach Standort passieren, dass er auf die Anwendung in einer völlig anderen Cloud zugreift.
Abbildung 7 zeigt, wie eine DSGVO-konforme Lösung aussehen kann, selbst wenn man mit geolokalisiertem DNS-Routing arbeitet: [10]
- Daten, die nicht personenbezogen sind, werden weltweit in alle genutzten Cloud-Regionen synchronisiert.
- Kritische Daten verbleiben in den europäischen Standorten.
- Greift ein User nun in Australien auf die Anwendung zu, so wird seine Anfrage zunächst nach Sydney geroutet.
- Von dort werden dem User auch alle unkritischen Daten übertragen.
- Es liegt dann in der Verantwortung der Softwareentwickler ggf. in Zusammenarbeit mit den Netzwerkern eine Lösung zu finden, wie die kritischen Daten von den europäischen Rechenzentren DSGVO-konform aus Europa zu dem Anwender übertragen werden.
Zwar kann geolokalisiertes DNS-Routing einem bei der DSGVO nicht weiterhelfen, jedoch kann es eine Alternative zum latenzbasierten Routing sein. Bei Letzterem obliegt es dem Cloud-Provider, die notwendigen Latenz-Daten auszuwerten. Wie bereits beschrieben, kann es dabei auch von heute auf morgen passieren, dass sich Verkehrsflüsse ändern. Beim gelokalisierten Routing hingegen kann der Cloud-Anwender selbst den Einzugsbereich der jeweiligen Cloud-Regionen festlegen.
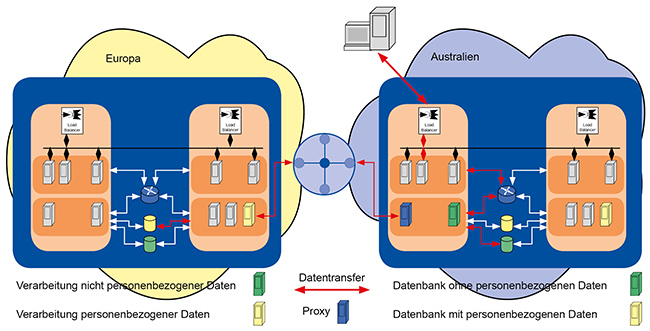
Abbildung 7: DSGVO-konforme Lösung trotz geolokalisiertem DNS-Routing
Pferdefuß: Kosten!
Es muss einem klar sein, dass man bei vielen der vorgestellten DNS-basierten Architekturen die benötigten Ressourcen in allen betriebenen Cloud-Regionen auch verfügbar haben muss. Das erzeugt natürlich zusätzliche Kosten:
- Benötigte Ressourcen
Die genutzten Dienste wie VMs, Container, Load Balancer, Datenbanken usw. müssen in allen Regionen betrieben werden. Je nach Ausrichtung des Angebotes muss das nicht im selben Umfang sein wie in der Hauptregion. In welcher Region wie viele Ressourcen bereitgestellt werden müssen, ist bei Cloud-Anwendungen primär eine Frage der Kostenprognose, weniger des Betriebs. Skalierbarkeit ist eine der Stärken der Cloud, so dass bei vernünftiger Planung die benötigten Ressourcen automatisch oder aber zumindest mit wenigen Klicks zur Verfügung gestellt werden können.
- Verkehr zwischen den Regionen
Für die Synchronisation der Daten fällt zwischen den Cloud-Regionen Verkehr an. Anders als das regionsinterne Verkehrsvolumen, das oft kostenfrei ist, fallen für die Übertragung zwischen den Regionen Kosten an, die sich nach dem übertragenen Volumen richten.
- Wer also allzu arglos Backup-Daten zwischen Cloud-Regionen transferiert, so wie es oft zwischen Rechenzentren über Dark-Fibers in der Nacht passiert, der kann schnell immense Kosten verursachen.
- Man sollte auf jeden Fall ein entsprechendes Konzept entwickeln.
- Administration
Betreibt man ein und dieselbe Anwendung in unterschiedlichen Regionen, so muss man sich darüber im Klaren sein, dass dadurch auch die Administrationskosten steigen, da man vieles pro Region wiederholen muss.
Es gibt jedoch Möglichkeiten der „Kostenexplosion“ zumindest bei den Punkten Dienste und Datenübertragung entgegenzuwirken, ohne dass man auf Performance oder Funktion verzichten muss.
DNS und native Cloud-Dienste
Die meisten Angebote enthalten neben dynamischen auch statische Komponenten. Gerade dieser statische Anteil ist oft am speicher- und damit auch übertragungsintensivsten. Beispiele dafür sind Downloads, Videos und Bilder. Dieser mehr oder weniger unveränderliche Content kann auf Objekt-Speichern wie S3 gespeichert werden. Verglichen mit File- oder Blockspeicher von virtuellen Maschinen (VM) kostet diese Speichervariante fast gar nichts. Für die Speicherung sämtlicher Streaming-Videos inklusive der Teaser von ComConsult-Study.tv sowie den Insider-Ausgaben der letzten Jahre zahlen wir zwischen 1,00 US$ und 1,20 US$ pro Monat. Zum Vergleich: für das Elastic File System (EFS), auf dem dieselben Videos für den Download liegen, wenn auch ohne Teaser und Netzwerk Insider, zahlen wir zwischen 15 US$ und 16 US$.
Ein weiterer Vorteil der Speicherung auf Objekt-Speicher ist, dass man diesen Content nun mittels der CDN der Cloud-Provider weltweit ausliefern kann. Dadurch müssen die Dateien nur einmal gespeichert werden und nicht in jeder Region. Trotzdem ist eine performante Auslieferung gewährleistet. In der Regel gibt es bei den Providern auch mehr Standorte für die CDN-Auslieferung als es Regionen gibt. Beispielsweise gibt es aktuell für Cloudfront, das CDN der AWS, 177-Edge-Standorte und 11 regionale für Edge-Cache-Standorte. AWS-Regionen hingegen gibt es „nur“ 23 und das schließt je zwei in China und die US GovCloud mit ein. [11]
Selbstverständlich kann auch das CDN Inhalte via DNS mit der eigenen Domain verknüpfen, so dass es nicht notwendig ist, kryptische Links der Marke „https://d1c7o9ftyas6xeg.cloudfront.net/…“ an die Kunden weiterzugeben, was dem vom CDN vergebenen Namen bei AWS entspräche. Allerdings ist dabei zu beachten, dass man sich in diesem Fall selbst um die Zertifikate für das HTTPS kümmern muss und diese im CDN-Dienst hinterlegt.
Fazit
Es gibt viele weitere Cloud-native Dienste, die mittels DNS so angepasst werden können, dass sie aussehen, als würden sie der eigenen Domain entstammen. Beispiele dafür sind API-Gateways bei der Serverless-Architektur oder auch die Objekt-Speicher-Dienste wie S3. Im Grunde kann man sagen, dass das DNS in der Cloud omnipräsent ist. Darum lohnt es sich nicht nur, sich damit zu beschäftigen, vielmehr ist es dringend geboten.
Allerdings ist das DNS oft nicht die einzige Variante, eine gegebene Aufgabenstellung zu lösen. Häufig finden sich elegantere, besser skalierende oder deutlich günstigere Möglichkeiten, um das Ziel zu erreichen. Darum sollte man bei Cloud-Architekturen zunächst alle Möglichkeiten recherchieren und wenn möglich nach Referenz-Architekturen suchen.
Abkürzungen
A Address
AWS Amazon Web Services
BSI Bundesamt für Sicherheit in der Informationstechnik
CDN Content Delivery Network
DBaaS Database as a Service
DNS Dynamic Name Service
DSGVO Datenschutzgrundverordnung
EFS Elastic File System (Amazon)
GCP Google Cloud Platform
HTTPS Hypertext Transfer Protocol Secure
IP Internet Protocol
NS Name Server
RZ Rechenzentrum
SLA Service Level Agreement
SRV Server
US United States
US$ US Dollar
VM Virtual Machine
Referenzen
[1] Google Public DNS, „FAQ“: https://developers.google.com/speed/public-dns/faq
[2] Cloudflare, „What is round-robin DNS?“: https://www.cloudflare.com/learning/dns/glossary/round-robin-dns/
[3] Dr. Moayeri, ComConsult GmbH, „Georedundanz: kurze oder lange Entfernung?“: https://www.comconsult.com/rz-georedundanz-entfernung/
[4] AWS Dokumentation, „Failover-Routing“: https://docs.aws.amazon.com/de_de/Route53/latest/DeveloperGuide/routing-policy.html#routing-policy-failover
[5] AWS, „Amazon Aurora – Produktdetails“: https://aws.amazon.com/de/rds/aurora/details/
[6] AWS Dokumentation, „Gewichtetes Routing“: https://docs.aws.amazon.com/de_de/Route53/latest/DeveloperGuide/routing-policy.html#routing-policy-weighted
[7] RFC 2782, „A DNS RR for specifying the location of services (DNS SRV)“: https://tools.ietf.org/html/rfc2782
[8] Azure Dokumentation, „Leistungsorientierte Methode für das Datenverkehrsrouting“: https://docs.microsoft.com/de-de/azure/traffic-manager/traffic-manager-routing-methods#performance
[9] Azure Dokumentation, „Use DNS Policy for Geo-Location Based Traffic Management with Primary-Secondary Deployments“: https://docs.microsoft.com/de-de/windows-server/networking/dns/deploy/primary-secondary-geo-location
[10] Markus Schaub, ComConsult GmbH, Netzwerk Insider Januar 2019, „Anforderungen von Cloudanwendungen an Netzwerke – ein Beispiel“
[11] AWS Marketing, „Amazon CloudFront-Infrastruktur“: https://aws.amazon.com/de/cloudfront/features/