In diesem Artikel sollen die Geschichte dieser Technologie sowie die technischen Grundlagen erläutert werden. Dabei werden sowohl Vor- als auch Nachteile beschrieben und aktuelle Beispiele für deren Einsatz aufgeführt.
1. Motivation
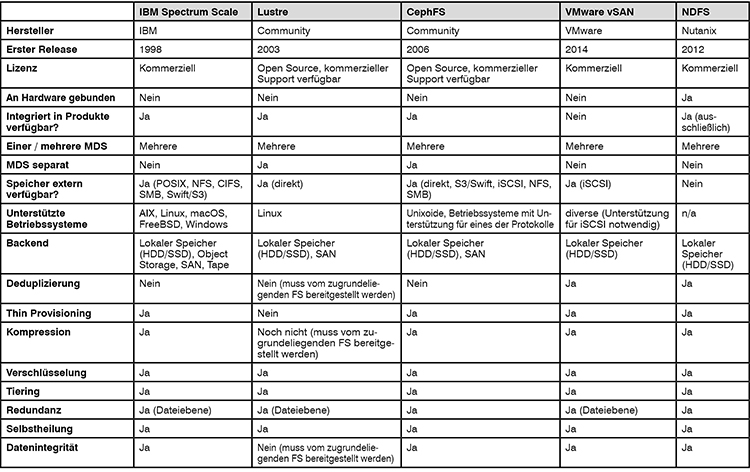
Aktuelle, zentrale Storage-Lösungen bieten eine Vielzahl von Funktionen für die Datenhaltung. Diese umfassen Ausfallsicherheit auf vielen Ebenen, aber auch spezielle Techniken zur Reduktion der „real“ gespeicherten Daten. Darunter fallen Deduplizierung sowie Thin Provisioning für Virtualisierungslösungen.
Trotz all dieser sinnvollen Funktionen ergibt sich bei zentralen Storage-Systemen aber eine Herausforderung bei der Skalierung. Die Kosten für eine entsprechend skalierbare Lösung können sehr hoch ausfallen. Außerdem ist ein gleichzeitiger Zugriff vieler Systeme auf die Daten häufig durch die Bandbreite der Netzanbindung des zentralen Systems begrenzt. Hier hat sich auch gezeigt, dass Netzwerk-Technologien jenseits von Fibre Channel (FC), z.B. Ethernet und Infiniband, ihre Bandbreiten wesentlich schneller erhöht haben als FC, so dass auch die Nutzung einer anderen Netzwerktechnologie sinnvoll sein kann.
Speziell bei hochgradig parallelen Berechnungen – Beispiele sind hier Big Data und High Performance Computing (HPC) – bei denen Tausende bis zu Millionen von Prozessen gleichzeitig auf Daten zugreifen müssen, wünscht man sich daher eine Storage-Technologie, die besser skaliert.
Zusätzlich gewinnen hyper-konvergente Systeme, die sogenannte Hyper-Converged Infrastructure (HCI), immer mehr an Bedeutung. Diese Systeme sollen per Design ein abgeschlossenes System bilden, das nicht auf zentrale Komponenten angewiesen ist, sondern „nur noch“ eine Netzwerk-Infrastruktur benötigt. Der Storage befindet sich dabei in den einzelnen Knoten einer HCI und muss auf irgendeine Art und Weise sowohl ausfallsicher als auch zusammengefasst und performant sein.
All diese Anforderungen können verteilte, parallele Dateisysteme (Distributed Parallel Filesystems – DPFS) erfüllen. Die beiden Hauptszenarien für den Einsatz sind dabei parallele Berechnungen und Virtualisierungsumgebungen. Die zugrundeliegende Technik ist aber in beiden Fällen nahezu identisch und lediglich die Details für den Zugriff unterschiedlich.
2. Definition
Schon der Name „verteilte, parallele Dateisysteme“ beinhaltet die wesentlichen Funktionen der Technologie:
Einerseits werden die auf einem DPFS gespeicherten Daten auf viele verschiedene Systeme verteilt. Diese Systeme sind in vielen Fällen, speziell im HPC-Umfeld, dedizierte DPFS-Server. Es ist aber auch möglich, den lokalen Speicher von Clients in das DPFS einzubinden. Dabei stellen sich sämtliche Speicherressourcen gegenüber den Clients – je nach Konfiguration – als ein oder mehrere Dateisysteme dar. Dies ist ein Ansatz, der besonders bei der Nutzung in Virtualisierungsumgebungen zu finden ist.
Andererseits sind diese Dateisysteme „parallel“, d.h. einzelne Dateien werden nicht nur auf einem einzelnen System vorgehalten, sondern parallel auf mehreren Systemen. So kann beispielsweise bei einer Datei mit einer Größe von 100GB bei einem DPFS mit 100 Servern jeweils 1GB auf jedem Server abgelegt werden. Dabei kommen in vielen Fällen auch RAID-ähnliche Mechanismen zum Einsatz, um eine Redundanz zu ermöglichen.
Diese beiden Mechanismen sind maßgeblich für ein DPFS. Sonstige Funktionen wie Kompression, Deduplikation oder Thin Provisioning werden in vielen Fällen unterstützt, sind aber keine Voraussetzung für ein DPFS.
3. Geschichte
Die Entwicklung von parallelen Dateisystemen begann 1992 bei IBM. Hier wurde es unter dem Namen „Vesta“ zwischen 1992 und 1995 entwickelt. 1994 erfolgte die Vermarktung als „Parallel I/O File System“ (PIOFS).
Abgelöst wurde PIOFS von GPFS (General Parallel File System), welches 1998 in AIX Einzug erhielt. Ursprünglich wurde es konzipiert, um hohe Datenraten für Multimedia-Anwendungen (speziell Videoschnitt) zu erreichen.
Die Vorzüge eines solchen Dateisystems wurden auch im HPC-Umfeld schnell erkannt, und so wurden und werden DPFS in vielen Supercomputern der aktuellen Top500-Liste genutzt, um die Ergebnisse von aufwendigen Simulationen zu speichern. Speziell der parallele Zugriff vieler Tausende bis zu Millionen von Prozessen auf das Speichersystem ist bei einem DPFS deutlich performanter als die Nutzung eines einzelnen, zentralen Speichers.
In den folgenden Jahren wurden im HPC- aber auch im sonstigen Unix-Umfeld weitere DPFS entwickelt, die für unterschiedliche Nutzungsszenarien optimiert waren.
Jenseits dieser Nischen-Anwendungen sind parallele Dateisysteme bekannter geworden, als sie für Googles Infrastruktur und später für diverse Cloud-Dienste verwendet wurden. So nutzt Google bspw. das speziell für die Websuche optimierte „Google File System“.
Endgültigen Einzug in das Rechenzentrum fanden parallele Dateisysteme mit Nutanix (Nutanix Distributed File System –
NDFS) und VMware vSAN (ehemals VMware Virtual SAN). Bei diesen Produkten wird der lokal verfügbare Speicher der genutzten Server zusammengefasst, Redundanzen aufgebaut und als Ganzes allen beteiligten Servern zur Verfügung gestellt. Dabei ist es sogar möglich, für einzelne Dateien oder Verzeichnisse unterschiedliche Redundanzen und sonstige Funktionen zu konfigurieren.
4. Funktionsweise
So einfach die Definition eines DPFS ist, so sind die technischen Grundlagen doch kompliziert im Vergleich zu klassischen Storage-Lösungen (SAN / NAS). Die große Herausforderung bei parallelen Dateisystemen ist das Verteilen von Dateifragmenten auf eine große Anzahl von beteiligten Servern. Während bei einem klassischen RAID Dateien gleichmäßig auf die Blöcke von Festplatten verteilt werden und keine Informationen zu den eigentlichen Daten benötigt werden. Da diese Redundanz auf Blockebene funktioniert, ist dabei die effektive Größe eines RAIDs durch die Festplatte mit der geringsten Kapazität vorgegeben. Diese Beschränkungen gelten für ein DPFS nicht. Dadurch ergibt sich die Notwendigkeit, dass ein DPFS einen Mechanismus zur Verfügung stellt, mit dem die genaue Aufteilung und Position einer jeden Datei im Dateisystem protokolliert wird.
Dieser Mechanismus wird von sog. „Metadata-Servern“ (MDS) bereitgestellt. Diese werden sowohl beim Schreiben als auch beim Lesen von Dateien von den Clients genutzt, um die jeweiligen Dateien zu verteilen oder wieder zusammenzusetzen. Da bei einer großen Zahl von Clients auch hier schnell ein Flaschenhals entstehen kann, verfügen die allermeisten parallelen Dateisysteme über die Möglichkeit, mehrere MDS zu nutzen. Die Informationen zu den Speicherorten der Dateien können dabei entweder vollständig auf allen MDS vorhanden sein, oder diese Information wird ebenfalls aufgeteilt, beispielsweise auf Verzeichnis-Ebene.
Die eigentliche (verteilte, parallele) Speicherung der Dateien erfolgt auf dem sog. „Object Data Storage“ (ODS). Dabei können verschiedene Speicher-Backends genutzt werden. So können, falls vorhanden, bestehende SAN-Komponenten genutzt werden, aber auch lokal angebundener Speicher oder (in einigen Fällen) Cloud-Speicher.
Die Verbindung von MDS und ODS ermöglicht dabei eine genaue Aufteilung von Dateien auf eine nahezu beliebige Anzahl von Servern. Dieses Zusammenspiel ist in Abbildung 1 dargestellt.
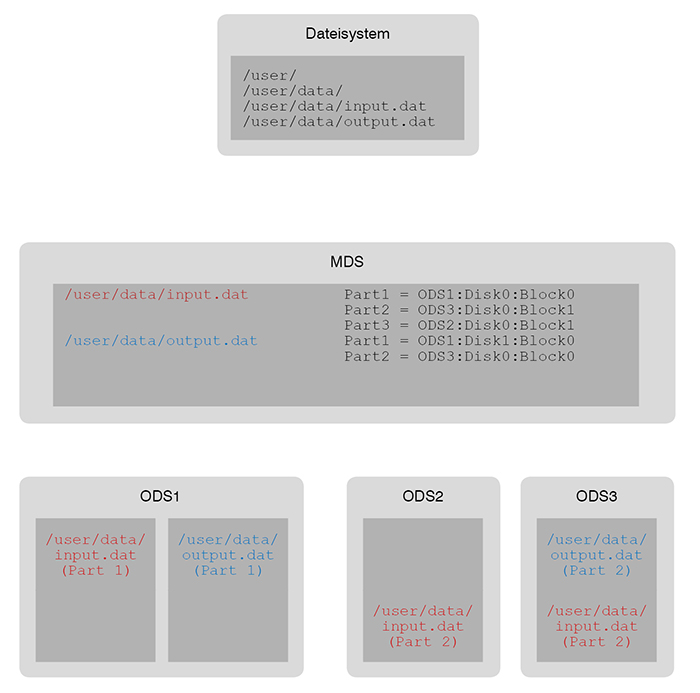
Abbildung 1: Aufteilung einer Datei in einem DPFS; Zusammenspiel zwischen MDS und ODS
Die genaue Positionierung von MDS und ODS kann sich unterscheiden. Manche Implementierungen trennen MDS und ODS, manche kombinieren sie.
Ein nicht zu unterschätzender Aspekt ist auch die Sicherheit eines solchen Systems. So muss stets sichergestellt sein, dass die Client-Anfragen auch erlaubt und korrekt sind. Die hierfür eingesetzten Mechanismen können bei jeder Implementierung variieren und werden daher an dieser Stelle nicht weiter betrachtet.
Client-Zugriffe auf ein DPFS können unterschiedlich erfolgen. Dabei unterscheidet man zwischen „direktem“ und „indirektem“ Zugriff:
Direkter Zugriff
Den größten Nutzen bietet ein DPFS, wenn sich alle Clients im selben Netzwerk befinden wie die Server und direkt auf den Speicher zugreifen können. Früher waren hierfür spezielle Interfaces notwendig, beispielsweise Infiniband, um ausreichende Bandbreiten erreichen zu können. Aber spätestens seit der Einführung von 10Gigabit-Ethernet ist dies nur noch in Ausnahmefällen notwendig. Zusätzlich benötigen die Clients eine Software, um auf das DPFS zugreifen zu können.
Beim Schreiben von Daten wird einem MDS mitgeteilt, wie groß die zu schreibenden Daten sind und dieser antwortet mit einer Liste von Positionen auf den ODS-Systemen (Abbildung 2, Schritt 1). Daraufhin werden die Daten vom Client direkt auf die ODS-Systeme geschrieben (Abbildung 2, Schritt 2).
Ein Lesevorgang funktioniert analog: Der Client fragt den MDS, wo sich welche Teile der zu lesenden Datei befinden. Daraufhin erhält der Client die Liste der relevanten Positionen (Abbildung 2, Schritt 1) und kann die Datei direkt von mehreren ODS parallel lesen (Abbildung 2, Schritt 2).
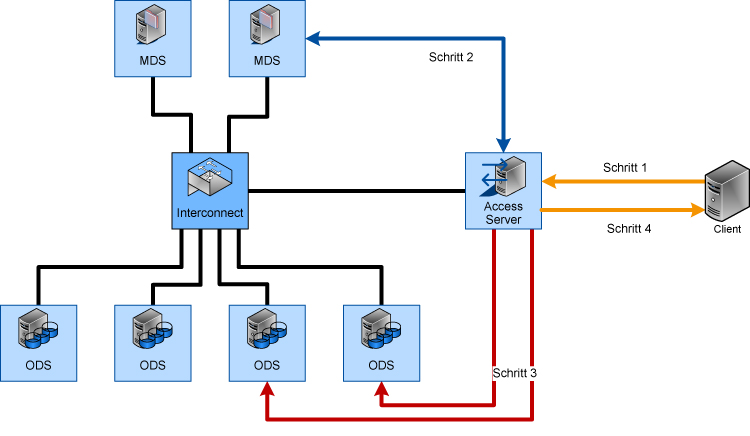
Abbildung 2: Zugriff auf ein paralleles Dateisystem
Indirekter Zugriff
Es gibt Fälle, in denen für den jeweiligen Client keine Software für den Zugriff auf das DPFS verfügbar ist, beispielsweise weil nur unixoide Betriebssysteme unterstützt werden oder aus Datenschutz- und/oder Sicherheitsgründen ein direkter Zugriff nicht erwünscht ist. In diesem Fall benötigt man für einen Zugriff der Clients einen Server, der analog zu einem „NAS-Kopf“ funktioniert (bzw. mehrere solche Server):
In Richtung des Speichers besitzt dieses System die Client-Software, um auf das DPFS zuzugreifen und verhält sich wie oben beschrieben. In Richtung der (eigentlichen) Clients wird das DPFS über ein kompatibles Protokoll (beispielsweise NFS oder SMB/CIFS) freigegeben und mit Bordmitteln der Clients angesprochen. Dies entspricht den Schritten 1 (Anfrage) und 4 (Rückmeldung) in Abbildung 3; Schritte 2 und 3 entsprechen den Lese- bzw. Schreibzugriffen aus Abbildung 2.
Hier ergibt sich allerdings erneut ein Flaschenhals, da sämtliche Daten über einen oder mehrere NAS-Köpfe laufen müssen. Zwar kann die Performance durch zusätzliche NAS-Köpfe verbessert werden, doch ab einem gewissen Punkt ist dies nicht mehr sinnvoll. Daher ist diese Art des Zugriffs im allgemeinen nicht gewünscht, aber es existieren durchaus Use-Cases dafür; so können beispielsweise die (reduzierten) Ergebnisse einer CPU- und I/O-intensiven Berechnung zu einem System zur Visualisierung und Analyse übertragen werden, das aus Kompatibilitäts- oder Sicherheitsgründen nicht direkt mit dem Speicher kommunizieren kann bzw. soll.
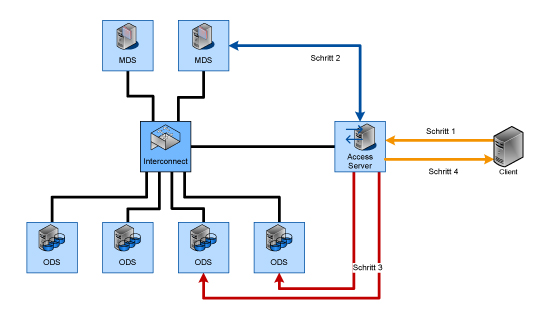
Abbildung 3: Indirekter Zugriff auf ein DPFS
Viele aktuelle DPFS bieten zusätzlich zu den grundlegenden Funktionen auch Funktionen, wie sie in traditionellen Storage-Systemen vorhanden sind:
- Redundanz:
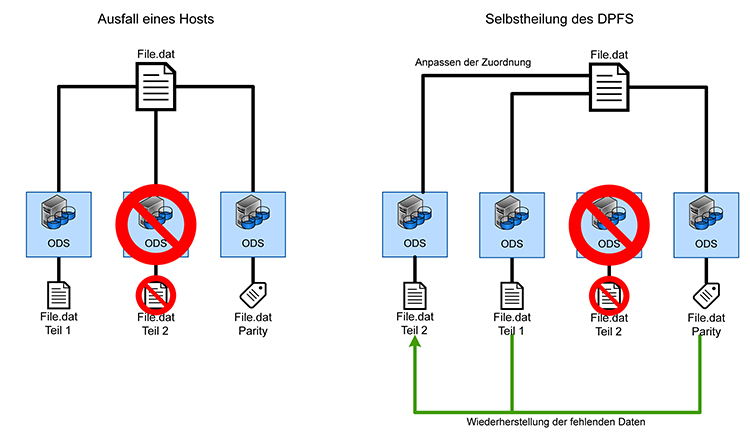
Die Verteilung der Daten erfolgt im Allgemeinen so, dass sowohl der Ausfall einer einzelnen zugrundeliegenden Speicherressource (SSD, HDD, RAID) als auch der Ausfall eines kompletten MDS oder ODS zu keinem Datenverlust führt, sondern lediglich die Performance negativ beeinflusst (Abbildung 4).
- Selbstheilung:
Bei Ausfall einer Komponente werden die dort vorhandenen Daten auf andere Systeme innerhalb des DPFS verteilt, um die ursprüngliche Fehlertoleranz wiederherzustellen (Abbildung 5).
- Datenintegrität:
Es können Mechanismen wie Checksummen, Copy-on-Write oder Redirect-on-Write genutzt werden, um Datenkorruption zu verhindern.
- Verschlüsselung:
Eine Inline-Verschlüsselung der Daten vor der Ablage auf den Speicherressourcen ist teilweise möglich. Hier leidet aber die Performance durch die erhöhte Latenz.
- Deduplizierung:
Einige DPFS-Implementierungen ermöglichen eine Online- oder Offline-Deduplizierung, um den genutzten Speicherplatz zu reduzieren.
- Thin Provisioning:
Speziell im Umfeld von HCI unterstützen DPFS die Nutzung von Thin-Provisioning von Festplatten-Images von virtuellen Maschinen.
- Tiering bei Nutzung von Flash-basiertem Speicher:
Sollten die beteiligten Server sowohl über klassische drehende Festplatten als auch über Flash-basierten Speicher verfügen, so kann ein Tiering stattfinden, welches für eine bessere Performance für häufig genutzte Daten sorgt.
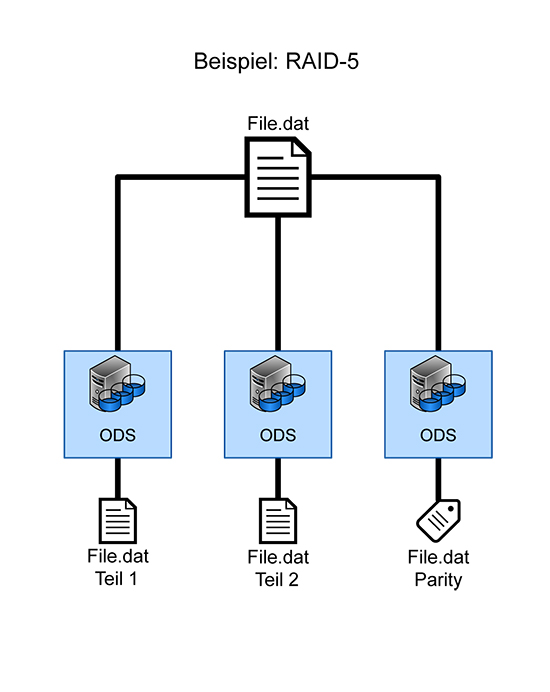
Abbildung 4: Redundanz-Mechanismen bei DPFS: Verteilung einer Datei auf drei Systeme, analog zu RAID-5
5. Vor- und Nachteile
Mit einer Übersicht über die Funktionsweise eines DPFS und der Zielsetzung für ein DPFS stellt sich die Frage, wo ein Einsatz sinnvoll sein kann. Dafür sollen die Vor- und Nachteile genauer betrachtet werden:
Vorteile
- Für ein DPFS ist keine zentrale SAN-Infrastruktur notwendig. Es können verschiedenste Storage-Backends und Netzwerk-Technologien für ein DPFS genutzt werden, meistens auf Dateisystem-Ebene.
- Ein Ausbau eines DPFS sowohl im Bereich der Kapazität als auch im Bereich der Performance ist entweder durch Hinzufügen von Servern (Performance und Kapazität) oder zusätzlichen Speicherressourcen innerhalb der bestehenden Server (Kapazität) möglich. Speziell im HPC-Bereich gibt es Lösungen, die pro beteiligtem Server Datenübertragungsraten von bis zu 60Gbit/s und 6 Millionen IOPS liefern können und nahezu linear mit der Anzahl der Server skalieren.
- Speziell bei der Nutzung von klassischen Festplatten kann die Zugriffszeit und die Übertragungsrate stark verbessert werden.
- Bei Nutzung von SSDs kann die Gesamtauslastung des Netzwerks verbessert werden, da die Anzahl der verfügbaren Server deutlich größer sein kann.
- Fehlertoleranzen können auf verschiedenen Ebenen und sehr feingranular eingerichtet werden.
Nachteile
- Die meisten DPFS sind nur über spezielle Software direkt nutzbar. Sollte für einen Client diese Software nicht verfügbar sein, so muss ein NAS-Kopf genutzt werden, der zum Flaschenhals werden kann.
- Bei einem Zugriff auf viele kleine Dateien erhöht sich die Zugriffszeit signifikant, da für jede Datei der Speicherort erst vom MDS erfragt werden muss.
- Durch den großen Performance-Gewinn bei der Nutzung von Flash-basierten Speicherressourcen (SSD, NVMe etc.) ist die Kapazität innerhalb eines einzelnen Systems durch die verfügbare Bandbreite der Netzwerkschnittstelle(n) begrenzt; so kann ab einer gewissen Anzahl von Speicherressourcen das Netzwerkinterface der begrenzende Faktor werden.
- Die Nutzung und Administration von besonderen Funktionen (Deduplizierung, Verschlüsselung, Tiering) kann bei einem DPFS aufwändiger sein als bei einem traditionellen Storage-System.
- Sollte kein Hochleistungsnetzwerk (Bandbreite >= 40Gbit/s) oder kein dediziertes Netzwerk für den DPFS-Traffic genutzt werden, können sich Storage- und Produktivdaten durch die begrenzte Bandbreite gegenseitig negativ beeinflussen.
- Der Zugriff auf ein DPFS erfolgt auf Dateiebene. Zur Nutzung eines DPFS als Block-Storage muss entweder eine entsprechende Funktionalität vorhanden sein oder ein entsprechendes System zwischen DPFS und Client positioniert sein, analog zu einem NAS-Kopf.