
aus dem Netzwerk Insider April 2022
Ausgehend von der „Königsklasse“ Kritische Infrastrukturen will dieser Artikel Denkanstöße und Beispiele geben sowie auf nützliche Quellen hinweisen. Hintergrund sind ComConsult-Erfahrungen rund um kritische IT, aus KRITIS- und nicht-KRITIS-Umgebungen.
Fällt IT aus Sicht des Kerngeschäfts oder wichtiger Versorgungsketten länger aus, kann sich das kritisch auswirken. Bedrohungen durch Cyber-Kriminelle sind allgegenwärtig. Angriffe aus politischen Gründen machen immer wieder Schlagzeilen. Corona-Pandemie und jüngste Wetterkatastrophen haben gezeigt, dass solche Szenarien keine graue Theorie sind.
Besondere Absicherung ist schnell besonders teuer und aufwändig. Effektiver Schutz für Kritisches und Verhältnismäßigkeit sind schwer in eine gute Balance zu bringen.
Praxissicht zum Begriff „kritisch“ und zu Ketten schädlicher Folgen
Von kritischen Infrastrukturen war in letzter Zeit häufiger in der Tagespresse die Rede. Es handelt sich daher nicht länger um einen Begriff im Wortschatz von Spezialisten und Insidern. Warum kam es zu dieser verstärkten Erwähnung? Der Grund sind gefährliche Entwicklungen bei Rahmenbedingungen, deren Folgeschäden für die Bevölkerung und im täglichen Leben stark spürbar werden können oder geworden sind.
Ein in der Corona-Pandemie angefallenes Beispiel sind Engpässe bei Lebensmitteln und anderen Waren. Wegen der erhöhten Omikron-Ansteckungsgefahr wurden zudem vorsorglich Betrachtungen für Szenarien angestellt, bei denen durch hohe Kranken- und Quarantäne-Stände beim Personal Feuerwehren nicht in gewohnter Weise reagieren könnten, usw.
Die Besonderheit, weshalb solche möglichen oder tatsächlichen Engpässe Schlagzeilen machen, ist ein flächiges Auftreten. Auf leere Regale im einzelnen Supermarkt kann man als Kunde durch Einkaufen bei der Konkurrenz selbständig reagieren. Bei Ausfall einer einzelnen Feuerwache oder bei Personalengpass eines einzelnen Krankenhauses lässt sich organisieren, dass andere vergleichbare Einheiten zeitweilig übernehmen. Sind allerdings die Ausweichmöglichkeiten in einer bestimmten Gegend ebenfalls betroffen, wird es schwierig zu kompensieren: Eine ganze Infrastruktur zur Versorgung der Bevölkerung wird dann mindestens in einem bestimmten geographischen Gebiet am „Liefern“ gehindert.
Für die betroffene Bevölkerung gilt: Je näher der Mangel am täglichen Bedarf ist, umso stärker ist die Wirkung, wenn die übliche Versorgung nicht nur kurzzeitig eingeschränkt ist.
Die schädliche Wirkung kann sich durch Verkettung und Folgeschäden weiter verstärken. Fällt z.B. in einem Stadtgebiet für einige Zeit der Strom aus, passiert unter anderem Folgendes: Kühlräume und -theken setzen zeitweilig aus. Darin gelagerte verderbliche Lebensmittel tauen auf. Sie können je nach Fall nicht mehr ohne Gefahr für die Gesundheit der Kunden zum Verkauf und Verzehr angeboten werden. Bis Nachschub geliefert werden kann, besteht somit in der vom Stromausfall betroffenen Gegend bei solchen Lebensmitteln ein Engpass.
Beim planvollen Umgang mit derartigen komplexeren Szenarien tun sich selbst Profis aus dem Umfeld kritischer Infrastrukturen immer wieder schwer. Entweder ist das Denken über das auslösende Schadensereignis hinaus zu ungewohnt, oder man ist zu sehr auf die unmittelbar betroffene Technik fixiert. Außerdem schwingt verständlicherweise immer der Aspekt der Wirtschaftlichkeit mit. Verhältnismäßigkeit ist da ein schwieriges Ziel. Man schreckt vor dem Weiterdenken zurück.
Der vorliegende Artikel will, anders als andere eher technisch fokussierte Veröffentlichungen, insbesondere den Umgang mit dieser Schwierigkeit, zugehörigen Anforderungen und Hilfsmitteln beleuchten. Ein wichtiger Gesichtspunkt ist hierbei das Verständnis für notwendige, zunächst viele ungewohnte Denkweisen.
Beispiele mit bewusst breiterer thematischer Streuung sollen dabei helfen. Oft gibt es vermeintliche Nebenschauplätze, die nach den Erfahrungen aus der ComConsult-Beratungspraxis leicht vergessen oder vernachlässigt werden, wenn man nicht gezielt daran erinnert.
Was können Unternehmen bzw. öffentliche Einrichtungen (Sammelbegriff: „Institutionen“) in diesem Zusammenhang mit Ausführungen rund um Kritische Infrastrukturen anfangen?
Die für Kritische Infrastrukturen besonders schwerwiegenden Aspekte lassen sich leicht auf Bedarf und Versorgung jeglicher Institution übertragen. Man konzentriert sich für die konkret betrachtete Umgebung darauf, wo schädliche Vorfälle in folgender Form wirken können:
- Die Institution wird in ihrer Arbeit massiv gestört und behindert.
- Der schädliche Vorfall und seine Wirkung können sich aus Sicht der Institution durch Abhängigkeitsketten verstärken.
Tätigkeiten zum Kerngeschäft sind von intern bereitgestellter Ausstattung abhängig. Bereits hier kommt es zu Abhängigkeitsketten: Das Endgerät benötigt Vernetzung und Basisdienste, um überhaupt nutzbar zu sein. Basisdienste sind des Weiteren nötig, um den Zugriff auf zentrale Anwendungen und Daten zu ermöglichen und zu kontrollieren. Netzstörungen oder Probleme mit Basisdiensten können mittelbar den Zugriff zu an sich verfügbaren Anwendungen behindern oder völlig unmöglich machen.
Es entsteht eine Wirkungskette, bei der beispielsweise wegen punktueller Störung eines Dienstes (auslösender Vorfall) für wichtige Tätigkeiten die notwendigen Daten und Anwendungen nicht zugänglich sind.
Werden Teile einer solchen Kette nicht intern, sondern durch Externe betrieben, ist man von diesen und deren Serviceorganisation abhängig. Diese kann sich wiederum auf Leistungen anderer abstützen.
- Eine kritische Schadenswirkung aus Sicht der Institution kann entstehen, wenn es um Tätigkeiten geht, die täglich anfallen bzw. bei denen eine längere Beeinträchtigung oder gar völliger Stopp an einem Tag bereits deutlich negative Folgen hat.
Negative Folgen können etwa unmittelbare wirtschaftliche Verluste sein, oder unangenehme und schwierig organisierbare kurzfristige Mehrarbeit, um Liegengebliebenes zügig nachzuholen.
Nachwirkende schädliche Folgen können zudem durch negative Außenwirkung entstehen – im Falle von Unternehmen z.B. durch Verunsicherung und Ausweichreaktionen der Kunden: Plötzlich wird auch für Stammkunden ein möglicher Wettbewerber interessant, man nehme das Beispiel vom einzelnen Supermarkt mit leeren Regalen.
Kundenbindung ist wertvoll. Es ist bereits ärgerlich, wenn gute Kunden unnötig einmalig bei der Konkurrenz vorbeischauen und dort gute Erfahrungen machen. Wandert eine Großzahl dieser Kunden dann anteilig oder vollständig zum Wettbewerber ab, kann dies kurzfristig schwierig kompensiert, gar kritisch werden. Aus der Unternehmensperspektive fängt hier „kritisch“ deutlich früher an als damit, dass die Versorgung größerer Teile der Bevölkerung beeinträchtigt wird.
Insofern richten sich die nachfolgenden Ausführungen nicht nur an Betreiber Kritischer Infrastrukturen. Diese wiederum finden im Weiteren über die Auswahl beleuchteter Aspekte und Beispiele Anreize dafür, sich erneut zu überprüfen. Vielleicht hat man ja etwas übersehen oder vernachlässigt, an das man durch eines der Beispiele erinnert wird.
Starten wir mit einem einfachen Beispiel aus dem oben erwähnten Bereich vermeintlicher Nebenschauplätze, die sich schrittweise aufschaukeln können, wenn man unzureichend darauf vorbereitet ist:
Jede Institution ist bei grundlegenden Versorgungsleistungen betroffen, wenn die Versorgung an einem ihrer Standorte länger wegfällt.
- Selbst wenn man fließendes Wasser nur für die Versorgung von Büro-Toiletten benötigt, wird ein stundenlanger Ausfall schnell zu einem unangenehmen Problem. Wer Wasser für die Produktion braucht, ist natürlich sofort schwerer beeinträchtigt.
- Fallen IT-Netze und Providerdienste zur Außenanbindung aus, ist man für Kunden, Partner usw. nicht erreichbar und kommt nicht an akut benötigte Informationen. Für die eine Institution ist der Zugang zu aktuellen Informationen dringender, für die andere ist die mangelnde Erreichbarkeit schneller gefährlich.
- Fällt die Stromversorgung für die ganze Arbeitsumgebung längere Zeit aus, muss man das Personal nach Hause schicken.
Bei solchen Problemen ist das Arbeiten im Homeoffice nicht überall eine machbare Alternative. Dann kommt es unweigerlich zu Produktivitätsausfällen, oder man kann vorübergehend mit Eigenversorgung überbrücken. Eine kleine Ausweichlösung bei Stromausfall ist die Nutzung von Endgeräten mit Akkus. Aufwändigere Optionen, an die IT-Profis sofort denken werden, sind Unterbrechungsfreie Spannungsversorgung (USV) und Netzersatzanlage (NEA).
Soweit Remote-Erbringung der Arbeitsleistung möglich ist, kann man Probleme am Arbeitsplatz des Standortes der Institution durch Homeoffice-Arbeit abfedern. Nur hilft das nicht, wenn die nötige Ausstattung zum mobilen Arbeiten nicht da, mit zu geringer Kapazität vorhanden oder nicht zügig zur Hand ist.
Bei Bedarf an erhöhter Verfügbarkeit denken viele automatisch an zentrale IT-Angebote oder solche in Produktionsbereichen. Das kleine Beispiel rund um den „IT-Arbeitsplatz“ zeigt, dass dies nicht reicht. Betrachtungen von schwerwiegenden Schadenswirkungen durch Nicht-Nutzbarkeit von IT-Services und IT-Lösungen schließen alles ein, was wie folgt einzuordnen ist:
- „kritische“ IT-Lösungen und IT-Services, die für absolut Wichtiges relevant sind
Bei kritischen Infrastrukturen gemäß dem gleich zu erläuternden KRITIS-Begriff sind IT-gestützte Lieferungen und Leistungen unmittelbar für die Versorgung der Bevölkerung wichtig. Fällt solche IT und in der Folge Lieferung und Leistung für die Bevölkerung länger aus, kann dies zu empfindlichen, auch dauerhaften Schäden führen. Größere Anzahlen von Personen können nachhaltig gesundheitlich oder wirtschaftlich stark geschädigt werden, insbesondere dann, wenn der Versorgungsmangel länger anhält. Es kann je nach Art der IT-gestützten Leistung sogar zu existenziellen Bedrohungen kommen (Gefahr für Leib und Leben, oder Vernichtung der bisherigen wirtschaftlichen Existenz).
Bei Unternehmen, die nicht unmittelbar mit Betrieb oder Leistungen für kritische Infrastrukturen zu tun haben, ist „absolut Wichtiges“ das, was Wettbewerbsfähigkeit, Erfolg und Bestand des Unternehmens ausmacht. Hierfür werden Begriffe wie „Kronjuwelen“ und „Kernprozesse“ genutzt.
- IT-Lösungen als Teile von Abhängigkeitsketten mit breiter Schadenswirkung
Die Komplexität der zu berücksichtigenden Abhängigkeiten nimmt ständig zu. Man muss weiterdenken als nur bis zum unmittelbaren Ausgangspunkt in Form einer lokalen Störung. Auch Verhältnismäßigkeitsbetrachtungen zu Aufwand und Kosten für die Wiederherstellung des normalen Zustands müssen Folgeschäden bis zum Ende einer Schadenskette einbeziehen.
Grundsätzlich kennt das jeder, z.B. in Zusammenhang mit (Internet-)Service-Providern. Mehr als einmal ist es dazu gekommen, dass Probleme bei einem einzelnen Provider ihre Wirkung weit über den Kundenkreis dieses Providers hinaus entfaltet haben.
Mal ist es ein Fehler bei einem Basisdienst wie DNS, mal ein scheinbarer Routine-Change im Bereich Routing mit einem ungewollt eingebauten Detailfehler: Erst fallen Services beim verursachenden Provider aus, dann hakt es bei seiner unmittelbaren Konkurrenz und bei anderen Angeboten, die wegen der entstehenden Kommunikationsprobleme mittelbar betroffen sind.
Wer etwas zu einem Beispiel für Breitenwirkung solcher Fehlerfortpflanzung lesen will, kann hier nachlesen: https://www.comconsult.com/lehren-azure-cloud-incident/. In jenem Kurzartikel ist neben dem breiten Wirkbereich insbesondere die vorgeführte Vorgehensweise, aus einem solchen Vorfall Lehren zu ziehen, wichtig.
Der Begriff „Kritische Infrastruktur“ formalisiert die Thematik mit Blick auf Schadenswirkungen für größere Teile der Bevölkerung. Er bildet die Grundlage für Regularien und Vorgehensweisen mit rechtlicher Verbindlichkeit für die Betreiber solcher Infrastrukturen. Der Begriff wurde zuletzt häufiger in den Medien erwähnt. Trotzdem kennt nicht jeder die zugehörigen Regularien, Anforderungen und Hilfsmittel, wenn er nicht Verantwortlicher für eine regulierte Umgebung und damit unmittelbar betroffen ist. Man kann jedoch auch als nicht unmittelbar Betroffener davon abschauen, wie man strukturiert und konsequent mit als kritisch eingestufter Technik umgeht.
Die nachfolgende Kurzeinführung konzentriert sich darauf, das Verständnis für „kritisch“ in Zusammenhang mit Schadensausmaß und Wirkbereich weiter zu verfestigen. IT ist in vielen Fällen nicht die unmittelbar wichtige Versorgungsleistung. Sie wird dadurch kritisch, dass sie für kritische Leistungen und Prozesse dringend benötigt wird.
Kritische Infrastrukturen und kritische IT
Was macht eine Infrastruktur und dementsprechend eine IT-Ausstattung (einen IT-Service, eine IT-Lösung) kritisch?
Formal und mit verbindlichen regulatorischen Folgen wird im Geltungsbereich der bundesdeutschen Gesetzgebung der Begriff einer „Kritischen Infrastruktur“ so definiert:
„Kritische Infrastrukturen (KRITIS) sind Organisationen oder Einrichtungen mit wichtiger Bedeutung für das staatliche Gemeinwesen, bei deren Ausfall oder Beeinträchtigung nachhaltig wirkende Versorgungsengpässe, erhebliche Störungen der öffentlichen Sicherheit oder andere dramatische Folgen eintreten würden.“
Beispielsweise https://www.bbk.bund.de/DE/Themen/Kritische-Infrastrukturen/kritische-infrastrukturen_node.html zitiert dies als KRITIS-Definition der Bundesressorts. Eine wortlautgleiche Definition findet man auf den Webseiten des Bundesamtes für Sicherheit in der Informationstechnik zum Themengebiet „KRITIS und regulierte Unternehmen“.
Die zunächst etwas trockene und sperrige Formulierung „Bedeutung für das staatliche Gemeinwesen“ ist gar nicht so schwer zugänglich, wenn man sich an die bislang erläuterten Beispiele erinnert. In mehreren Fällen war die Bevölkerung als zu versorgende Zielgruppe betroffen, im Beispiel Netzprovider schnell mit überregionalem Schadensbild. Beachtet man die in der Definition enthaltene Passage „… Störung der öffentlichen Sicherheit …“, kommt ein weiterer Leistungsbereich hinzu. Im Rahmen einer „Nationalen Strategie zum Schutz Kritischer Infrastrukturen (KRITIS-Strategie)“ wurde in 2009 die Gesamtheit von Kritischen Infrastrukturen zunächst über die folgenden neun „Sektoren“ erfasst:
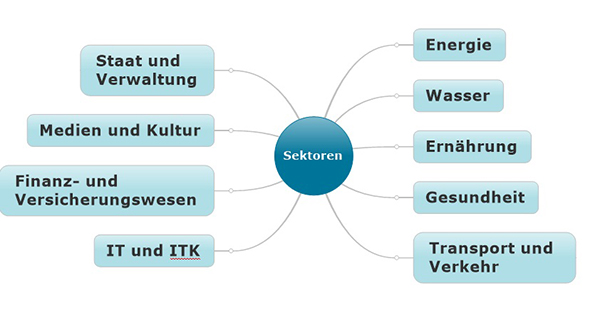
Abbildung 1: Die Gesamtheit Kritischer Infrastrukturen in Sektoren gegliedert
Das Gesetz über das Bundesamt für Sicherheit in der Informationstechnik (BSI-Gesetz) legt den Fokus etwas enger auf Infrastrukturen in den Sektoren
- Energie,
- Informationstechnik und Telekommunikation,
- Transport und Verkehr,
- Gesundheit,
- Wasser,
- Ernährung,
- Finanz- und Versicherungswesen sowie Siedlungsabfallentsorgung.
(Die Siedlungsabfallentsorgung ist mit der Aktualisierung zur „2. Fassung des BSI-Gesetzes“ hinzugekommen.)
Im Falle der öffentlichen Verwaltung kann man sich die Nichtnennung in dieser Aufzählung dadurch erklären, dass diese auf anderem Wege im Maßgeblichkeitsbereich des BSI liegt. Hier bedarf es keiner zusätzlichen gesetzlichen Grundlage.
Medien sind ebenfalls wichtig. Wir leben und arbeiten in einer Informationsgesellschaft. Die Unwetterereignisse in 2021 haben zudem vorgeführt, dass die Medien bei der notwendigen Information der Bevölkerung zur Lage eine wichtige Rolle spielen (Notfallkommunikation). Auf gewisse Sirenensignale hin soll man sich gezielt über lokale Medien genauer informieren. Selbst moderne Apps wie NINA oder KATWARN haben Grenzen bzgl. Reichweite innerhalb der Bevölkerung. Bei eher lokalen Ereignissen verweisen auch sie fallweise auf weitere Informationen über Rundfunk etc.
Medien wurden im BSI-Gesetz dennoch ausgeklammert, weil dieses sich auf die Sicherheit und Aufrechterhaltung technischer Infrastrukturen konzentriere. So wird es im Dokument „Medien und Journalisten im Kontext von ‚Kritischer Infrastruktur‘ und „Systemrelevanz“ vom Wissenschaftlichen Dienst des Bundestages erläutert (WD 10 – 3000 – 016/20, https://www.bundestag.de/resource/blob/691856/9f7d74b63d25edcac723005261905d88/WD-10-016-20-pdf-data.pdf).
Ob ein Unternehmen entsprechend der grundlegenden KRITIS-Definition reguliert ist, entscheidet sich über weitere verbindliche Festlegungen in Gesetzen und Verordnungen. Stichworte wie IT-Sicherheitsgesetz und das schon erwähnte BSI-Gesetz (BSIG) hat vermutlich jeder schon einmal gehört, der mit IT zu tun hat.
Die „Verordnung zur Bestimmung Kritischer Infrastrukturen nach dem BSI-Gesetz (BSI-Kritisverordnung – BSI-KritisV)“ sagt dann genauer, über welche Kennzahlen und zugehörigen Schwellenwerte sich je Sektor endscheidet, ob man „KRITIS ist“, d.h. umfassend in den Geltungsbereich der entsprechenden Regularien fällt. Hier drückt sich der Aspekt „hohes Schadensausmaß über Breitenwirkung“ im Formalismus aus.
Schwellwerte bringen messbare Klarheit, wann die Regularien verbindlich greifen bzw. wann man freiwillig nützliche Ideen abgucken kann. Wer unter solchen Schwellwerten bleibt, unterliegt nicht den Detailregularien für Betreiber Kritischer Infrastrukturen und muss nicht zwingend die Anforderungen von §8a BSIG „Sicherheit in der Informationstechnik Kritischer Infrastrukturen“ erfüllen. Wesentliche Anforderungen sind:
- Es sind angemessene organisatorische und technische Vorkehrungen zu treffen, sofern die Informationstechnik für die Funktionsfähigkeit der betriebenen Kritischen Infrastrukturen maßgeblich ist. Die Vorkehrungen müssen der KRITIS-Einstufung entsprechen, um Verfügbarkeit, Integrität, Authentizität und Vertraulichkeit bei IT-Systemen, Komponenten oder Prozessen angemessen zu gewährleisten.
- Die organisatorischen und technischen Vorkehrungen müssen den Stand der Technik abbilden.
- Die entsprechende Dokumentation muss alle zwei Jahre zur Prüfung offengelegt werden.
- Prüfungen durch das BSI oder im Auftrag des BSI sind zu dulden.
„Angemessen“ im ersten Aufzählungspunkt wird in §8a dadurch beschränkt, dass der erforderliche Aufwand nicht unverhältnismäßig im Vergleich zu den Folgen eines Ausfalls oder der Beeinträchtigung der betroffenen Kritischen Infrastruktur sein soll. Sofern die Funktion einer Infrastruktur „kritisch für die Bevölkerung“ ist, ahnt man intuitiv, dass der erwartete Aufwand schon stark überdurchschnittlich sein muss, bis diese Deckelung greift. Wer Betreiber einer in diesem Sinne kritischen Anlage ist oder eine kritische Dienstleistung (kDL) erbringt, kennt das.
Sinnbildlich kann man diese Idee des besonderen Aufwands wieder auf den eigenen Fall übertragen, indem man sich auf die umgebungskritischen Vorgänge konzentriert und entscheidet, welche Restrisiken man zugunsten der Verhältnismäßigkeit noch tragen kann:
- IT und Informationen, die dafür nötig sind, müssen nicht nur möglichst verfügbar, sondern auch inhaltlich verlässlich sein (siehe Integritätsbegriff z.B. nach BSI-Grundschutz-Standards).
Für die aus eigener Einschätzung kritische IT muss hier im Kopf eine erste Grenzlinie in der eigenen Risikobetrachtung fallen, die man lange Zeit gerne gezogen hat: Die Beschäftigung mit Krisen- oder Katastrophensituationen („K-Fall“) als Auslöser.
- IT und Informationen mit Bedeutung für umgebungskritische Vorgänge sollten nicht in den Zugriff Unbefugter gelangen.
Dies dient der Wahrung von wettbewerbs- oder datenschutzkritischen Informationen (Vertraulichkeit). Es erschwert zudem Angriffe auf die Verfügbarkeit, da entsprechend geschützte Informationen und IT-Lösungen nicht als Ausgangsbasis für weiterführende destruktive Schritte genutzt werden können.
Was ist „besonders“ beim Umgang mit kritischer IT?
Besonderheiten erkannt man in der Praxis und durch entsprechende Inhalte der für KRITIS-Betreiber relevanten oder als Hilfestellung verfügbaren Dokumente. Wichtige Beispiele sind:
- Ein besonderer Schwerpunkt auf möglichst durchgängige Verfügbarkeit
Gibt es bei kritischer IT eine längere Phase der Nicht-Verfügbarkeit, droht in der Folge beträchtlicher Schaden für „die Gesellschaft“ bzw. die Institution.
Mögliche Risikoübernahmen für minder wichtige IT oder der Versuch, sich über Sanktionen für Verursacher längerer Ausfälle zu schützen, sind hier zu schwach für die notwendige Schadensbegrenzung. Man muss wirksame Maßnahmen zur Schadensvermeidung und die Fähigkeit zum schnellen Umgang mit nicht vermeidbaren Schadensereignissen zu einem wirksamen Bündel kombinieren.
- Das Achten auf ein durchgängiges Niveau der getroffenen Maßnahmen „Ende zu Ende“
Es nützt nur bedingt, wenn man an einzelnen Punkten einer IT-Ausstattung hohen und höchsten Aufwand zur Risikoreduzierung leistet, dies an den Arbeitsplätzen der Nutzergruppen jedoch nicht entsprechend ankommt.
Das schwächste Glied in einer IT-Lösungskette bestimmt maßgeblich das Niveau, das verlässlich erreicht werden kann. Hier geht es um eine technische Abhängigkeitskette innerhalb einer Gesamtlösung, wie bei einer HiFi-Anlage (Prinzip „HiFi-Anlage“). Beispiel: Wieviel nützen hochverfügbare Lösungen im Rechenzentrum oder beim Cloud-Anbieter, wenn die für den Zugriff genutzte Netzanbindung ein Wackelkandidat ist?
Ein vermeintlicher Nebenschauplatz in diesem Zusammenhang, der angesichts aktuell zu beobachtender besonderer Fertigungs- und Lieferprobleme eventuell neu zu prüfen ist:
Die Endgeräteausstattung für Arbeitsplätze mit kritischen Aufgaben muss gewährleistet bleiben, auch wenn es dort zu gleichzeitigen Geräteausfällen kommt. Wieviel Wartezeit ist hier erträglich, wie realistisch können bisherige Vorkehrungen bzgl. Ersatzlieferung noch wie geplant wirken? Diese Fragen gelten für reine Abstützung auf schnelle Ersatzlieferung ebenso wie zum Auffüllen eines Endgerätevorrats nach Entnahmen zum Tausch gegen defekte Geräte. Außerdem muss ein geplanter eigener Vorrat nötigenfalls angemessen mitwachsen, wenn die Anzahl dadurch abgesicherter kritischer Arbeitsplatzausstattungen zunimmt.
- Ein planvoller Umgang mit Informationssicherheit als Schwerpunkt
Ganz ohne IT-Ausstattung kommt man fast nirgendwo mehr aus. Soweit man IT für sich als kritisch erkannt hat, kann man verschärfend sagen: Wenig bis nichts geht mehr ohne diese IT. Fortschreitende Digitalisierung wird die Bedeutung von IT-Ausstattung weiter erhöhen. Gleichzeitig ist es eine Tatsache, dass ein Angriff auf IT-Infrastrukturen und IT-Ausstattung eine alltägliche Gefahr darstellt.
Es ist nachvollziehbar, dass Betreiber kritischer Infrastrukturen damit planvoll umgehen müssen. „Cyberwar“-artige Überlegungen und Szenarien betrachten gezielte Angriffe auf Informationssicherheit und IT-Infrastrukturen, über die Flächenwirkung erreicht werden kann. Es sollen öffentliches Leben und die Versorgung der Bevölkerung schwerwiegend beeinträchtigt oder kontrolliert werden. Eine Beeinträchtigung der Versorgung mit Lebensnotwendigem ist für rein destruktive Angriffsszenarien eine bedeutende Drohkulisse. Dazu ist ein Angriff auf Technik und Informationen, ohne die diese Versorgung kaum funktionieren kann, ein wirksamer Ansatzpunkt.
KRITIS-Betreiber haben entsprechend zwingend Sicherheitsprozesse, die strukturiert und koordiniert in der Art eines Informationssicherheits-Management-Systems (ISMS) funktionieren.
Systematisches Vorgehen allein schafft noch kein dem Risiko angemessenes Niveau von Schutzmaßnahmen. Soweit Informationen und IT kritisch sind, lassen sich Risikoübernahmen nur mit Machbarkeit und Verhältnismäßigkeit begründen. Im KRITIS-Fall ist hier die strenge Auslegung von „angemessen“ nach §8a BSIG maßgeblich. Risikoverlagerungen durch Maßnahmen wie Versicherungen sind mit Blick auf die Versorgung der Bevölkerung schwer denkbar.
Erst wenn man Sicherheitskonzepte und deren Umsetzung so auslegt, dass man Risiken im Sinne der „kritisch“-Einstufung betrachtet und entschärft, und dies nach Stand der Technik tut, kann man dem Anspruch von §8a BSIG gerecht werden. „Stand der Technik“ signalisiert dabei: Die gefundenen Lösungen müssen regelmäßig auf den Prüfstand, denn neue Erkenntnisse und Erfahrungen sowie neue technische Lösungen und Produkte aktualisieren den Stand der Technik immer wieder.
In angemessener, d.h. verhältnismäßiger Weise sollte das alles auch beim Umgang mit kritischer IT bei nicht-KRITIS-Umgebungen verstanden und gelebt werden:
Eine Institution muss nicht KRITIS-Bedeutung haben, um für einen Angreifer interessant zu sein. „Cyber-Kriminelle“ werden ausreichend zahlungskräftige, doch nicht zu wehrhafte Opfer bevorzugen. Warum sich mit den Schutzmaßnahmen eines KRITIS-Betreibers messen, wenn man einen oder mehrere Institutionen desselben Sektors angreifen und erpressen kann, die weniger Aufwand bzgl. Sicherheitsvorkehrungen betreiben (Prinzip „leichte Beute machen“)?
- Eine ausgewogene Kombination von Prävention und Handlungsfähigkeit im Notfall
Bisher genannte Punkte werden viele intuitiv mit Vorfallvermeidung durch Prävention verbinden, hier: Vermeidung eines Ausfalls von Kernprozessen und Kerngeschäft bzw. bei kritischen Versorgungsleistungen.
Erhöhte Ausfallsicherheit durch Redundanz muss man da nicht als Ansatz erklären. Man kann höchstens daran erinnern, dass bei kritischer IT Mehrfachredundanz und Risikostreuung, letztere auch mit Blick auf Gefährdungen aus der Umgebung des Betriebsorts, für angemessene Prävention zu erwägen sind. Ähnlich ist es mit Prävention im ISMS: Man schnürt ein Bündel präventiver Sicherheitsmaßnahmen, statt sich auf eine einzige zu verlassen, egal wie hoch deren wahrscheinliche Wirksamkeit eingeschätzt wird.
Allerdings weiß der erfahrene IT-Praktiker, dass 100% wirksame Prävention weder praktikabel ist, noch mit verhältnismäßigem Aufwand realisierbar wäre. Irgendwann kommt ein Break-even-Punkt, wo Vorbereitung auf ein nicht vermeidbares Schadensereignis „billiger“ ist als der Versuch von noch mehr Prävention. Insbesondere im ISMS-Bereich kommt man oft an Stellen, wo man zwischen scharfer Prävention und benötigtem IT-Nutzen für die Arbeitsfähigkeit abwägen muss. Was nützt ein Schutzpanzer, der einem die notwendige Bewegungsfreiheit nimmt?
Im Falle kritischer IT müssen analog Vorkehrungen getroffen werden, um für einen trotz hoher Prävention eingetretenen Notfall angemessen gerüstet zu sein. Das geht über einfache Standard-Vorkehrungen wie die Möglichkeit zum Restore aus regelmäßigen Backups hinaus.
Um Prozess-Stopp bzw. Versorgungskrisen zu vermeiden, benötigt man eine Kombination aus Sofortmaßnahmen für Schadensbegrenzung und schnellem Wiederanlauf, vorbereiteten Notbetriebsformen und vorbereiteten Wiederherstellungsverfahren. Ebenso wichtig für die notwendige Wirksamkeit solcher Notfallvorsorge: Man muss das alles effektiv beherrschen und pflegen.
- Die Berücksichtigung einer „Verkettung ungünstiger Umstände“
Mit Blick auf kritische Ausstattung und damit insbesondere auf kritische IT kann es zu wenig sein, sich mit einer einzelnen Maßnahme auf Durchschnittsniveau abzusichern. Unter ungünstigen Umständen kann eine an sich erprobte Maßnahme zu wenig schadensbegrenzend sein, etwa, weil sie zu spät greift und wirkt.
Ungünstige Umstände können in einem Zusammentreffen zweier Störeffekte bestehen. Man muss sich mit „Fehler im Fehler“-artigen Szenarien auseinandersetzen. Dies ist eine ungeliebte und gern gemiedene Denkweise. Es drohen weiterer Aufwand und zusätzliche Kosten, wenn man vorgesehene Maßnahmen daran orientiert auslegt, auch derartige Szenarien in vorbereiteter Form beherrschen zu können.
„Maßhalten mit Augenmaß“ über bewusste Entscheidungen kann sich bei kritischer Ausstattung jedoch schnell als wirtschaftlicher herausstellen als ein vorzeitiger Denkstopp an dieser Stelle. Wo bleibt die Kostenoptimierung, wenn man für kritische IT aufwändige und teure Vorsorge mit Maßnahmen trifft, die dann wegen durchaus nicht unrealistischer Umstände viel zu spät wirken? Wirken getroffene besonders kostspielige Maßnahmen nicht so gut wie gedacht, kommt es trotz des hohen Vorsorgeaufwands zu überlanger Störungs- oder Notfalldauer. Der in einem solchen Fall mögliche Schaden ist nicht wesentlich geringer, als wenn man durchschnittliche Vorsorge auf deutlich billigerem Niveau getroffen hätte.
Wo man wegen Fehler-im-Fehler-Überlegungen bei der Risikoreduzierung nochmal nachlegt, hängt vom Einzelfall und den konkreten Rahmenbedingungen ab. Als Beispiel betrachte man eingekaufte Drittleistungen im Bereich „schnelle Ersatzlieferung“:
Just-in-time kann optimal wirken und kostengünstig sein, wenn es denn funktioniert. Eine Behinderung der Anlieferung kann allerdings aus Gründen, die keine abwegigen Ausnahmefälle darstellen, jederzeit vorkommen: Sperrung der optimalen Lieferroute wegen eines Unfalls oder wegen akut zu beseitigender Sturmschäden, verlängerte Anfahrzeiten des Lieferanten wegen Staus oder rutschiger Fahrbahn, usw. Je geringere Alternativen es bei der Wahl der Anfahrtstrecke für den Lieferanten gibt, umso eher kann so eine Situation genau dann eintreffen, wenn man gerade zur Fehlerbehebung eine dringende Lieferung benötigt. (Vergleichbares gilt ebenfalls, wenn für die endgültige Fehlerbeseitigung ein Einsatz externer Techniker vorgesehen ist.)
Wer sich von diesem Beispiel getroffen sieht, hat mehrere Prüfpunkte und Optionen zur Optimierung. Er kann etwa die Plausibilität von „späteste Lieferung bis“-Angeboten prüfen (wo befindet sich die Lieferlogistik des Dienstleisters relativ zum eigenen Standort?) und zeitlichen Puffer gewinnen, über den er Schwierigkeiten mit prompter Lieferung überbrückt. Eine Möglichkeit ist eine bedingte eigene Vorratshaltung von Ersatz, reserviert für Entstörung. Ein anderes Beispiel sind vor Ort vorbereitete, also ohne Lieferung von außen nutzbare Workarounds. Diese können als Ausweichlösung etwas den Zeitdruck aus der Wiederherstellung des Normalzustands herausnehmen, für die eine ausstehende Ersatzlieferung benötigt wird.
Eigene Vorratshaltung kann man in Grenzen so gestalten, dass eigenes ungenutztes Eigentum mit Wertverlust „beim Herumstehen“ vermieden wird. Das Einplanen von Testkomponenten als Störungsreserve ist ein häufig gesehener Ansatz. Eine Einlagerung von Ersatzkomponenten durch den Support-Dienstleister vor Ort, die bis zur Inbetriebnahme im Eigentum des Dienstleisters bleiben, ist seltener, kommt jedoch vor. Wichtig sind immer klare Regelungen und die notwendigen Fertigkeiten des Vor-Ort-Personals für den Zugriff bei Bedarf, wenn eine Störung an kritischer IT-Ausstattung anfällt. Ohne Nachteile sind solche Lösungen nicht, dies ist abzuwägen: Tests müssen ad-hoc abgebrochen werden können und dürfen. Lagerung von Vor-Ort-Reservekomponenten belegt Raum, der anderweitig genutzt werden könnte.
Bei kritischer IT zahlen sich derartige Überlegungen zu Bedarf und Optionen für risikomindernde Vorkehrungen auf erhöhtem Niveau letztlich aus – sonst hätte man sie nicht als „kritisch“ eingestuft. An welchen Stellen man tatsächlich stärker in die Risikominderung geht als bei einem durchschnittlichen Basis- und Standard-Schutz, muss man für den eigenen individuellen Fall (Sektor, Art des Kerngeschäfts und der kritischen IT, …) prüfen und entscheiden.
KRITIS-Betreiber können mittlerweile auf verschiedene Hilfen zurückgreifen, um nichts Wesentliches zu übersehen. Von nicht-KRITIS-Umgebungen können solche Dokumente mindestens als Ideenquelle genutzt werden:
- Die „Konkretisierung der Anforderungen an die gemäß § 8a Absatz 1 BSIG umzusetzenden Maßnahmen“ ist für KRITIS-Betreiber Pflichtlektüre.
Das Dokument mit diesem Titel enthält einen Anforderungskatalog mit Relevanz für KRITIS-Betreiber und Prüfer.
- Branchenspezifische Sicherheitsstandards B3S
Diese werden nach einer vom BSI herausgegebenen „Orientierungshilfe“ gestaltet. Sie geben z.B. Erläuterungen zu branchenspezifischen Gefährdungen, Gefährdungen kritischer branchenspezifischer Technik und Software, u.ä. Über dazu passende Anforderungslisten im B3S kann man systematisch die eigene Situation durchleuchten, ohne Wichtiges zu vergessen. Ein B3S kommt von Unternehmen der jeweiligen Branche, hat also Praxiskenntnis und -Erfahrung von Insidern als Hintergrund.
- Erfahrungsberichte aus KRITIS-(Dokumenten-)Prüfungen
Ein Beispiel ist das Dokument „Nachweisprüfungen im Finanz- und Versicherungswesen – Was haben wir gelernt?“, siehe https://www.bsi.bund.de/SharedDocs/Downloads/DE/BSI/KRITIS/Nachweispruefungen_im_Finanz-und_Versicherungswesen.pdf.
Erkenntnisse, insbesondere herausgestellte beobachtete Mängel, die in solchen Dokumenten erläutert sind, liefern Anhaltspunkte für Aspekte, denen besondere Aufmerksamkeit bei einer Selbstprüfung gebührt.
- Sektorstudien
Zu bestimmten der oben genannten Sektoren gibt es im Auftrag des BSI erstellte Studien. Sie informieren unter anderem über praxisrelevante Abhängigkeitsketten und geben Beispiele für tatsächlich erlebte schädliche Vorfälle. An solchen, offenbar nicht unrealistischen Szenarien kann man überprüfen, ob man für vergleichbare Vorkommnisse gut vorbereitet ist oder Verbesserungsbedarf sieht.
- Veröffentlichungen der UP KRITIS
UP KRITIS ist eine öffentlich-private Kooperation zwischen KRITIS-Betreibern, deren Verbänden und den zuständigen staatlichen Stellen. Über beteiligte Branchenverbände kommt wiederum Praxis-Know-how in die entsprechenden Arbeitskreise, und nicht nur aus Sicht des KRITIS-Betriebs.
Es gibt neben Branchen-Arbeitskreisen auch übergreifend besetzte Themenarbeitskreise. Themen sind z.B. Detektion von Cyberangriffen, Sicherheit von Industrial Control Systems (ICS), Nutzung cloudbasierter Dienste, „Szenariobasierte Krisenvorsorge“ über „Krisenblätter“ zum Umgang mit ausgewählten Szenarien, usw.
Arbeitskreise dienen zunächst dem Erfahrungsaustausch der Teilnehmer. Hierauf basierend entstehen ebenso im Namen der UP KRITIS veröffentlichte Arbeitshilfen, z.B. die „Handlungsempfehlung zur Verbesserung der Informationssicherheit an Kliniken“. Ein Einstieg mit Zugang zu UP-KRITIS-Veröffentlichungen ist über https://www.bsi.bund.de/DE/Themen/KRITIS-und-regulierte-Unternehmen/Kritische-Infrastrukturen/UP-KRITIS/up-kritis_node.html möglich.
Derartige Hilfen unterstützen mindestens bei der systematischen Identifikation von Baustellen, an denen man Nachholbedarf hat. Studium und gezieltes Ausschlachten kann schon eine wertvolle Zeitersparnis bringen. Wenn man betrachtet, welche Themen- und Aufgabenfelder abzudecken sind, wenn man Risiken in Zusammenhang mit kritischer Ausstattung umfassend beleuchten und behandeln will, lohnt es sich kaum, statt „Lernen von anderen“ selber mit einem Brainstorming zu beginnen.
KRITIS-Betreiber müssen dem BSI regelmäßig eine Dokumentation über den geeigneten Umgang mit den Anforderungen nach §8a vorlegen. Schaut man sich die Kategorien an, nach denen eine Mängelliste zum Prüfergebnis strukturiert werden soll, hat man einen guten Überblick über Themen- und Aufgabenfelder, mit denen man sich zu kritischer IT befassen sollte:
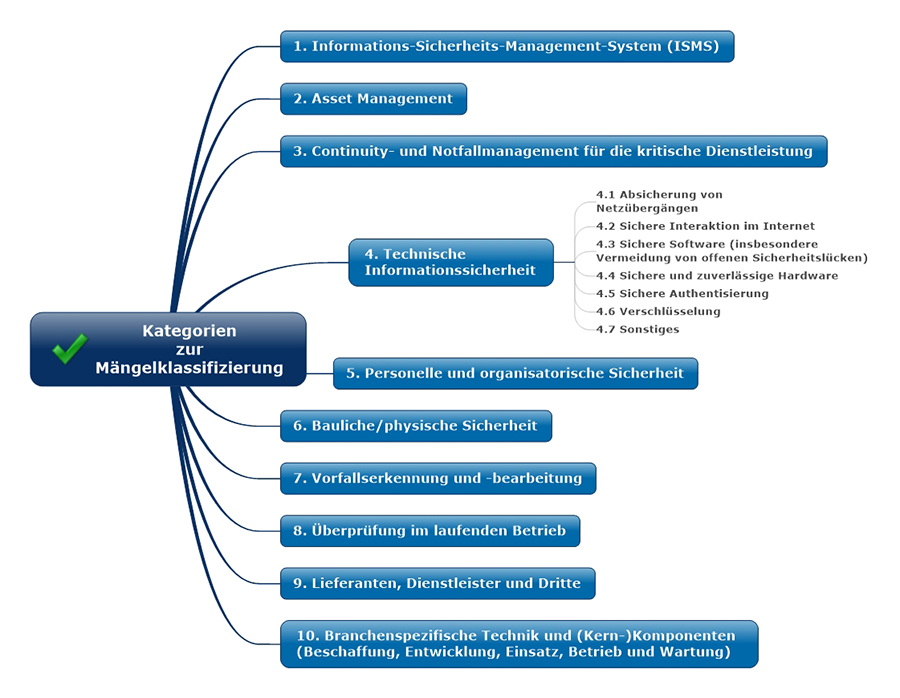
Abbildung 2: BSI-Unterlage „Orientierungshilfe zu Nachweisen gemäß § 8a Absatz 3 BSIG“, Anhang E; zugleich als grobes Raster für eine erste Gap-Analyse nutzbar.
Für konkrete Entscheidungen bzgl. techniknaher Maßnahmen, auf einem für kritische Infrastrukturen und IT angemessenen Niveau, muss man die eigenen Rahmenbedingungen berücksichtigen und auf (Technik-)themenspezifische Hilfen zurückgreifen. Hierzu zählen:
- Technologiespezifische ISO-Standards oder DIN-Dokumente
- Technische Richtlinien des BSI
- BSI-Veröffentlichung zum Themenbereich Cybersicherheit allgemein
- BSI-Cybersicherheitsempfehlungen nach Angriffszielen für Unternehmen allgemein, Netzwerke, Industrielle Steuerungs- & Automatisierungssysteme (ICS), Cloud-Computing, RZ-Sicherheit / Hochverfügbarkeit u.ä., doch auch zum „Faktor Mensch“
Hierunter finden sich z.B. ein HV-Kompendium zum RZ-Bereich und ein Dokument mit Standort-Kriterien für Rechenzentren und ähnliche Unterlagen.
Solche Quellen bieten nützliche Hilfestellung für den Umgang mit Risiken auch auf erhöhtem Schutzniveau. Man kann damit ohne Neuerfindung des Rades die Aufgabe angehen, zu konkreten (Rest-)Risiken Maßnahmen zusammenzustellen und zu realisieren, die dem Schutzbedarf kritischer IT angemessen sind.
Beispiele für wichtige Optimierungspunkte (nicht nur) im Umfeld kritischer IT
Standards und Dokumente wie die zuvor genannten bieten eine nützliche Hilfestellung, wenn man im Umgang damit geübt ist.
Das lässt sich aus dem Beratungsalltag der ComConsult bestätigen, wo regelmäßig auf solche Quellen zurückgegriffen wird. Bei der erfolgreichen Anwendung im Sinne des Kundenbedarfs müssen Risiken allerdings immer umgebungsspezifisch bewertet und entschärft werden.
Bestimmte Entscheidungsfragen treten dabei in unserem Alltag so häufig auf, dass sie hier abschließend überblicksartig vorgestellt werden sollen. Ähnlich zu den typischen Gefährdungen bzw. Mängeln aus den o.a. Dokumenten können sich daraus Anreize ergeben, die in einer konkreten Umgebung für Reviews oder zur kontinuierlichen Verbesserung der Risikobehandlung für die kritische IT genutzt werden können.
- Verfügbarkeitsoptimierung über konsequente Redundanz
Angemessene Redundanz für kritische IT ist mehr als eine Vermeidung von Single-Point-of-Failure-Schwachpunkten. Der Einsatz von Redundanz ist nach dem oben genannten Ende-zu-Ende-Ansatz ausgewogen zu gestalten, wenn das investierte Geld nicht teilweise in ungünstigen Störungsszenarien verpuffen soll.
In der Praxis muss fallweise zwischen automatischer Redundanzverwaltung und manueller Aktivierung entschieden werden. Nicht immer ist die automatische Variante die stabilere und verlässlichere. Erfahrung und Tests sind für Abwägung und Entscheidung notwendig. Bei anderen Produkten kann es zu Problemen kommen, wenn die automatische Redundanzverwaltung aktiv, doch ausfallbedingt nur noch eine Instanz funktionsfähig ist. Ist dies bekannt oder sporadisch in Testreihen vorgekommen, muss das zielsichere Deaktivieren der Redundanz vorbereitet und beherrscht werden.
Im konkreten Fall können durchgängig gleichwertige bzw. für alle relevanten Gefährdungen effektive Redundanz, geeignete Rahmenbedingungen oder Produkteigenschaften fehlen. Dann sollte man gezielt durch Risikostreuung kompensieren, etwa über Mehrfachredundanz. Diese lässt sich so verteilen, dass die verschiedenen Einsatzpunkte nicht demselben Schadensereignis ausgesetzt sein können. Eine in diesem Sinne häufig zu treffende Grundentscheidung benennt der nachfolgende Aufzählungspunkt:
- Redundanz bei Rechenzentrumsstandorten
Der Begriff „Georedundanz“ fällt hier schnell und scheinbar intuitiv. Bei genauerem Hinsehen ist das jedoch ein komplexes Thema, insbesondere bei Beachtung der Begrifflichkeiten und Anforderungen des BSI für Hoch- bzw. Höchstverfügbarkeit.
In bestimmten Fällen setzt eine technisch notwendige Nähe zum Standort der Nutzung von RZ-Leistungen Grenzen. Je nach Kerngeschäft bzw. kritischer Leistung kann die Anforderung maßgeblich sein, bei längeren Störungen der netztechnischen Außenanbindung am Standort zeitweilig „autark“ weiter arbeiten zu können. Ein nächster Gesichtspunkt kann der Bedarf sein, für minimalen Datenverlust zwischen redundanten Lösungen eine sehr hohe Synchronität veränderlicher Daten und Zustände zu realisieren. In solchen Fällen scheiden allzu große Abstände zwischen den zueinander redundanten RZ-Standorten mit solchen Synchronisierungsvorgängen aus Laufzeitgründen aus. Je nach Verfügbarkeitsbedarf müssen im Sinne der Verhältnismäßigkeit Kompromisse eingegangen oder im Gegenteil aufwändige Kombinationen über Mehrfachredundanz bzgl. RZ-Lokationen realisiert werden.
Wer hier weitere Gesichtspunkte betrachten will, kann etwa die ComConsult-Publikationen unter https://www.comconsult.com/bsi-betriebsredundanz-georedundanz/ und https://www.comconsult.com/warum-sich-rz-verantwortliche-fuer-betriebsredundanz-entscheiden/ sichten.
- Angemessene Redundanz ebenfalls beim Personal für kritische IT
Nach dem konkreten Fall der Corona-Omikron-Variante muss man zu diesem Aspekt den Vorwurf „theoretische, unrealistische Unkerei“ nicht mehr ausräumen. Das Szenario eines hohen Krankenstands mit strengen Quarantäneauflagen braucht man dabei gar nicht bemühen, es geht auch etliche Nummern kleiner und damit noch wahrscheinlicher:
Der „Single-Point-of-Failure“ im Bereich notwendigen IT-Know-hows ist das Kopfmonopol – nur eine einzige Person hat de facto notwendige Kenntnisse zum Umgang mit bestimmten IT-Lösungen. Im IT-Alltag kommen bei vermeintlich minder wichtigen Themen Fälle vor, in denen sogar bzgl. der Durchführung einfacher Standardarbeiten nur eine Person handlungsfähig ist.
Die in der Praxis viel zu häufig anzutreffende Konstellation einer „Alibi-Vertretung“ ist nicht viel besser. Diese kann einfache Fälle bearbeiten oder zumindest Vorarbeit leisten wie z.B. Fallerfassung, Antragsprüfung, notwendige Bestellungen einleiten usw. Damit hält man sich für die Dauer einer geplanten Abwesenheit des eigentlichen Know-how-Trägers zum Thema über Wasser, etwa während dessen Urlaubs. Kann das für kritische IT funktionieren? Ganz sicher nicht!
Hier klärt eine einfache Fehler-im-Fehler-Betrachtung den dringenden Verbesserungsbedarf: Während der Abwesenheit des Haupt-Wissensträgers kommt es zu einer nicht-trivialen Störung der kritischen IT. Die vermeintliche Vertretung wird hier zum Pappkameraden, bestenfalls noch zum Durchlauferhitzer, der einen Support-Vertrag bemüht und dann nur noch hoffen kann, der Externe werde es richten.
Selbst zwei einigermaßen gleichwertige Wissensträger können bei wirklich kritischer IT im Sinne des Fehler-im-Fehler-Gedankens ein Problem darstellen, mit dem man sich zumindest beschäftigen muss. Szenario: Wissensträger 1 ist in Urlaub, Wissensträger 2 wird plötzlich krank – und dann tritt der Störfall ein.
Vergleichbar schwierig, wenn auch unter anderen Vorzeichen, ist eine zu starke Zuständigkeitshäufung in Personalunion bei wenigen IT-Spezialisten. Szenario: Es gibt zwei Personen mit guter Wissensredundanz, eine davon ist in Urlaub oder krank – und es treten gleichzeitig massive Störungen bei zwei verschiedenen Lösungen im Bereich kritischer IT auf.
In solche Konstellationen kann man mit wachsender Komplexität des IT-Bestands, etwa durch zunehmende Digitalisierung, schleichend hineingeraten. So leicht nachvollziehbar die Problematik der Beispielszenarien ist, so kompliziert kann die Gestaltung einer geeigneten Lösung sein.
Zusätzliches IT-Personal mit grundsätzlich passender Eignung, im Idealfall gar mit ersten Vorkenntnissen zu konkret eingesetzten Produkten, muss erst einmal gefunden und dann in die konkrete Umgebung eingeführt werden. Aufbau und Pflege einer gleichwertigen Verteilung von Know-how und operativer Handlungssicherheit ist keine einfache Aufgabe. Dies funktioniert da gut, wo Kombinationen aus gezielten organisatorischen Ansätzen und einer guten Betriebsdokumentation etabliert worden sind: Wo Erfahrung und Training durch regelmäßige Wahrnehmung operativer Aufgaben in Zusammenhang mit der IT (noch) ungleichmäßig vorliegen, muss die für eine fachkundige Person leicht verständliche Dokumentation den Ausgleich leisten. Eine derartige Dokumentation ist in der Praxis ein schwieriges Thema, weil sie ungeliebt ist und in Phasen hoher Arbeitslast schnell vernachlässigt wird. Entsprechende negative Entwicklungen muss man frühzeitig erkennen und dann gezielt gegensteuern – eine weitere Aufgabe der Betriebsorganisation mindestens mit Blick auf kritische IT.
- Kommunikationsfähigkeit in Ausnahmesituationen
Kommunikationsfähigkeit in Ausnahmesituationen trägt wesentlich zur Schadensbegrenzung bei.
Die Möglichkeit zur Externkommunikation ist bisweilen zwingend erforderlich, um Meldepflichten nachkommen zu können. In jedem Fall wird man über bewusste Außendarstellung der Lage die Deutungshoheit bezüglich der eigenen Situation behalten wollen. Nur so lässt sich Gerüchten und Spekulationen entgegenwirken, die sonst ungehindert schädliche Nachwirkungen haben können. Für notwendige Schritte zur Bewältigung der Lage muss man gegebenenfalls mit Dritten zusammenarbeiten können (externer Support, Feuerwehr, Behörden, Banken zur Liquiditätssicherung).
Mindestens genauso wichtig ist die Möglichkeit der internen Kommunikation für effizienten und effektiven Umgang mit der Ausnahmesituation. Initiale Unterstützung muss fallweise organisiert werden. Die Selbstorganisation für Wiederanlauf und Wiederherstellung der betroffenen Technik ist auf Absprachen zur Maßnahmenwahl und auf Koordination der Durchführung angewiesen. Dies gilt in erhöhtem Maße, wenn Notbetriebsformen einzuleiten und die betroffenen Nutzerkreise dafür zu informieren und einzuweisen sind.
Hier gilt es ebenso, herausgestellte Denkansätze wie Fehler-im-Fehler und Redundanz mit überlegter Risikostreuung gezielt zu verfolgen:
Ist man vollständig auf extern betriebene Kommunikationslösungen angewiesen, kann ein Störungsszenario deren Nutzung leicht behindern, inklusive gewohnter Ausweichoptionen: Laufen VoIP-basierte Telefonie und die Nutzung von Diensten wie Teams, Zoom etc. über dieselbe Internetanbindung, können diese je nach Störungsbild gleichzeitig ausfallen.
Der Griff zum Mobiltelefon liegt als weitere Ausweichmöglichkeit natürlich nahe. Dumm nur, wenn das auslösende Schadensereignis die ganze Nachbarschaft betrifft und diese vorzugsweise denselben Mobilfunkbetreiber nutzt wie man selbst. Eine Überlastung bzw. ein Denial-of-Service-Zustand ist hier möglich. Dies kann insbesondere auch die interne Kommunikation zum Umgang mit der Ausnahmesituation betreffen, soweit man hierfür auf mobile Endgeräte setzt bzw. sogar angewiesen ist.
Bei der Entschärfung dieser Art von Fehler-im-Fehler-Szenarien durch Risikostreuung muss man kreativ sein, dennoch Kosten und Verhältnismäßigkeit im Auge behalten – und bei der Umsetzung aufmerksam sein! Gerade bei einer Ausstattung, die hauptsächlich für Nutzung im Ausnahmefall gedacht ist, kommt es in der Praxis leicht zu leidigen Pannen: Mit der Einwahl bei einem alternativen Drahtlosprovider muss man auf seinem Endgerät umgehen können. Eigens für „Notfallkoordination“ ausgegebene Mobiltelefone oder Funkgeräte nützen wenig, wenn man sie mit halb leerem oder gar tiefentladenem Akku vorfindet. Gleiches gilt für Ersatzakkus oder zum Nachladen gedachte Powerbanks. Zudem muss eine solche Bevorratung nötigenfalls bei Wachstum von Institution und Belegschaft mitwachsen.
Fazit und Einschätzung
Abbildung 3: Aspekte der strukturierten Risikobewertung
Umfangreiche Denkweisen und eine gründliche, umfassende Betrachtung realistischer Gefährdungsszenarien und Schadensfolgen sind gefordert, um mit Risiken rund um kritische IT angemessen umgehen zu können. Eine entsprechende Risikoreduzierung gelingt in der Regel nur mit einem abgestimmten Bündel an Maßnahmen. Um die damit verbundenen besonderen Aufwände und Kosten verhältnismäßig zu gestalten, ist eine individuelle und dennoch strukturierte Risikobewertung notwendig.
Eine regelmäßige Überprüfung der getroffenen Einschätzungen und Entscheidungen, die auf neuen Erkenntnissen aus konkreten Schadensereignissen und Änderungen im Bereich Technologien und Marktangebot (Produkte und Services) aufbauen, ist notwendig.
KRITIS-Betreiber sind hier besonders gefordert und in der Pflicht. Geschickt ausgewählte Unterlagen können ihnen wertvolle Ideen- und Systematikhilfe für beliebige Umgebungen und deren kritische IT bieten. In jedem Fall gilt: Wer bei Ideensammlung und Lösungsfindung erfahrene Technikbetreiber und mit kritischer IT arbeitende Nutzergruppen gezielt einbezieht, macht es richtig. Die einen bringen notwendige Kenntnisse zu technischen Abhängigkeiten und Machbarkeit ein. Die anderen sind diejenigen, die am besten beantworten können, welche möglichen Workarounds und Ausweichmöglichkeiten gut und wie lange nützen.
Wer diese Herausforderungen nicht oder nur halbherzig annimmt, kombiniert zunehmende Digitalisierung mit „Prinzip Hoffnung“ – eine gefährliche Mischung mit Zeitbombenqualität.

Unified Communications – von Grundlagen über Planung bis Umsetzung
09.07.-11.07.2025 in Bad Neuenahr | online

Kontakt
ComConsult GmbH
Pascalstraße 27
DE-52076 Aachen
Telefon: 02408/951-0
Fax: 02408/951-200
E-Mail: info@comconsult.com