Unterschiede Fog und Edge
Die Begriffe Fog und Edge Computing werden oft redundant benutzt. Allerdings gibt es mittlerweile eine fest definierte Abgrenzung zwischen den beiden Lösungen. Diese wurde unter anderem vom OpenFog Consortium formuliert.
Das OpenFog Consortium wurde 2015 von ARM, Cisco, Dell, Intel, Microsoft und der Princeton University gegründet und beschäftigt sich sowohl mit technischen Arbeiten rund um Fog Computing als auch mit der Entwicklung von Standards zu dem Thema, zusammen mit dem IEEE.
Fog Computing ist demnach ein Oberbegriff für die Datenvorverarbeitung im lokalen Netzwerk, Edge Computing eine spezielle Form der Datenvorverarbeitung.
Ein Fog Node kennt alle in der Domäne vorhandenen Geräte. Bei Analysen kann auf die anderen Geräte zugegriffen und mit ihnen kommuniziert werden. Fog Nodes können Entscheidungen basierend auf den erhaltenen Daten treffen und sogar geringe Datenmengen zwischenspeichern.
Im Edge hingegen werden lediglich einfache Aufgaben wie das Filtern und Zusammenfassen von Daten ausgeführt. Edge Geräte kennen sich untereinander nicht und interagieren somit auch nicht miteinander.
Fog Nodes sind meistens bereits im Netzwerk vorhandene Geräte, deren Rechenleistung für Analysen genutzt wird. Sie befinden sich in einer zusätzlichen hierarchischen Ebene zwischen den Endgeräten und der Cloud. Edge Computing findet hingegen direkt am oder sogar im Endgerät statt.

Abbildung 2: Beispielhafte Darstellung von Edge Gateways [2]
Ein wichtiger Punkt ist hierbei, dass sich beide Ansätze nicht ausschließen, sondern sehr gut in Kombination verwendet werden können. So können die anfallenden Daten mit Edge Computing gefiltert, zusammengefasst und an den nächsten Fog Node gesendet werden. Eine Fog-Computing-Ebene führt erste Analysen der Daten durch. Alle Aufgaben, die komplexer sind oder aus anderen Gründen nicht im Fog verarbeitet werden können, werden in die Cloud weitergeleitet. Diese hierarchische Darstellung ist in Abbildung 3 dargestellt.
Die Cloud ist weiterhin eine wichtige Struktur, die nicht von Fog Computing abgelöst wird. Sie bietet wesentlich mehr Ressourcen und ist damit für bestimmte Anwendungsfälle geeigneter als Edge oder Fog Computing. Im folgenden Abschnitt werden einige Anwendungsfälle genauer betrachtet.
Use Cases
Das OpenFog Consortium beschäftigt sich neben der Etablierung von Standards und den technischen Arbeiten rund um Fog Computing auch mit der Veröffentlichung von Best Practices im Zusammenhang mit ausgewählten Anwendungsfällen.
Ein solcher Anwendungsfall, in dem sowohl Edge als auch Fog Computing eine wichtige Rolle spielen, ist das autonome Fahren. [3] In einem autonomen Fahrzeug sind über hundert Sensoren verbaut, die dafür sorgen, dass das Auto zum einen Schilder und Fahrspuren erkennt, aber auch rechtzeitig auf Hindernisse reagieren kann. [4] Besonders in letzterem Fall muss das Auto schnellstmöglich reagieren, das heißt der Faktor Echtzeit spielt eine sehr große Rolle. Um nicht auf die Antwort eines entfernt gelegenen Cloud-Servers zu warten, müssen diese Analysen lokal durchgeführt werden, also im Fog.
Zusätzlich müssen die Daten nicht nur in Echtzeit analysiert werden, sondern auch offline. Wenn das autonome Fahrzeug durch einen Tunnel fährt oder aus anderen Gründen vom Netz getrennt ist, müssen sämtliche Systeme genauso funktionieren wie mit einer bestehenden Netzanbindung. Ein weiterer Punkt, der für die Verarbeitung der Daten im Fog spricht.
Darüber hinaus ist es nicht empfehlenswert, die Daten alle sofort in die Cloud zu schicken, sobald das Auto eine Netzverbindung hat. Bei einer schlechten Verbindung kann dies sogar zum Verlust der Daten führen. Ein gezieltes Sammeln und Bündeln ist hier sinnvoll. Das heißt Edge Computing ist im autonomen Fahrzeug genauso wichtig wie Fog Computing.
Ein anderer Anwendungsfall sind, wie bereits erwähnt, Smart Meter. Smart Meter sammeln ebenfalls sehr viele Daten in sehr geringen Abständen, aber ohne dass sie in Echtzeit verarbeitet werden müssten. Diese Daten werden noch im Smart Meter, also im Edge, gesammelt und gefiltert. Bei den meisten Geräten lässt sich konfigurieren, in welchem Abstand diese Daten weitergeleitet werden.
In diesem Fall wäre es zwar auch möglich, hinter den Smart-Metern eine Art Fog-Struktur aufzubauen, aber nicht zielführend. Die Kosten, ein solches Netz aufzubauen, sowie die Komplexität, die dadurch im lokalen Netz entsteht, stehen in keinem Verhältnis zum Nutzen. Es reicht, die Daten zu sammeln und diese anschließend in die Cloud weiterzuleiten.
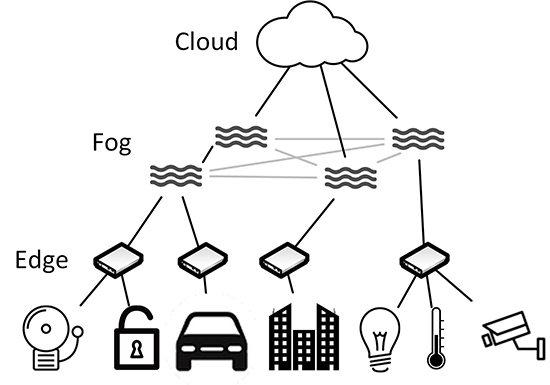
Abbildung 3: Kombination von Fog und Edge Computing
Es gibt zahlreiche weitere Anwendungsfälle, in denen Fog oder Edge Computing empfehlenswert sind, auf die hier nicht weiter eingegangen wird. Darüber hinaus gibt es aber genauso viele Fälle, in denen diese Architekturmodelle nicht zweckdienlich sind, wie beispielsweise Big-Data-Analysen.
Herausforderungen
Soll Fog Computing in einem passenden Anwendungsfall als Architekturmodell verwendet werden, gibt es dennoch einige Herausforderungen, die beachtet werden müssen.
Bei der Erstellung einer Fog-Computing-Lösung ist es empfehlenswert, sich an dem Standard IEEE 1934 von August 2018 oder an dem Conceptual Model von NIST von März 2018 zu orientieren. Beide greifen die vom OpenFog Consortium entwickelte Referenzarchitektur auf. [5] Es werden unter anderem die acht Grundpfeiler definiert, auf denen eine solche Architektur basieren sollte. Diese sind Sicherheit, Skalierbarkeit, Offenheit, Autonomie, RAS (Zuverlässigkeit, Verfügbarkeit, Wartbarkeit), Agilität, Hierarchie und Programmierbarkeit. Sie werden in den Veröffentlichungen genauer erläutert.
Dennoch handelt es sich bei Fog Computing nur um ein Architekturmodell. Es gibt keine fest definierten Techniken, die umgesetzt werden müssen. Vielmehr richtet sich das jeweilige Fog-Netzwerk stark nach dem entsprechenden Anwendungsfall. Wie bereits erläutert, gibt es für einige Anwendungsfälle Best-Practice-Vorschläge vom OpenFog Consortium. Diese beziehen sich aber ebenfalls nur auf Architektur-Lösungen und nicht auf spezielle Techniken zur Umsetzung. Konkrete Lösungsansätze können oft aus dem Cloud Computing abgeleitet werden. Da sich diese aber auch nach dem Anwendungsfall richten, ist es schwierig, eine allgemein gültige Fog-Computing-Lösung bereitzustellen.
Auch bei der Entscheidung, welche Kommunikations-Protokolle zwischen den verschiedenen Ebenen Cloud, Fog, Edge und Endgerät eingesetzt werden, gibt es keine universelle Empfehlung. Auf den Ebenen vom Endgerät zum ersten Fog Node gibt es meistens keine Wahlmöglichkeit. Die jeweiligen Sensoren sind nur in der Lage, über das vom Hersteller definierte Protokoll zu kommunizieren. Hauptsächlich sind dies einfache Protokolle wie ZigBee, Z-Wave, SigFox oder ähnliche, da die Endgeräte möglichst einfach und energiesparend entwickelt werden. Das heißt, dass der jeweilige Fog Node, oder das dazwischen gelegene Edge Gateway mindestens in der Lage sein muss, diese Protokolle zu verstehen und auszuwerten. Auf der nächst höheren Ebene, also zwischen den Fog Nodes oder vom Fog zur Cloud sind diese Einschränkungen nicht mehr vorhanden. Da Fog Nodes leistungsfähiger sind als die Endgeräte, können hier auch komplexere Protokolle wie AMQP (Advanced Message Queuing Protocol) oder Ähnliches genutzt werden. Es kann also das für den Anwendungsfall passendste Protokoll ausgewählt werden.
Zudem gibt es weitere Herausforderungen, die bei der Umsetzung von Fog Computing ebenfalls berücksichtigt werden müssen, zum Beispiel:
- Die für das Fog Computing verwendeten Geräte müssen regelmäßig gewartet und instandgehalten werden.
- Da Fog Computing eine dezentrale Datenverarbeitung ist, muss es ein Management für dezentrale Geräte geben.
- Fog Nodes besitzen im Gegensatz zur Cloud nur limitierte Ressourcen. Es muss vorab definiert werden, welche Aufgaben sinnvoll im Fog verarbeitet werden können und für welche weitere Performance notwendig ist.
- Wenn die Cloud der zentrale Datenspeicher wird, führt die Vorverarbeitung von Daten letztendlich zu einem Datenverlust in diesem Speicher. Dies ist ein wichtiger Punkt, wenn es beispielsweise um Big-Data-Analysen geht. Es muss sichergestellt werden, dass dieser Datenverlust keine negativen Auswirkungen hat.
Die mit dem Fog Computing eingefügte neue Hierarchie-Ebene im lokalen Netzwerk löst folglich zwar sehr viele Probleme, die im Zusammenhang von Cloud Computing und Internet of Things entstehen, aber sie erhöht auch die Komplexität des eigenen Netzwerks.
Hardware und Software
Die Idee des Fog Computing basiert darauf, Geräte zu verwenden, die bereits im Netzwerk vorhanden sind, wie Router, Gateways, Server, etc. Das heißt eine spezielle Hardware wird hier nicht benötigt. Allerdings müssen die bereits vorhandenen Geräte mit entsprechender Software in ein Fog Netz eingebunden werden. Eine solche Software gibt es mittlerweile von sehr vielen Anbietern. Meistens handelt es sich dabei um die Cloud-Anbieter selbst, die es mit Hilfe von entsprechender Software ermöglichen, deren Cloud-Strukturen lokal aufzubauen und eine Vernetzung von der Fog-Ebene in die jeweilige Cloud zu realisieren.
Edge Computing basiert dagegen meistens auf Hardware. In vielen Endgeräten laufen die oben genannten Edge-Computing-Funktionen auf eingebetteten Systemen und werden somit schon vom Hersteller bereitgestellt. Sollen die Daten eines Endgerätes ohne eine solche Funktionalität im Edge verarbeitet werden, ist zusätzliche Hardware wie ein Edge Gateway nötig. Diese gibt es von verschiedensten Herstellern. Die kleinen Geräte verfügen über verschiedenste Schnittstellen, um unterschiedliche Endgeräte anbinden zu können.
Sicherheit
Sicherheit ist im Fog Computing ein weiteres wichtiges Thema. Der Hauptpunkt ist, dass im Fog Computing meist Geräte genutzt werden, die schon im Netzwerk vorhanden sind und hauptsächlich andere Aufgaben übernehmen. Die Fog Nodes sind also nicht konkret für Fog Computing ausgelegt, sondern für unterschiedlichste Zwecke. Best Practice ist, hier zumindest für den Übergang vom Endgerät ins Fog-Netzwerk gehärtete Fog Nodes zu verwenden. [6]
Allgemein müssen die Geräte, die in das Fog-Netzwerk eingebunden werden, authentisiert werden. Hinzu kommt die Herausforderung, dass es gerade im Fog-Netzwerk, je nach Aufbau, eine hohe Fluktuation an Geräten geben kann (beispielsweise durch Nutzung von PCs als Fog Nodes). Sobald ein infiziertes Gerät dabei ist, kann das zu Problemen führen. Zudem erhöhen zahlreiche Sensoren, Gateways und Fog Geräte allgemein die Angriffsfläche im lokalen Netzwerk. Unternehmen benötigen ein ausgereiftes Patch Management, damit die Endgeräte möglichst über die aktuellsten Software/Firmware-Stände verfügen.
Ein weiterer Punkt ist neben der softwareseitigen Angreifbarkeit die physische Angreifbarkeit, die durch die Verwendung von Edge Gateways oder Fog Nodes entsteht. Das heißt idealerweise müssen auch die einzelnen Endgeräte und deren Ein- und Ausgänge geschützt werden. [6]
Nicht nur die Fog Nodes bieten eine breite Angriffsfläche, sondern auch die Kommunikation zwischen den verschiedenen Geräten und Ebenen. Diese sollte abgesichert und verschlüsselt werden. Da Fog Nodes allerdings auf den Inhalt eines Paketes reagieren, muss eine Entschlüsselung, Prüfung und Wiederverschlüsselung erfolgen. [6]
Auch in diesem Bereich variieren die Anforderungen natürlich je nach Anwendungsfall und müssen daher immer eingehend betrachtet werden.
Fazit
Das Internet of Things wird in den kommenden Jahren weiter wachsen und damit auch die Menge der zu verarbeitenden Daten. Immer mehr Unternehmen gehen den Weg in die Cloud, wie beispielsweise aktuell auch Volkswagen. Die 122 Fabriken des Konzerns sollen in einer „Volkswagen Industrial Cloud“ zusammengeführt werden. [7] Um dabei Echtzeitanforderungen, Offline-Verfügbarkeit und die Reduzierung der Datenmenge im Netzwerk gewährleisten zu können, sind Lösungen wie Fog und Edge Computing ideal und auch notwendig.
Wenn die passende Lösung für den jeweiligen Anwendungsfall gefunden ist, dann bieten sowohl Fog als auch Edge Computing und besonders deren Kombination einen großen Mehrwert in Bezug auf reduzierte Reaktionszeiten und Datenmengen. [8]
1. Literaturverzeichnis
[1] B. Marr, „Data Science Central,“ 09. April 2015. [Online]. Available: https://www.datasciencecentral.com/profiles/blogs/that-s-data-science-airbus-puts-10-000-sensors-in-every-single. [Zugriff am 09. April 2019].
[2] April 2019. [Online]. Available: http://dell.bmc.de/.
[3] „OpenFog Consortium – Autonomous Driving,“ April 2018. [Online]. Available: https://www.openfogconsortium.org/wp-content/uploads/Autonomous-Driving-Short.pdf. [Zugriff am 09. April 2019].
[4] T. Till, Automobil-Sensorik 2, Springer Berlin Heidelberg, 2018.
[5] OpenFog Consortium Architecture Working Group, „OpenFog Reference Architecture for Fog Computing,“ 2017. [Online]. Available: https://www.openfogconsortium.org/wp-content/uploads/OpenFog_Reference_Architecture_2_09_17-FINAL.pdf.
[6] B. A. Martin, F. Michaud, D. Banks, A. Mosenia, R. Zolfonoon, S. Irwan, S. Schrecker und J. K. Zao, „OpenFog security requirements and approaches,“ Fog World Congress (FWC), 2017 IEEE, 2017.
[7] C. Germis, „FAZ,“ 27. März 2019. [Online]. Available: https://www.faz.net/aktuell/wirtschaft/unternehmen/vw-verbuendet-sich-mit-amazon-bei-industrial-cloud-16110894.html. [Zugriff am 10. April 2019].
[8] N. W. D. S. N. R. B. Blesson Varghese, „Feasibility of Fog Computing,“ in Proceedings of the 18th international conference on distributed computing and networking, 2017.

Teile diesen Eintrag