Das mag banal klingen. Jedoch haben wir immer wieder festgestellt, dass ohne eindeutige Definition von zentralen Begriffen im Zusammenhang mit georedundanten Rechenzentren Erwartungshaltungen bei der Realisierung der Projektziele divergieren können. Es kommt leider oft vor, dass es in den Köpfen unterschiedliche Verständnisse dieser zentralen Begriffe existieren.
Im Folgenden werden Definitionen für einige zentrale Begriffe vorgeschlagen. Es kommt weniger auf die 1:1-Übernahme der hier vorgeschlagenen Termini als vielmehr darauf an, dass die damit bezeichneten Sachverhalte und Mechanismen unterschieden und eindeutig bezeichnet werden.
Georedundanz oder RZ-Auslagerung?
Selbst der Begriff der Georedundanz wird hin und wieder für unterschiedliche Konstellationen verwendet. Daher ist es wichtig, RZ-Georedundanz eindeutig zu definieren.
Mit RZ-Georedundanz bezeichnen wir die Verteilung der Ressourcen eines als logische Einheit genutzten und verwalteten Rechenzentrums auf mindestens zwei geografisch entfernte Standorte. Geografisch entfernt sind RZ-Standorte dann, wenn sie mindestens baulich getrennt und voneinander hinsichtlich Stromversorgung, Klimatisierung und Netzanbindung (einschließlich Kabel, Kabelwege, aktiver Netzkomponenten) vollständig unabhängig und gegeneinander rückwirkungsfrei sind.
Unabhängige Stromversorgung meint dabei mindestens unabhängige Niederspannungsnetze. Das heißt, zwei RZs sind dann hinsichtlich Stromversorgung unabhängig, wenn sie von unterschiedlichen Transformatoren zwischen dem Mittelspannungs- und dem Niederspannungsnetz versorgt werden.
Selbstverständlich müssen georedundante Rechenzentren auch über unabhängige USV-Anlagen verfügen. Wird eine Netzersatzanlage (NEA, in der Regel ein Dieselaggregat) zur weiteren Absicherung eingesetzt, muss auch die NEA pro RZ vorhanden sein.
Unabhängige Klimatisierung bedeutet, dass alle Komponenten der Kühlung, von der Kältemaschine bis zum Umluftkühlgerät und den Lüftungskanälen, redundant vorhanden sind.
Und schließlich müssen georedundante Rechenzentren hinsichtlich Netzanbindung voneinander unabhängig sein. Dies bedeutet, dass die Rechenzentren über vollständig unabhängige Trassen an getrennte Points of Presence (PoPs) der Provider angeschlossen sind.
RZ-Georedundanz ist von der RZ-Auslagerung zu unterscheiden. RZ-Auslagerung und RZ-Georedundanz sind in der Abbildung 1 dargestellt.
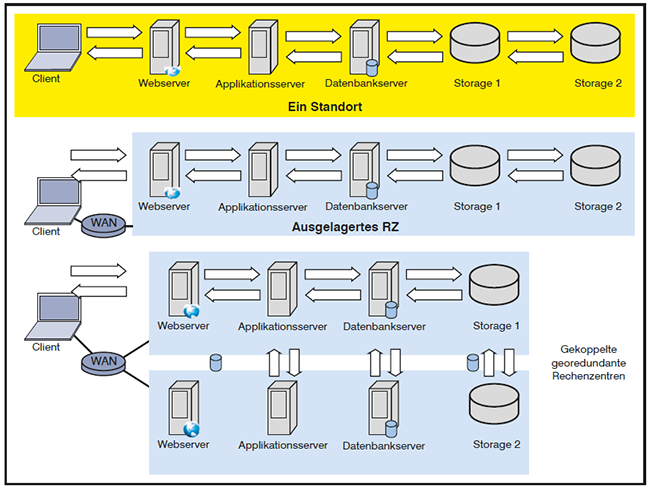
Abbildung 1: RZ-Auslagerung und RZ-Georedundanz
Viele Unternehmen entscheiden sich für eine Auslagerung ihres Rechenzentrums vom eigenen Gebäude in ein entferntes Gebäude. Damit ist nicht automatisch und in jedem Fall eine georedundante Auslegung des Rechenzentrums verbunden. RZ-Auslagerung bedeutet nur, dass RZ-Ressourcen von einem auch anderweitig genutzten Gebäude (in der Regel einem Bürogebäude des Unternehmens) in ein anderes Gebäude verlagert werden. Dafür kann es unterschiedliche Anlässe geben. Zum Beispiel kann die Auslagerung dadurch motiviert sein, dass gesteigerte Anforderungen an die Betriebssicherheit des Rechenzentrums im eigenen Gebäude nicht erfüllt werden können. Die Auslagerung kann auch dadurch notwendig werden, dass mit dem RZ-Wachstum die Grenzen der Skalierbarkeit des bis dato genutzten Standorts erreicht werden. Ein anderer Grund für die RZ-Auslagerung kann darin bestehen, dass das RZ näher in Richtung Public Clouds rücken und daher zum Beispiel in eine Colocation verlagert werden soll, in der auch PoPs verschiedener Cloud-Betreiber untergebracht sind.
RZ-Auslagerung kann, muss jedoch nicht mit der Realisierung von RZ-Georedundanz verbunden sein.
Mit der Einführung der RZ-Georedundanz können ganz andere Phänomene einhergehen als mit einer RZ-Auslagerung. Bei einer RZ-Auslagerung (ohne RZ-Georedundanz) werden „nur“ der geografische Abstand und damit der Signalweg zwischen den RZ-Ressourcen und den Arbeitsplatzendgeräten bzw. einem Teil der Arbeitsplatzendgeräte verlängert. Dies bedeutet meistens, dass es einen längeren Signalweg zwischen Clients und Servern gibt. Auch wenn diese Verlängerung je nach Entfernung zum ausgelagerten RZ eine Erhöhung um mehrere 10er Potenzen bedeuten kann, ist zu berücksichtigen, dass sich nur selten alle Clients am selben Standort befinden wie die Server. Sobald ein Unternehmen ein Wide Area Network (WAN) oder mobile bzw. Heimarbeitsplätze nutzt, sobald ein Unternehmen geografisch verteilte Clients einsetzt, gibt es zwangsläufig einen Signalweg von hunderten, tausenden oder gar zehntausenden Kilometern zwischen den Servern und einem Teil der Clients.
Mit einem solchen Szenario hat mittlerweile fast jedes Unternehmen Erfahrungen. Man weiß, dass nicht alle Client-Server-Protokolle WAN-tauglich bzw. für die Nutzung durch mobile und Heimarbeitsplätze geeignet sind. Für Applikationen, die nicht WAN-taugliche Protokolle nutzen, sind hinreichend bekannte Abhilfen verfügbar. Zum Beispiel kann man in solchen Fällen Terminalserver oder virtuelle Desktops einsetzen. Alternativ kann die Applikation so geändert werden, dass die Clients nur noch über HTTP bzw. HTTPS mit einem Web Front End kommunizieren. HTTP und HTTPS sind für weltweite Kommunikation konzipiert worden.
Trotzdem kann es auch in Projekten, in denen ein RZ ausgelagert wird, einige Überraschungen geben, was die Performance von Applikationen betrifft. Oft werden nicht WAN-taugliche Applikationen erst bei einer solchen RZ-Auslagerung entdeckt.
Das Problem nicht WAN-tauglicher Applikationen ist von den Problemen zu unterscheiden, die mit der Einführung von RZ-Georedundanz entstehen können. Im ersten Fall geht es um die Client-Server-Kommunikation, im Fall der Georedundanz zusätzlich um Kommunikation zwischen RZ-Ressourcen.
Zum Beispiel kann sich die Georedundanz auf die Performance einer typischen 3-Tier-Anwendung signifikant auswirken, deren Client-Server-Kommunikation durchaus WAN-tauglich ist. Im RZ werden für eine solche Applikation die typischen drei Tiers (Stufen) aufgestellt: Web Front End, Applikationsserver und Datenbankserver. Gibt es einen zum Beispiel in ein Storage Area Network (SAN) ausgelagerten Massenspeicher, kommt Storage als vierte Stufe hinzu. Die RZ-Georedundanz kann bedeuten, dass sich Web Front End und Applikationsserver in einem und Datenbankserver und Storage im anderen RZ befinden [1]. Die Kommunikation zwischen dem Applikationsserver und dem Datenbankserver ist in der Regel viel empfindlicher für Latenzen als die Kommunikation zwischen einem Web-Client und einem Web-Server.
Ein anderes Beispiel ist die Nutzung eines verteilten Speichersystems. Speicherkomponenten in verschiedenen, georedundanten Rechenzentren müssen je nach Datenhaltungskonzept miteinander Daten austauschen. Je nachdem, ob dieser Datenaustausch synchron mit Online-Transkationen erfolgen soll oder unabhängig davon (asynchron) erfolgen kann, ergeben sich ganz unterschiedliche Anforderungen an den maximalen Abstand zwischen den involvierten Storage-Knoten.
Die klare Unterscheidung zwischen RZ-Auslagerung und RZ-Georedundanz bedeutet nicht, dass bei der Realisierung des Letzteren keine Probleme in der Client-Server-Kommunikation entstehen können. Solche Probleme können möglicherweise erst auffallen, wenn die RZ-Georedundanz eingeführt wird. Der folgende Fall ist denkbar: Alle Clients, die eine bestimmte Applikation nutzen, befinden sich ursprünglich am selben Standort wie das RZ. Nun wird RZ-Georedundanz implementiert. Zwangsläufig wird zumindest ein Teil der RZ-Ressourcen ausgelagert. Dies bedeutet, dass RZ-Georedundanz zumindest für einen Teil der RZ-Ressourcen eine Auslagerung bedeutet. Und nun erfolgt eine nicht WAN-taugliche Client-Server-Kommunikation zum ersten Mal statt, weil die Clients nicht auf Server am selben Standort, sondern auf Server im entfernten RZ zugreifen.
In einem Projekt mit dem Ziel der RZ-Georedundanz können beide Kategorien von Problemen auftreten. Restriktionen der Clients-Server-Protokolle sind in der Regel ganz andere als solche, die für die Kommunikation zwischen den RZ-Ressourcen gelten. Daher gilt es, zwischen diesen beiden Kategorien von Restriktionen klar zu unterscheiden.
Die klare begriffliche Abgrenzung zwischen RZ-Auslagerung und RZ-Georedundanz ist der erste notwendige Schritt zum Verständnis und zur Differenzierung von völlig unterschiedlichen Restriktionen und Problemen. Denn auch die Lösungen für Probleme, die sich aus der RZ-Georedundanz und aus der RZ-Auslagerung ergeben können, sind ganz unterschiedlich. Einige zur Lösung der Performance-Probleme für Clients beim Zugriff auf zentrale IT-Ressourcen zur Verfügung stehenden Mittel sind für die Lösung der Probleme bei RZ-Georedundanz nicht relevant. Dazu zählen vor allem WAN-Optimierung und Server-Based Computing (Server-Based Computing wird hier als Oberbegriff für Konzepte wie Terminalserver und Virtual Desktops verwendet).
Konsistenz, Verfügbarkeit oder Partitionstoleranz?
In meinem Artikel vom August 2016 bin ich auf das CAP-Theorem [2] eingegangen. Es ist wichtig, die mit der Abkürzung CAP gemeinten Ziele der Georedundanz eindeutig zu definieren und klar zu unterscheiden:
- Consistency: In einem verteilten System wird mit Konsistenz die Eigenschaft bezeichnet, dass alle Anwender jederzeit auf dieselben Daten zugreifen.
- Availability: Availability bedeutet, dass all Anwender jederzeit Lese- und Schreibzugriff auf alle Daten haben, unabhängig davon, auf welchen Teil des Systems sie zugreifen.
- Partition-Tolerance: Dies ist die Eigenschaft, dass das verteilte System eine Aufteilung in getrennte Teilsysteme toleriert.
Die Kernaussage des CAP-Theorems besteht darin, dass diese drei Ziele nicht gleichzeitig erreicht werden können.
Die umgekehrte Aussage, nämlich die Möglichkeit des Erreichens aller drei Ziele, kann mit einem relativ einfachen Gegenbeweis widerlegt werden. Man stelle sich vor, der Benutzer A greife auf das Teilsystem a und der Benutzer B auf das Teilsystem b zu, wie in der Abbildung 2 abgebildet.
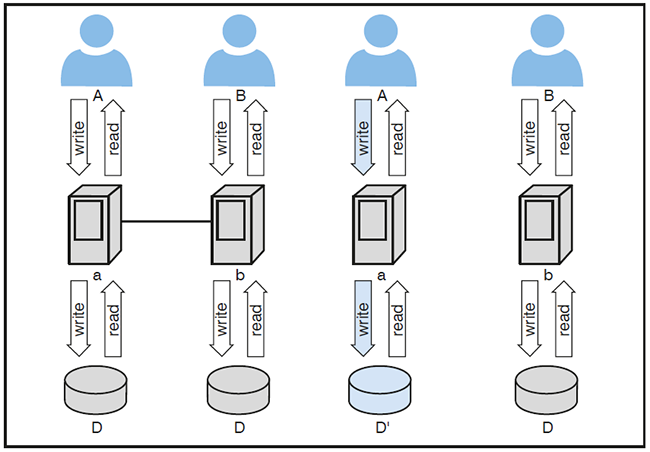
Abbildung 2: Beweis des CAP-Theorems
Nun werden a und b getrennt, weil das verteilte System eine solche Trennung toleriert. Derselbe Datenbestand D existiert nun in a und b. Nach der Aufteilung des Gesamtsystems greift A schreibend auf D zu und ändert D in D‘ um, weil das System sowohl für A als auch für B verfügbar ist. Nach dieser Änderung greifen aber A auf D‘ und B auf D zu. D und D’ unterscheiden sich. Die Konsistenz ist verloren gegangen.
Es ist wichtig, dass sich jedes Unternehmen, das RZ-Georedundanz anstrebt, darüber im Klaren ist, welche Kombination von zwei Zielen es erreichen will:
- C und A: Konsistenz und Verfügbarkeit. Dann wird auf Partitionstoleranz (P) verzichtet. In diesem Fall darf die Verbindung zwischen den georedundanten Rechenzentren nie ausfallen.
- C und P: Konsistenz und Partitionstoleranz. In diesem Fall wird hingenommen, dass die Verfügbarkeit nicht jederzeit für alle Anwender gegeben ist. Das System kann zum Beispiel so konfiguriert werden, dass es nach einer Trennung a weiter lesenden und schreibenden Zugriff, aber b keinen Zugriff mehr gewährt.
- A und P: Auf die Konsistenz wird verzichtet. Nach einer Aufteilung erlauben sowohl a als auch b lesenden und schreibenden Zugriff. Es wird hingenommen, dass zwischen D und D‘ eine Diskrepanz entsteht.
Die Wahl der meisten Kunden von ComConsult fällt auf die Kombination CA. Auf C können die meisten Unternehmen nicht verzichten, weil divergierende Datenbestände je nach Branche problematisch bis sehr problematisch sind. A ist wichtig, weil gerade mit der Georedundanz die Verfügbarkeit erhöht werden soll. Dafür verzichtet man auf P, indem man die Verbindung zwischen den beiden Rechenzentren redundant auslegt und darauf setzt, dass durch die Redundanz die Wahrscheinlichkeit des Ausfalls dieser Verbindung (der sogenannten RZ-Kopplung) sehr gering ist.
Geht man davon aus, dass die RZ-Kopplung nie ausfällt, kann a bei Nichterreichbarkeit von b immer davon ausgehen, dass b selbst und nicht die Verbindung zu b ausgefallen ist (und umgekehrt). Dann ist ein automatischer Redundanzmechanismus relativ einfach. Jedes der beiden Teilsysteme a und b arbeitet weiter, wenn aus seiner Sicht das andere Teilsystem nicht erreichbar ist.
Wenn jedoch eine Restwahrscheinlichkeit des Ausfalls der RZ-Kopplung besteht, kann a bei Nichterreichbarkeit von b nicht unterscheiden, ob b selbst oder die Verbindung zu b ausgefallen ist, und umgekehrt. Dann kann es dazu kommen, dass a und b weiter arbeiten und schreibenden Zugriff auf die Daten gewähren. Die Konsistenz kann dabei verloren gehen.
Damit es nicht so weit kommt, kann eine dritte Instanz w (für Witness), am besten an einem dritten Standort, wie in der Abbildung 3 dargestellt durch Überprüfung der Verfügarbeit von a und b entscheiden, wie es nach einem Ausfall weiter geht. Der Schiedsrichter w sorgt auf jeden Fall dafür, dass a und b nie entkoppelt voneinander arbeiten und nicht konsistente Datenbestände verursachen.
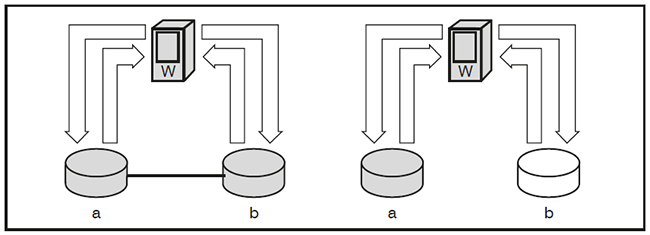
Abbildung 3: Witness an einem dritten Standort
Das klare Verständnis und die unternehmenseigene Festlegung der Ziele der Georedundanz sind wichtig, damit sich auch klare Vorgaben für die Planung der Georedundanzlösung ergeben.
Synchron oder asynchron?
Die synchrone Datenhaltung wurde bereits oben erwähnt. Die Definition von synchron und asynchron sollte sich immer auf die Datenhaltung beziehen, nicht darauf, ob die Verarbeitungsressourcen in zwei Rechenzentren gleichzeitig arbeiten oder nicht (auf Letzteres, nämlich active-active- versus active-standby-Betrieb, wird weiter unten eingegangen).
Wie bereits erläutert bedeutet synchrone Datenhaltung zwischen zwei Rechenzentren, dass mit jeder Online-Transaktion, welche einen Teil der Daten verändert, die Änderung auf mindestens zwei Kopien in zwei verschiedenen Rechenzentren angewandt wird. Die Transaktion wird gegenüber dem Client nicht bestätigt, solange die synchrone Replikation der bei der Transaktion geänderten Daten zwischen den Rechenzentren nicht erfolgreich abgeschlossen ist. Daraus folgt, dass die synchrone Datenhaltung entscheidenden Einfluss auf jede Applikation hat, für deren Daten die synchrone Replikation eingerichtet wird. Jede Transaktion im Rahmen solcher Anwendungen wird um die Zeit verzögert, die für die Synchronisation der Daten notwendig ist. Diese zusätzliche Zeit kommt zur „normalen“ Transaktionszeit hinzu, die ohne Synchronisation gemessen wird. Ohne Georedundanz entspricht eine typische Transaktionskette dem Schema Client – Server – Storage, und die Kette zur Bestätigung der Transkation umgekehrt Storage – Server – Client. Mit Georedundanz verlängern sich die beiden Ketten, zum Beispiel zu Client – Server – Storage – Storage bzw. Storage – Storage – Server – Client (wenn die Datensynchronisation unter Nutzung der Mechanismen eines Storage-Clusters erfolgt). Dies ist in der Abbildung 4 dargestellt.
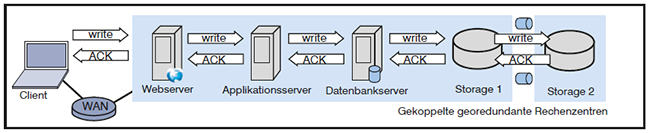
Abbildung 4: Synchrone Datenhaltung
Es liegt auf der Hand, dass durch die längere Kette bei schreibendem Zugriff ein solcher Zugriff mehr Zeit benötigt. Wenn die Anwendung eine Block-orientierte Schnittstelle wie Small Computer Systems Interface (SCSI) für die Kommunikation zwischen Server und Storage nutzt, muss jeder Block synchron auf beiden Knoten des Clusters verändert werden. Da jede Transaktion dutzende, hunderte oder gar tausend Blöcke verändern kann, kommt es möglicherweise zu vielen Wiederholungen der Übertragung von einem zum anderen Storage-Knoten, wohlgemerkt zwischen Knoten, die sich wegen der Georedundanz an unterschiedlichen Standorten befinden. Der Abstand zwischen den beiden Rechenzentren macht sich damit durch die Signalübertragungszeit (Latenz, Delay) zwischen den beiden RZ-Standorten bei jeder Transaktion bemerkbar, und das mehrfach.
Dieses Problem gibt es in einem asynchronen Georedundanzszenario nicht. Denn asynchrone Datenreplikation zwischen Rechenzentren bedeutet per definitionem, dass diese Datenreplikation von den Online-Transaktionen entkoppelt ist, wie in der Abbildung 5 dargestellt.
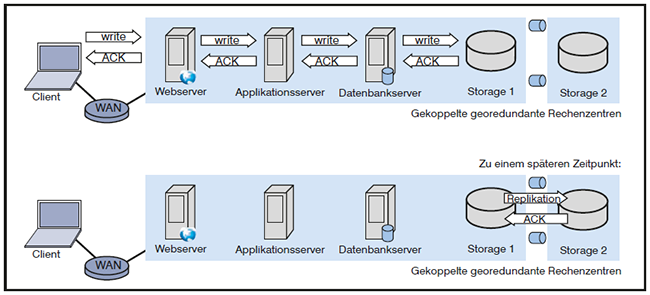
Abbildung 5: Asynchrone Replikation
Für die asynchrone Datenreplikation können unabhängig von den Anwendungen und ihren Transaktionen optimierte Protokolle und Mechanismen genutzt werden. Zu den Optimierungsmöglichkeiten gehören die Nutzung möglichst großer Blöcke bei der Übertragung sowie die differenzielle Übertragung. Mit differenziell ist hier gemeint, dass ausschließlich die genäderten Daten übertragen werden, nicht ganze Datenbestände wie große Dateien. Mit solchen Optimierungen werden asynchrone Datenreplikationen auch zwischen verschiedenen Kontinenten ermöglicht.
Das bedeutet, dass der asynchronen Replikation keine Entfernungsgrenzen gesetzt sind, zumindest solange sich die beiden Rechenzentren auf der Erdkugel befinden. Selbst bei einem Kabelweg von 40.000 km, d.h. einem Einweg-Delay von 200 Millisekunden, bzw. einer Round Trip Time von 400 Millisekunden, kann eine asynchrone Replikation eingerichtet werden. Sie dauert natürlich mit zunehmender Entfernung bei sonst gleichen Randbedingungen länger. Da jedoch die Online-Transaktionen durch die asynchrone Replikation nicht aufgehalten werden, sind lange Wartezeiten auf den Abschluss der asynchronen Replikation tolerierbar.
Die Kehrseite der Medaille bei asynchroner Replikation ist jedoch der Verzicht auf die jederzeitige Konsistenz der Datenbestände in den georedundanten Rechenzentren. Die Übernahme der Funktion eines Rechenzentrums durch ein anderes kann somit mit Datenverlusten einhergehen, wenn dieser Schwenk ungeplant, zum Beispiel durch einen unvorhergesehenen Komplettausfall eines Rechenzentrums, erfolgen muss. In diesem Fall sind alle Daten zum entfernten RZ repliziert, die bis unmittelbar vor der letzten erfolgreich abgeschlossenen Replikation vorlagen. Daten, die danach verändert worden sind, gehen durch den Komplettausfall des Rechenzentrums verloren, in dem die Daten zuerst verändert wurden.
Bei geplanten Abschaltungen gibt es die Möglichkeit, alle Online-Transaktionen zu stoppen und vor dem Schwenk die erfolgreiche asynchrone Replikation vom abzuschaltenden RZ zum entfernten RZ abzuwarten. Dann kann der Schwenk erfolgen. Nach dem erfolgreichen Schwenk kann die geplante Abschaltung des einen Rechenzentrums durchgeführt werden. Ist der Anlass der geplanten Abschaltung, zum Beispiel eine bauliche Änderung, Wartung der Klimaanlage oder Arbeit an der Stromversorgung, vorbei, kann der Rückschwenk in Angriff genommen werden. Dazu müssen wieder Online-Transaktionen gestoppt werden. Danach müssen alle nach der Abschaltung des einen Rechenzentrums geänderten Daten vom entfernten RZ zum wieder in Betrieb genommenen RZ repliziert werden. Ist diese Replikation erfolgreich abgeschlossen, kann der Rückschwenk durchgeführt werden.
Man sieht, asynchrone Replikation ist immer mit einem teilweisen Verzicht auf Konsistenz oder Verfügbarkeit oder beides verbunden. Dafür stellt sie keine hohen Anforderungen an die geografische Nähe der RZ-Standorte wie die synchrone Datenhaltung.
Spiegelung oder Replikation?
Im Zusammenhang mit der redundanten Datenhaltung in Rechenzentren werden die Begriffe Spiegelung und Replikation oft als austauschbare Synonyme genutzt. Das führt manchmal zu Verwirrung.
Je nach Zuhörer oder Leser wird unter Spiegelung eine jederzeitige 1:1-Spiegelung verstanden (so wie ein Abbild in einem Spiegel). Dies bedeutet eine synchrone Datenhaltung.
Bei einer asynchronen Datenhaltung werden aber auch Daten von a nach b oder umgekehrt kopiert. Da dies aber asynchron zu den Änderungen der Daten geschieht, sollte man hier nicht von Spiegelung sprechen. Geeigneter wäre der Begriff Replikation.
Somit wäre Replikation der Oberbegriff, und Spiegelung wäre eine besondere Form der Replikation, bei der jede Datenveränderung sofort auch zur Änderung des Abbilds der Daten führt.
Luftlinie oder Kabelweg?
Eng mit der Diskussion über synchrone oder asynchrone Datenhaltung hängt die Frage nach dem Abstand zwischen georedundanten Rechenzentren zusammen. Die Grenzen, die die synchrone Datenhaltung setzt, sind auf die Signalübertragungszeit zwischen den georedundanten Rechenzentren zurückzuführen. Diese Latenz ergibt sich aus der Division des Signalwegs durch die Übertragungsgeschwindigkeit. Letztere ist konstant. Sie ist bei Datenleitungen der Übertragungsrate ab ca. 100 Mbit/s und der Länge von über 100 Metern fast immer gleich der Ausbreitungsgeschwindigkeit von Licht im Glas. (Kupferkabel kommen nur zur Überbrückung von 100 Metern oder zur Übertragung mit niedrigeren Bitraten als bei der RZ-Kopplung erforderlich infrage, und drahtlose Übertragung kommt bei RZ-Kopplung in der Regel auch nicht zum Einsatz [3].)
Hinzu kommen Verzögerungen durch Netzkomponenten, Server und Storage. Aber diese Verzögerungen sind auch ohne Georedundanz da.
So kann man die Faustregel von einer Millisekunde pro 200 km Entfernung für die Berechnung der Einweglatenz anhand der Entfernung anwenden, bzw. einer Millisekunde Round Trip Time (RTT) pro 100 km Entfernung.
Diese Entfernung ist immer gleich Kabelweg. D.h. bei Berechnung bzw. Messung der Toleranzgrenzen von Applikationen hinsichtlich der Entfernung zwischen georedundanten Rechenzentren mit synchroner Datenhaltung ist immer der Kabelweg entscheidend.
Dieser Hinweis ist insofern vonnöten, weil bei der Bestimmung des Mindestabstands zwischen georedundanten Rechenzentren nicht der Kabelweg, sondern die Luftlinie das Maß der Dinge ist. Weder chemische Giftwolken noch Erschütterungen durch Explosionen oder seismische Phänomene folgen dem Kabelweg, sondern breiten sich über den kürzesten Weg aus. Und das ist die Luftlinie.
Für die Betrachtung der Risiken durch zu nah beieinander liegende RZ-Standorte ist somit die Luftlinie entscheidend. Leider wird in vielen Schriftstücken zum Thema RZ-Georedundanz nicht klar genug zwischen Luftlinie und Kabelweg differenziert.
Wenn die Risikoanalyse zu dem Ergebnis kommt, dass zwei georedundante Rechenzentren mindestens 5 km voneinander entfernt sein müssen, wird damit die Luftlinie zwischen den beiden Standorten spezifiziert. Die Machbarkeit der synchronen Datenhaltung in diesen beiden Rechenzentren ist aber von der Länge der Kabelverbindungen zwischen den beiden Standorten abhängig. Und bei den Kabelverbindungen ist hier die Betonung auf Plural.
Warum?
Denn wie oben erwähnt entscheiden sich die meisten Unternehmen bei RZ-Georedundanz für die beiden Ziele Konsistenz und Verfügbarkeit. Nach dem CAP-Theorem müssen sie daher auf Partitionstoleranz verzichten. Deshalb müssen sie die RZ-Kopplung zwischen den beiden Standorten hochverfügbar auslegen. Es muss also zwei kanten- und knotendisjunkte Verbindungen zwischen den beiden Rechenzentren geben. Kantendisjunkt sind die beiden Trassen dann, wenn sie sich nicht überschneiden oder zu nahe kommen (zum Beispiel dürfen sie nicht über dieselben Räume, Leerrohre oder Schächte verlaufen). Knotendisjunkt sind die Verbindungen, wenn sie nicht dieselben Netzkomponenten nutzen.
Insbesondere die Forderung kantendisjunkter Trassenführung führt in der Praxis zu unterschiedlichen Längen der redundanten Verbindungen. Bei der Planung der Trassenverläufe muss man sich an verfügbaren Ferntrassen der Provider orientieren, denn selten ist ein Unternehmen bereit und in der Lage, nur für die eigenen Zwecke Millionen Euro in neue Trassen zu investieren. Ergibt sich zwischen a und b eine Trasse von 10 km Länge und eine zweite, davon disjunkte von 15 km Länge, bekommt man einen Weg mit einer RTT von 0,1 und einen zweiten mit einer RTT von 0,15 Millisekunden, wie in der Abbildung 6 dargestellt.
Der für die Bestimmung der Toleranzgrenzen der Applikationen entscheidende ist der größere Wert (also in diesem Fall 0,15 Millisekunden).
Dafür gibt es zwei wesentliche Gründe:
- Erstens will und muss man in der Praxis dynamische Mechanismen für die Wegewahl nutzen. Es ist nicht praktikabel und effizient, alle Netzmechanismen auf die ständige und ausschließliche Nutzung des kürzeren Weges zu trimmen.
- Zweitens kann der kürzere Weg ausfallen. Dann muss der längere Weg genommen werden.
Wir empfehlen in einigen Fällen, die kürzere Strecke durch den Einsatz sogenannter Vorlauffasern künstlich zu verlängern, damit beide Wege dieselbe Länge haben. Dann kann auch ein Fiber Channel Inter Switch Link (ISL) aus physischen Links bestehen, die über die verschiedenen Wege verlaufen.
Zusammengefasst gibt es zwei Gründe, weshalb die Luftlinie (entscheidend für die Betrachtung von Risiken bei Ausfallszenarien) und der Signalweg voneinander abweichen, erstens den nicht geradlinigen Verlauf der Trassen und zweitens die Erfordernis von zwei disjunkten Kabelwegen.
Oft wird die Frage nach dem Umrechnungsfaktor zwischen Luftlinie und Signalweg gestellt. Diese Frage kann nicht einfach beantwortet werden, weil sie von den jeweiligen topografischen und sonstigen Gegebenheiten abhängt. Allgemein gilt, dass der Umrechnungsfaktor mit zunehmender Entfernung sinkt. In einem Stadtgebiet hat der Autor schon mit einem Kabelweg von über 10 km bei nur 1 km Luftlinie rechnen müssen. Den Faktor 10 hat man bei einer Luftlinie in der Größenordnung von 100 km selten. Zumindest innerhalb Deutschlands, wo es in der Fernebene im Großen und Ganzen eine gute Versorgung mit Glasfasern gibt, muss man zwischen zwei Städten mit 100 km Abstand (Luftlinie) sehr selten einen Kabelweg von 1000 km nutzen.
Trotzdem ist es denkbar, dass eine Trasse zwischen Köln und Frankfurt ca. 200 km und die andere Trasse ca. 400 km lang ist, um kantendisjunkte Wegeführungen sicherzustellen.
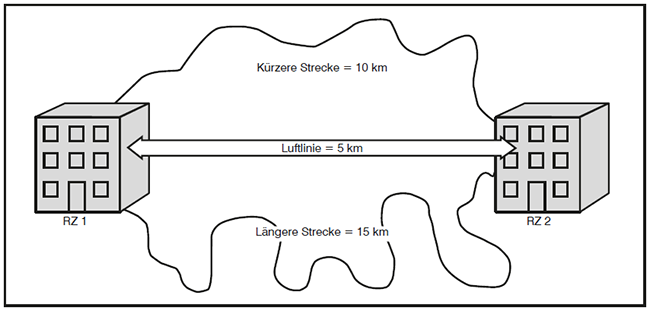
Abbildung 6: Unterschiedlich lange Kabelwege zwischen zwei Rechenzentren
Active-active oder Active-standby?
Bei der Planung der RZ-Georedundanz muss man sich für den Modus active-active oder den Modus active-standby entscheiden. In der Praxis fällt diese Entscheidung für verschiedene Applikationen bzw. Systeme nicht selten unterschiedlich aus.
Der Modus active-active bedeutet, dass die Systeme in beiden Rechenzentren im Normalfall aktiv sind, d.h. Applikationen bedienen.
Dagegen bedeutet der Modus active-standby, dass eines der Rechenzentren die aktiven Systeme beherbergt und die Ressourcen im anderen RZ dann eingesetzt werden, wenn die Systeme im ersten RZ geplant oder ungeplant außer Betrieb gehen.
Leider gibt es in einigen Fällen keine eindeutige Abgrenzung zwischen den Begriffen synchroner Modus und active-active-Modus. Der Autor hat schon mal erlebt, dass von synchronen Rechenzentren gesprochen wurde und gemeint war, dass die Systeme in beiden Rechenzentren immer gleichzeitig Applikationen bedienen.
Zwei synchrone Rechenzentren im Sinne der in diesem Beitrag vorgeschlagenen Definition müssen jedoch nicht unbedingt im Modus active-active arbeiten. Es ist möglich (und in vielen Unternehmen auch gängige Praxis), dass die Datenhaltung in zwei Rechenzentren synchronisiert ist, wobei ein RZ die im Normalfall die Online-Transaktionen bedienenden Systeme beherbergt und im anderen RZ Systeme aufgestellt sind, die nur bei Ausfällen im ersten RZ genutzt werden.
Was die Einhaltung des Modus „active-standby“ erschwert, sind die Möglichkeiten, die in den letzten eineinhalb Jahrzehnten mit der Servervirtualisierung entstanden sind. Die Verlagerung einer virtuellen Maschine (VM) von einem zum anderen physischen Host ist im Vergleich zum Zeitalter vor der breiten Einführung der Virtualisierung derart einfach und reibungslos geworden, dass man sie oft leider auch nicht dokumentiert ausführt. Häufig wissen Administratoren nicht genau, welche Instanzen in einer virtualisierten Umgebung gerade welche Anwendungen bedienen. Und wenn sie das in Erfahrung bringen, ergeben sich sehr verschlungene Verbindungen, auch zwischen den Komponenten, die ein und dieselbe Anwendung bedienen.
Nicht selten begegnet man einem Zustand nachfolgendem Schema, das in der Abbildung 7 visualisiert ist:
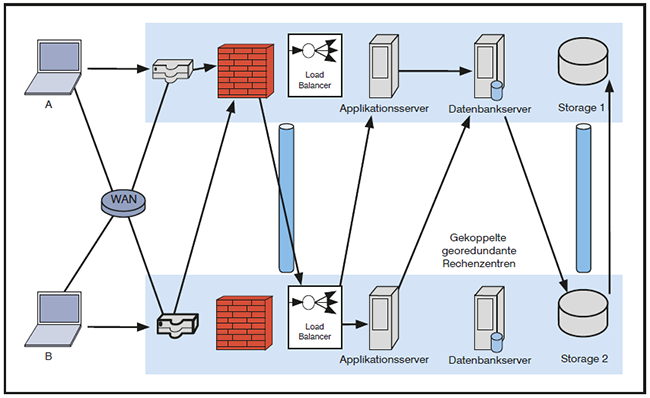
Abbildung 7: Active-active-Modus
- Ein Teil der Clients greift über Router im RZ a auf eine Anwendung zu (nennen wir sie Gruppe A), ein anderer Teil über Router im RZ b (nennen wir sie Gruppe B).
- Beide Client-Gruppen müssen jedoch eine Firewall im RZ a nutzen. So ergibt sich ein, wenn auch kleiner, zeitlicher Vorsprung für die Gruppe A.
- Der aktive Load Balancer (LB) befindet sich im RZ b. Daher geht der Weg weiter von Firewall a zum LB am Standort b. Für beide Gruppen kommt also ein weiterer Durchlauf der RZ-Kopplung hinzu.
- Einige reelle Server befinden sich in a, einige andere in b. Diejenigen Clients, die zu reellen Servern am Standort b weiter geleitet werden, haben es besser als die Clients, die reelle Server am Standort a nutzen.
- Der aktive Knoten im Datenbankcluster befindet sich momentan am Standort a. So haben Applikationsserver an diesem Standort einen Vorteil. Dieser Vorteil kann sich auch für die Benutzer bemerkbar machen, da zwischen Applikations- und Datenbankservern eingesetzte Protokolle oft eine hohe Anzahl von Round Trips benötigen.
- Der virtuelle Speicher, den die Datenbank nutzt, ist gerade mal vom Storage-Administrator zum Standort b verlagert worden. Alle Clients stellen längere Antwortzeiten fest, weil der Datenbankserver am Standort a auf einen virtuellen Speicher am Standort b zugreifen muss, in der Regel auch über ein Protokoll, das für eine Transaktion viele Round Trips benötigt.
- Der Speicher am Standort b muss bei jedem schreibenden Zugriff eine synchrone Replikation der betroffenen Daten zum Standort a veranlassen. Es kann dadurch zu zusätzlichen Verzögerungen durch eine Vielzahl von Round Trips kommen.
Die Folgen eines solchen Zustands sind oft lange, unterschiedliche und auf den ersten Blick nicht nachvollziehbare Antwortzeiten der Anwendungen.
Der oben beschriebene Zustand kann zum Albtraum für eine Person werden, die Fehlersuche betreiben muss. Zunächst muss diese Person in Erfahrung bringen, wo sich die aktiven Instanzen gerade befinden und wie sie miteinander verbunden sind. Dann kommt auch die Schwierigkeit hinzu, zum Beispiel zur Analyse von Performance-Problemen viele Messpunkte entlang der Datenströme vorsehen zu müssen. Die vielen Round Trips machen ganz verschiedene Instanzen zu potenziellen Kandidaten bei der Suche nach den Ursachen des Performance-Problems.
In dieser Hinsicht hätte der Modus active-standby eindeutige Vorteile. Ein solcher Modus würde darin bestehen, dass sich zumindest Komponenten, die statusbewusst (stateful) arbeiten, im Normalfall alle in einem RZ befinden. Das würde für Firewalls, Load Balancer, Applikationsserver, Datenbankserver und den aktiven Speicher gelten. Die Zahl der Round Trips wird damit reduziert, wie in der Abbildung 8 dargestellt. Zudem wird die Fehlersuche einfacher.
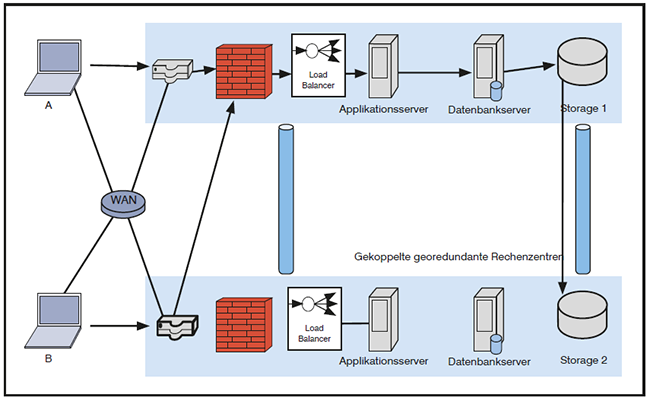
Abbildung 8: Active-standby-Modus
Aber die notwendige Disziplin, um den Modus active-standby-Modus durchzuhalten, darf im Zeitalter der Virtualisierung nicht unterschätzt werden.
Es gibt zwei weitere Nachteile, die gegen den Modus active-standby angeführt werden:
- Ein Teil der Ressourcen liegt brach und „arbeitet nicht“, wird also nicht wirtschaftlich eingesetzt.
- Bei Systemen, die nur als Ausweichressourcen dienen, kann man nicht sicher sein, ob sie bei Bedarf auch gut funktionieren.
Aus der Sicht des Autors können jedoch die beiden oben genannten Argumente relativiert werden.
Man sollte in einer redundanten Konstellation die Systeme nicht „bis zum Anschlag“ auslasten. Man braucht Reserveleistung für den Fall, dass einzelne Systeme außer Betrieb gehen. Aus wirtschaftlicher Sicht gibt es keinen Unterschied zwischen zwei Systemen, die jeweils zu 45 % ausgelastet sind, und zwei Komponenten, die zu 90% bzw. 0% ausgelastet sind.
Was das zweite, oben genannte Argument gegen den Modus active-standby betrifft, so ist zu berücksichtigen, dass es genug Fälle gibt, in denen man geplant einen Schwenk vornehmen muss, zum Beispiel um auf einer Firewall einen Software Update durchzuführen, einen Host auszutauschen oder andere Komponenten zu warten. Es gibt also im täglichen Betrieb genügend Gelegenheit, die Funktionalität von standy-Systemen zu verifizieren. Außerdem sind regelmäßige Übungen der Disaster Recovery (DR) ohnehin Bestandteil jedes geordneten RZ-Betriebs.
So bleiben als Hauptargumente für und gegen den Modus active-standby:
- Im Modus active-standby gibt es im Normalfall kürzere Signalwege und eine Konstellation, in der die Fehlersuche und Performance-Analyse einfacher ist.
- Für den Modus active-standby benötigt man eine höhere Disziplin aller betroffenen Betriebsbereiche und einen höheren Dokumentationsaufwand.
Welche Risiken soll die RZ-Georedundanz reduzieren?
Die hier vorgeschlagenen Begriffsdefinitionen sollen zur Schaffung von mehr Klarheit über die Mechanismen der RZ-Georedundanz und damit auch dazu beitragen, diesen Mechanismen die Risiken zuzuordnen, die sie reduzieren sollen.
Zunächst ist festzustellen, dass die häufigsten Risiken beim RZ-Betrieb auch ohne Georedundanz minimiert werden können. Dazu zählen Ausfälle von Netz-, Sicherheits-, Server- und Speicherkomponenten. Auch an einem einzelnen geografischen Standort können diese Systeme redundant ausgelegt werden.
Selbst die Netzanbindung, das Kühlungssystem und die Stromversorgung können innerhalb eines Rechenzentrums so ausgelegt werden, dass der Betrieb nach den meisten Ausfallszenarien weiter gehen kann. Nicht umsonst haben Standardisierungs- und Beratungsinstitute für RZ-Planung verschiedene Stufen (auch Tiers, Klassen oder Kategorien genannt) der Ausfallsicherheit eines einzelnen Rechenzentrums definiert.
Diese Stufen gehen so weit, dass sie für einige Ausfallszenarien die Georedundanz überflüssig machen:
- Die Netzanbindung eines Rechenzentrums kann über Providertrassen erfolgen, die hunderte Meter voneinander entfernt sind. Ein so angebundenes RZ kann in seiner Gesamtfunktion bei einer entsprechenden Einhaltung der sonstigen Randbedingungen vom Ausfall eines Übergabepunkts zwischen RZ- und öffentlichen Gelände, einer Providertrasse und eines Provider-PoP unbeeinträchtigt bleiben.
- Das Kühlungssystem in einem RZ kann aus redundanten Kältemaschinen, Umluftkühlgeräten und Lüftungskanälen bestehen, sodass es den Ausfall jeder einzelnen dieser Komponenten verkraften kann.
- Die Primärstromversorgung eines Rechenzentrums kann über verschiedene Niederspannungsnetze und verschiedene Umspannwerke der Energieversorgungsunternehmen (EVU) erfolgen, sodass einzelne Ausfälle, zum Beispiel eines Transformators, den RZ-Betrieb nicht beeinträchtigen.
- Die Netzersatzanlagen wie Dieselaggregate können für ein RZ redundant ausgelegt werden.
- Auch die Unterbrechungsfreie Stromversorgung (USV) kann für einen einzelnen RZ-Standort aus verschiedenen USV-Systemen bestehen, die für Redundanz und Ausfallsicherheit sorgen.
- Die physikalische Sicherheit eines Rechenzentrums kann durch Einhaltung von Mindestabständen zu potenziellen Gefahrenquellen wie Flugschneisen, Autobahnen, Bahntrassen, Chemiewerken etc. sowie durch hohen Zutrittsschutz, Videoüberwachung und sonstige einschlägig empfohlene Maßnahmen erhöht werden.
Jedoch wird die Erhöhung der Ausfallsicherheit eines einzelnen RZ-Standorts ab einem bestimmten Sicherheitsniveau so aufwändig, dass mit einem vertretbaren Mehraufwand oder gar ohne signifikanten Mehraufwand statt eines RZ-Standorts zwei georedundante Standorte ertüchtigt werden können. Und dann deckt man auch Risiken ab, die für ein einzelnes RZ nicht auszuschließen sind. Diese sind vor allem Risiken durch regionale Desaster mit großflächiger Wirkung, zum Beispiel:
- Erdbeben,
- nukleare Katastrophen,
- tagelange Evakuierungen bei Bombenfund,
- flächendeckende, monatelange Stromausfälle (man denke etwa an die Auswirkungen des Sturms von 2017 auf Puerto Rico),
- Flugzeugabstürze,
- Sabotageakte,
- usw.
Eine zusätzliche Motivation für Georedundanz kann wie bereits erwähnt existieren, wenn damit auch eine Nähe zu externen Clouds, zumindest im Falle eines der Rechenzentren, erreicht wird. Unterhält man zusätzlich zum RZ auf eigenem Gelände ein RZ in einer Colocation, die auch von Cloud-Anbietern genutzt wird, kann man kurze Wege zu externen Clouds nutzen.
Deshalb beschäftigt sich eine zunehmende Anzahl von Unternehmen mit RZ-Georedundanz. Der aufwändigste Teil eines Vorhabens zur Implementierung der Georedundanz ist die Findung der RZ-Standorte. Wie in diesem Beitrag dargelegt kommt es immer zum Dilemma zwischen der Abdeckung möglichst vieler Risiken und der Bestrebung, die Konsistenz der Daten und die Verfügbarkeit der Systeme und Anwendungen möglichst hochgradig sicherzustellen. Ab einem bestimmten Abstand ist die synchrone Datenhaltung nicht mehr möglich, und unvorhergesehene komplette Ausfälle eines Rechenzentrums gehen mit Datenverlust einher.
Wie löst man dieses Dilemma auf?
Die schlechte Nachricht ist, dass das genannte Dilemma nicht vollständig auflösbar ist. Die Eliminierung aller Risiken bei hundertprozentiger Sicherstellung von Konsistenz und Verfügbarkeit ist unmöglich. Letztere setzen immer der Luftlinie zwischen den Rechenzentren Grenzen, je nach eingesetzten Systemen bis fünf, zehn, zwanzig oder fünfzig Kilometern. Viel mehr geht technisch nicht. Aber selbst 50 km Luftlinie sind nicht genug bei vielen Szenerien wie nukleare Desaster, Kriege oder Wirbelstürme, siehe das Wüten des Sturms Florence in den USA.
Die gute Nachricht ist, dass gegen Geld mehr Ausfallsicherheit zu haben ist. Eine sehr hohe Ausfallsicherheit erreicht man durch zwei Rechenzentren, deren Entfernung die synchrone Datenhaltung an den beiden Standorten erlaubt, sowie einen dritten RZ-Standort, der hunderte oder gar tausende Kilometer von den beiden ersten entfernt ist. Zum dritten Standort können die Daten asynchron repliziert werden, wie in der Abbildung 9 dargestellt.
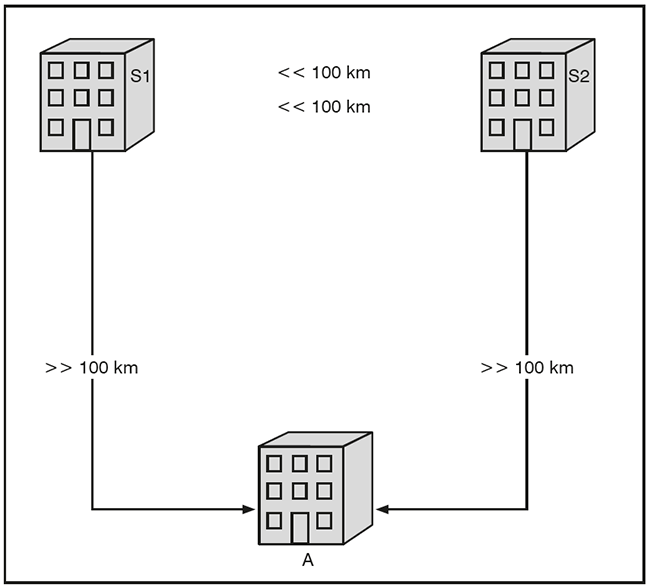
Abbildung 9: Kombination aus zwei synchronen und einem asynchronen Standort
Wir wissen, dass der Schwenk zu einem RZ, in das die Daten nur asynchron repliziert werden, mit Datenverlust und Nichtverfügbarkeit einhergeht. Dieses Umschaltszenario soll für möglichst viele Ausfallszenarien vermeiden werden. Für möglichst viele Ausfallszenerien soll der Schwenk nur zwischen den Rechenzentren mit synchroner Datenhaltung erfolgen. Dies ist für viele Ausfallszenarien machbar, zum Beispiel:
• ungeplanter Ausfall von einzelnen Netz-, Sicherheits-, Server- und Speicherkomponenten,
• ungeplanter Ausfall der Klimatisierung in einem RZ,
• ungeplanter Ausfall der Stromversorgung in einem RZ und
• geplante Stromabschaltung in einem RZ.
In solchen Szenarien, die weitaus häufiger eintreten als solche, die beide Rechenzentren mit synchroner Datenhaltung lahmlegen, ist der Schwenk zum RZ mit asynchron replizierten Daten nicht erforderlich.
Der RZ-Standort mit asynchron replizierten Daten wird nur genutzt, wenn ein regionales Großereignis die beiden anderen Rechenzentren lahmgelegt oder unerreichbar gemacht hat. Sieht man den dritten Standort vor, reduziert man das Risiko auf vorhersehbaren Datenverlust und zeitweisen Ausfall der Applikationen für das Unternehmen, selbst bei den schlimmsten anzunehmenden Katstrophen wie nukleare GAUs und Kriegen.
Eine andere Frage ist, wie hoch der Aufwand sein soll, den ein Unternehmen in die Ausfallsicherheit der IT investiert, wenn andere Ressourcen des Unternehmens, vor allem Produktionsressourcen und Mitarbeiter, durch Katastrophen ausfallen. Was nutzt ein überlebendes RZ hunderte oder tausende Kilometer entfernt, wenn auf die dortigen IT-Ressourcen niemand mehr zugreift?
Verweise
[1] Dieses kann auch dadurch eintreten, dass eine Komponente ausfällt und ein anderes Gerät im anderen RZ deren Funktion übernimmt
[2] Eric A. Brewer, PODC ’00 Proceedings of the nineteenth annual ACM symposium on Principles of distributed computing
[3] Von Ausnahmen abgesehen. Solche Ausnahmen gibt es zum Beispiel bei Verbindungen zwischen Handelsplätzen, wenn es auf Millisekunden ankommt und die Datenrate unterhalb weniger Gigabits pro Sekunde bleibt. In solchen Szenarien wird auch schon mal Richtfunk genutzt, denn Signale – Licht und elektromagnetische Wellen – breiten sich in der Luft eineinhalbmal so schnell aus wie Licht im Glas.

