
Künstliche Intelligenz im Netzwerk – wo geht die Entwicklung in den nächsten Jahren hin?
01.02.2023 / Dr. Johannes Dams

aus dem Netzwerk Insider Februar 2023
Immer mal wieder ist künstliche Intelligenz (KI) als Thema in aller Munde. Dies gilt natürlich ebenso für die Netzwerkhersteller. Tatsächlich haben auch wir bei ComConsult in der Vergangenheit KI in Vorträgen und Artikeln regelmäßig beschrieben [1]. Zuletzt haben meine Kollegen Nils Wantia und Mohammed Zoghian das Thema in einem Blog-Beitrag mit dem Titel „KI-Esoterik“ [2] bzw. einem Beitrag mit dem Inhalt „KI für die Digitale Transformation“ [3] behandelt.
Über die dort gemachten Überlegungen hinaus ist es natürlich spannend, sich mit der aktuellen Entwicklung im Bereich der KI zu befassen und auch damit, welche Rolle diese in Bezug auf die Netzwerktechnik spielen kann. Im vorliegenden Artikel wollen wir hierzu einen kurzen Impuls geben, ohne die technischen Tiefen aufzugreifen. Insbesondere wird ein Beispiel, welches nicht aus dem Infrastrukturbereich stammt, erläutert und betrachtet, wie die durchaus beeindruckende Entwicklung dort in Zukunft auch im Netzwerkumfeld stattfinden könnte.
KI und die Nutzung im Netzwerk- und Infrastrukturbetrieb
In den vergangenen Jahren werben immer mehr Hersteller mit moderner Netzwerkinfrastruktur und in Zusammenhang mit dem Netzwerkbetrieb auch mit modernen Features der Netzwerkkomponenten und des Managements. Der Begriff „Künstliche Intelligenz“ (KI) oder „Artificial Intelligence“ (AI) wird dabei immer wieder als werbewirksames Stichwort verwendet. Natürlich ist zu erwarten, dass sich diese Entwicklung in Zukunft fortsetzt und dass KI immer relevanter für den Netzwerkbetrieb wird.
Auffällig ist jedoch, dass sich die Geister bereits bei der Frage scheiden, wo KI anfängt und was KI ist. So wird häufig insbesondere der Grad der Autonomie als Merkmal herangezogen. Ähnlich wie bei Diskussionen über selbstfahrende Autos kann man nach dem Grad der Selbstständigkeit unterscheiden, mit dem das System am Ende sogar Entscheidungen trifft. Lässt man technische Definitionen außer Acht, verstehen viele unter KI eine gewisse Autonomie. Dies grenzt dabei häufig an eine philosophische Diskussion. Es ist sicherlich ein Unterschied, ob mir ein System z. B. mithilfe einer Mustererkennung vorschlägt, eine Konfiguration anzupassen oder ein verdächtiges Endgerät genauer zu prüfen oder ob es ohne Zutun des Betreibers das Netzwerk anpasst und Sicherheitsregeln in einer Firewall ändert. Aus algorithmischer Perspektive können diese Systeme trotzdem auf denselben Konzepten basieren.
Unabhängig von dieser Abstufung ist klar, dass eine KI immer ein selbstlernendes oder angelerntes System beschreibt. Das bedeutet, dass die KI im Gegensatz zu klassischen Algorithmen ihr Verhalten nur in groben Maßen vom Programmierer vorgegeben bekommen hat und auf Basis von „Beispiel“-Daten ihr eigentliches Entscheidungsverhalten erlernt. Dieses basiert dann üblicherweise auf Wahrscheinlichkeitsberechnungen, deren Verteilung auf Basis der „Erfahrungen“ des Systems angepasst werden. Aufgrund dieses Lernens anhand der gegebenen Daten spricht man häufig auch von maschinellem Lernen oder Machine Learning (ML). Für die Entscheidungsfindung wird ein Zufallsprozess genutzt. Die Güte der Ergebnisse ist damit auch in gewissem Maße zufällig und kann somit sehr unterschiedlich ausfallen.
Da ein solches System gute Ergebnisse oder Entscheidungen nur liefern kann, wenn es entsprechend trainiert wurde, ist die Menge und Qualität des gelieferten Lern-Inputs besonders wichtig. Dies macht KI im Netzwerkmanagement vor allem dann sinnvoll, wenn auch diese Datenmengen verfügbar sind. Wir werden später sehen, dass das ein Grund für die Nutzung in Cloud-Managementsystemen sein kann.
Ein zentrales Problem ist grundsätzlich, dass der genaue Weg zur Entscheidung nur schwer oder meist überhaupt nicht detailliert nachvollzogen werden kann. Da es sich hierbei immer um einen probabilistischen Prozess handelt, kann der Nutzer oder Verwalter am Ende nur sehr begrenzt abschätzen, warum das System eine Entscheidung getroffen hat. Im Endeffekt bedeutet dies vor allem auch, dass der Einsatz von KI und die Eingriffsmöglichkeit der KI deutlich vom Anwendungsfall abhängen.
Sehr konkret kann man feststellen: Einen Eingriff in betriebskritische Systeme muss und möchte man als Betreiber aus Gründen der Betriebssicherheit verstehen können. So muss ich z. B. an einer Netzwerkkonfiguration spätestens bei einer Fehlersuche verstehen, warum die Konfiguration geändert wurde. Wenn es sich allerdings nur um Anpassungen oder Optimierungen handelt, die den Betrieb nicht grundsätzlich infrage stellen können oder die nicht kritisch sind, ist der Einsatz von intelligenten Algorithmen vielleicht einfacher umsetzbar.
Dies erklärt, warum wir erste Entwicklungen hin zu KI-basierten Algorithmen in weniger kritischen Bereichen sehen. Ein nicht produktionskritisches WLAN (z. B. im Besucherbereich) kann ich beispielsweise sorgenfreier automatisch konfigurieren lassen als mein Rechenzentrumsnetz.
Aus praktischer Sicht ist KI durchaus schon im Bereich der IT als Lösung angekommen. Insbesondere für sehr einfache Systeme ist es schon seit langer Zeit üblich, dass vergleichbare Systeme, z. B. als Bayesian-classifier, bei der Spam-Mail-Klassifizierung entscheiden, welche E-Mails als Spam gewertet werden. Im Bereich der Infrastrukturtechnik gibt es jedoch bisher noch wenige Beispiele sowie auch dort, wo die Intelligenz tatsächlich dazu führt, dass automatisierte Entscheidungen getroffen werden.
Ein typisches Beispiel, in dem KI nicht nur auf unkritische Entscheidungen beschränkt ist, kommt aus dem Security-Bereich. Neue Gefahren zu erkennen, bevor diese in Signaturen zur Viruserkennung eingepflegt werden können, stellt hierbei die Herausforderung dar. Vor allem geht es dabei häufig um eine Klassifizierung oder Erkennung, um dann eine genauere Untersuchung zu ermöglichen. Lesen Sie in diesem Zusammenhang auch den Beitrag von Mohammed Zoghian vom 16.08.2022 [4]. Dazu vergleichbar ist die Eingruppierung möglicherweise kompromittierter Endgeräte in eine Quarantäne. Hier überwiegt der Sicherheitsgewinn das Risiko einer automatischen und eventuell fehlerhaften Einordnung eines Endgeräts in eine Quarantäne-Gruppe.
Weitere Beispiele finden sich im Bereich der WLAN-Planung und des WLAN-Betriebs.
Bei der WLAN-Planung kennen wir auch jetzt schon Algorithmen aus dem Bereich der KI für die Platzierung von WLAN-Access-Points in Gebäudeplänen. Aus der Praxis wissen wir allerdings, dass derartige Planungen bestimmte Vor-Ort-Eigenschaften einfach nicht berücksichtigen können und somit zwar als Startpunkt, doch noch lange nicht als finales Ergebnis dienen sollten. Im Bereich des WLAN-Betriebs gibt es Algorithmen, die Kanalwahl-Optimierung und Sendeleistungswahl auf Basis von KI umsetzen.
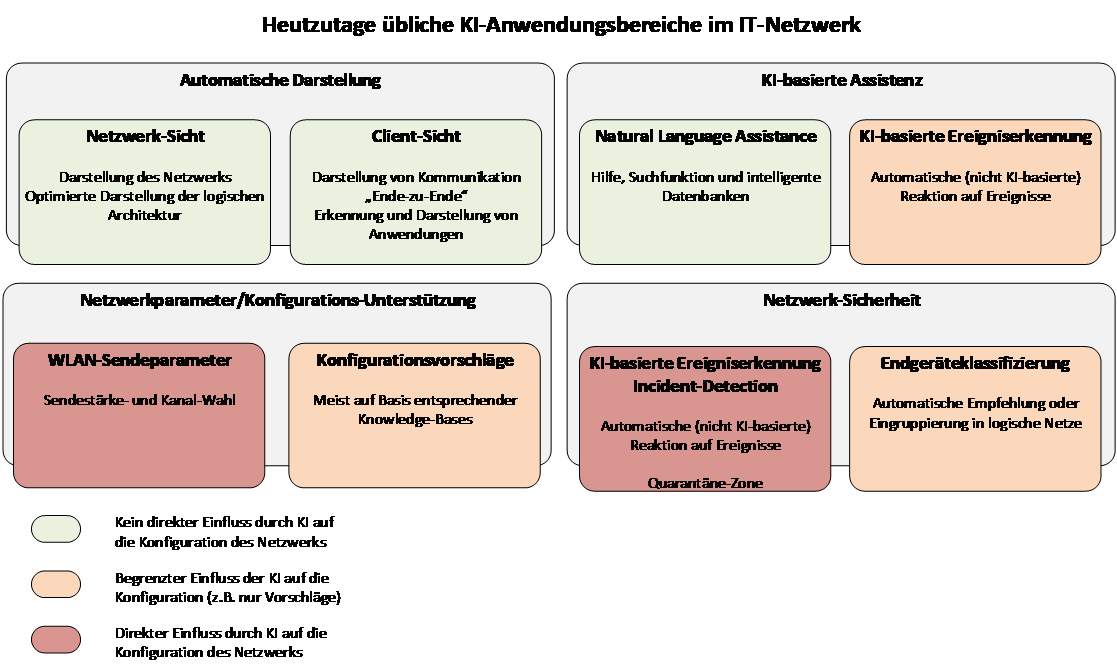
Abbildung 1: Aktuelle Einsatzbereiche der KI im Netzwerkumfeld
Ansonsten findet sich künstliche Intelligenz vor allem im Bereich des Netzwerkmanagements. Neben der Verarbeitung natürlicher Sprache bei Suchanfragen im Management oder in der Knowledge-Base des Herstellers, auf die sich KI bei vielen Produkten bisher beschränkt, handelt es sich hier um Klassifizierungsmethoden und Analysen.
Typische Beispiele für KI im Netzwerkmanagement sind:
- Monitoring und die Überwachung des Netzwerks mit automatischer Erkennung des Zustands des Netzwerks und mit entsprechender Darstellung.
- Unterstützung des Troubleshootings durch entsprechende Fehlererkennung und automatische Analyse von Log-Dateien etc. Dies kann sogar bis zu einer selbstständigen Information des Hersteller-Supports gehen.
- Sowohl Fehlerzustände als auch Sicherheitsprobleme können im Sinne einer Incident Detection oder Anomalie-Erkennung erfasst werden.
- Endgeräte-Erkennung/-Überwachung zur Erkennung neuer Endgeräte und zur Vereinfachung des Onboardings ins Netz.
- Bestimmung des optimalen WLAN-Access-Points im Rahmen des WLAN-Client-Steering.
Erste grobe Eindrücke hinsichtlich des aktuellen KI-Einsatzes finden sich auf entsprechenden Seiten der Hersteller [11, 12, 13, 14]. Eine grobe Eingruppierung findet sich in Abbildung 1.
Es ist zu bemerken, dass viele dieser Dienste dem Entscheider vor allem entsprechende Informationen liefern sollen und gar nicht das Ziel verfolgen, selbstständig eine Änderung im Netzwerk durchzuführen. Es geht also bei den meisten bisher im Netzwerkbetrieb genutzten KI-Funktionen um eine Unterstützung des Betreibers.
Tatsächliche automatische Entscheidungen auf Basis intelligenter Algorithmen umfassen eher nicht-betriebskritische Bereiche. Bis auf wenige Ausnahmen greifen KI-Lösungen heute nicht direkt in das Netzwerk ein.
Hinsichtlich der weiteren Netzinfrastruktur finden sich solche selbstlernenden Automatismen vor allem in Bereichen, wo die automatisch vorgenommene Anpassung keinen tiefen, gegebenenfalls betriebsgefährdenden Effekt haben kann bzw. wo dieser stark eingeschränkt ist. Dies gilt beispielsweise in bestimmten Grenzen für WLAN-Kanäle und Sendestärken. Hier können Optimierungen vorgeschlagen und umgesetzt werden, solange die Anpassungen nicht zu extrem sind.
Im Bereich der Netzwerktechnologien ist der Einsatz von KI aktuell also noch beschränkt. In anderen Bereichen, in denen KI angewendet wird und die weniger mit unserem täglichen Netzumfeld zu tun haben, kann man vielleicht erahnen, wo die Entwicklung in den kommenden Jahren hingeht und was wir für den Netzbetrieb in Zukunft erwarten können.
Entwicklung in anderen Bereichen der KI
Ebenso zeigt sich in anderen Bereichen, in denen KI angewendet wird, dass viele Anwendungen eher der Erkennung als der Entscheidung dienen. Dennoch lässt sich hier eine Entwicklung beobachten, die in den kommenden Jahren auch im Netzwerkbetrieb zu finden sein könnte.
Natürlich erscheint die für viele erlebbare Entwicklung im Bereich des autonomen Fahrens als Beispiel am offensichtlichsten, denn auch hier kommen wir von einer Erkennung und Warnung (z. B. bei Verlassen der Fahrspur) und erreichen mittlerweile eine relativ große Automatisierung des Fahrens. Trotzdem ist dieses Beispiel vielleicht nicht das beste Musterbeispiel für KI, da für diese Aufgaben auch klassische Algorithmen angewendet werden könnten. Bestimmte Aspekte, wie beispielsweise Kreativität, die wir als „Intelligenz“ wahrnehmen, spielen dort eine geringe Rolle.
In anderen Bereichen ist die Entwicklung der KI bereits weiter in eine andere Richtung vorangeschritten. Insbesondere dort, wo keine größeren negativen Folgen und Auswirkungen zu erwarten sind, finden auch neuere Verfahren Anwendung, welche eventuell erst in einigen Jahren auf unsere Netzinfrastruktur zukommen. Daher wollen wir uns ein Beispiel mal etwas genauer anschauen.
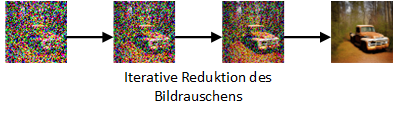
Abbildung 2: Schematische Darstellung der Rausch-Entfernung
Zu nennen wäre an dieser Stelle die automatische Bilderstellung anhand entsprechender Text-Vorgaben, genannt Prompts (Text-to-Image). Hier wurde in den letzten Monaten und Jahren aufgrund der sehr eindrucksvollen Entwicklung viel diskutiert. Auch wenn wir uns auf dieses Beispiel konzentrieren, soll nicht verschwiegen werden, dass es ebenso andere KI-Anwendungen gibt, die in den letzten Wochen einige Aufmerksamkeit bekommen haben. Hierzu gehört u.a. die Texterstellung mithilfe von ChatGPT [16].
Konkret tauchte das Thema Bilderstellung und Kreativität in den Medien vermehrt auf, seit mit der Lösung Stable Diffusion [5, 6, 7] ein erstes Open-Source-Modell mit entsprechend fortschrittlicher Technologie zur Verfügung steht, welches sogar auf üblicher Gaming-Hardware zu Hause funktioniert und somit für jedermann zugänglich ist. Für eine genauere technische Beschreibung sei hier auf verschiedene Stellen im Internet verwiesen [8, 9, 10].
Der Durchbruch der letzten Jahre im Bereich der Lern-Algorithmen wurde vor allem durch GANs (Generative Adversarial Networks) als neuronales Netz vorangetrieben. Die Idee dabei ist, im Bereich des maschinellen Lernens zwei neuronale Netze gegeneinander antreten zu lassen. Am konkreten Beispiel würde ein Netzwerk ein Bild erzeugen und ein anderes muss feststellen, ob dieses Bild aus dem ursprünglichen Datensatz von Beispielbildern aus der realen Welt oder vom „gegnerischen Algorithmus“ stammt. Der eine Algorithmus soll also darauf trainiert werden, den anderen auszutricksen, während dieser darauf trainiert wird, dies zu erkennen. Beide Algorithmen lernen Stück für Stück ihre Aufgabe und werden entsprechend besser. Es werden eine große Zahl von Eingabe-Daten und sehr viele Lern-Durchgänge benötigt. Im konkreten Fall von Stable Diffusion kann zwar das spätere Ergebnis auf herkömmlicher Hardware genutzt werden, jedoch ist die Erstellung des Modells im ersten Schritt nicht so einfach und benötigt eine hohe Rechenleistung.
Mit Stable Diffusion lassen sich auf Basis einer einfachen Textbeschreibung Bilder erzeugen. Angelernt bzw. trainiert wurde das Modell mithilfe einer Datenbank von ungefähr 600 Millionen Bildern der Größe 512×512 Pixel (in einer neueren Version auch 768×768 Pixel) und entsprechender englischer Textbeschreibung.

Abbildung 3: Bild mit Dopplung aufgrund abweichendem Seitenverhältnis (Prompt: “photo of an old man with cowboy hat, nikon 40D”)
Stable Diffusion ist darauf trainiert, zufälliges Bildrauschen aus Bildern zu entfernen. Dies geschieht Stück für Stück, sodass am Ende hoffentlich ein rauschfreies Bild entsteht. Nimmt man also an, man hat ein Bild (z. B. das Foto eines Autos), ergänzt dazu zufälliges Rauschen und trainiert nun den Algorithmus darauf, das Rauschen zu entfernen, so erhält man am Ende hoffentlich wieder das Bild des Autos. Auf Basis dieser Idee wurde das Modell trainiert.
Nimmt man nun ein Bild, welches ausschließlich aus Rauschen besteht und sagt dem Algorithmus, er solle das Rauschen in diesem Bild eines angeblichen Autos entfernen, so entsteht hoffentlich nun ein neues Bild eines Autos. Wie genau das entstehende Auto dann aussieht, hängt vor allem vom zugrunde liegenden Rauschen ab. Mit unterschiedlichen Zufallswerten, die das Rauschen erzeugen, können dann unterschiedliche Auto-Fotos erstellt werden (siehe Abbildung 2).
Die Kombination aus GAN-basiertem Lernen und der beschriebenen Idee, Rauschen hinzuzufügen und zu entfernen, wird als Latent Diffusion Model (LDM) bezeichnet. Natürlich ist das gesamte Verfahren etwas komplizierter als hier beschrieben. Im Endeffekt lassen sich so jedoch zu den verschiedenen gelernten Textbeschreibungen und beliebigen Teilen und Kombinationen Bilder erzeugen.
Daraus resultiert auch eine Eigenheit, die grundsätzlich für derartige Machine-Learning-Verfahren gilt: Die spätere Anwendung funktioniert am besten, wenn die gleichen Rahmenbedingungen gelten, die zur Erzeugung des Datensatzes angenommen wurden. Dies bedeutet konkret: Für andere Auflösungen als 512×512 Pixel entstehen eventuell seltsame, auffällige Artefakte im Bild, da der Algorithmus nicht darauf trainiert ist, diese zu erzeugen. Ebenso funktioniert natürlich die englische Sprache zur Beschreibung am besten, da diese dem Lernen zugrunde lag.
In Abbildung 3 ist zu erkennen, dass teilweise Artefakte entstehen, wenn die ursprünglichen Anwendungsparameter (hier Auflösung und Seitenverhältnis) nicht beibehalten werden.
Bei Stable Diffusion sieht man ein weiteres Problem, welches entsteht, wenn man ungewollt einen sogenannten „Bias“ oder eine Voreingenommenheit beim Lernen erzeugt. Bei bestimmten Stichworten kann es dazu kommen, dass die späteren Ergebnisse sehr nah am ursprünglich Gelernten liegen. Bestimmte Bildelemente tauchen vermehrt auf, auch wenn diese nicht Teil der Beschreibung sind. Das ergibt sich besonders dann, wenn fast gleiche Bilder zu fast gleichen Beschreibungen angelernt wurden, wie in Abbildung 4 erkennbar. Dort sieht man, dass für Handy-Hüllen häufig gleichartige Werbebilder genutzt werden und Teil der Eingabedaten waren und damit auch erzeugte Bilder mit erhöhter Wahrscheinlichkeit dem ursprünglichen Lern-Input ähneln.

Abbildung 4: Vier unterschiedliche Bilder zum Prompt „smartphone case“ als Beispiel für Overfitting/Bias mit zwei nahezu gleichen Ergebnissen
Positive Beispiele (Abbildung 5 und Abbildung 6) zeigen jedoch, wie flexibel Text-to-Image eingesetzt werden kann. Faszinierend ist hierbei, wie detailliert die Bilder mittlerweile werden können, wie unterschiedlich das Ergebnis hinsichtlich des Stils etc. aussehen kann und, zu guter Letzt, dass dies inzwischen auf normaler Gaming-Hardware umsetzbar ist.
Bei Stable Diffusion gibt es teilweise durch die Community entwickelte weitere Funktionen, wie die Nutzung eines bestehenden Bildes, in dem Rauschen hinzugefügt und dann wieder entfernt wird, um z.B. bestimmte Teile oder Merkmale des Bildes zu ändern oder den Stil eines anderen Künstlers nachzuahmen.
Tatsächlich lassen sich die verwendeten Technologien mit etwas Kreativität für künstlerische Ideen nutzen. Es können auch bestehende Kunstwerke als Grundlage genutzt werden, um daraus neue Werke zu generieren.
Der vorzugebende Text-Prompt ist der zentrale Punkt, wie Einfluss auf die Qualität der Ergebnisse ausgeübt werden kann. Es ist daher ein entsprechendes Know-how nötig, um gute Ergebnisse zu erreichen. So macht es einen deutlichen Unterschied, wenn hier zum Prompt „A highly detailed matte painting of cottage in a forest in winter” (Abbildung 7) die Details „in style of van gogh, vivid colors, god rays, intricate lighting“ (Abbildung 8) hinzugefügt werden. Der Stil der erzeugten Bilder unterscheidet sich dann deutlich.
In der Praxis probiert man häufig eine zweistellige Zahl an zufälligen Ergebnissen aus, bevor ein gutes Bild dabei ist. Die genaue Wahl des Prompts macht dabei einen deutlichen Unterschied und erfordert etwas Übung und Know-how. Es reicht nicht, den Algorithmus einfach arbeiten zu lassen und sich darauf zu verlassen, dass die Ausgabe das gewünschte Ergebnis darstellt.

Abbildung 5: Beispiel-Bild (Prompt: “teddy bear wearing a suit and wearing a bowler hat”)
An diesen Beispielen sehen wir einige grundlegende Eigenheiten, welche die meisten KI-basierten Algorithmen aufweisen und welche daher auch im Bereich der KI im Netzinfrastrukturbereich auftreten können:
- Abweichungen von Eigenschaften der Lern-Umgebung führen zu ungewollten Ergebnissen.
Zum Beispiel erzeugt ein für quadratische Bilder trainierter Algorithmus eventuell Dopplungen und andere Artefakte bei abweichenden Seitenverhältnissen. - Overfitting/Bias
Zu viele gleichartige Bilder im Lern-Datenset sorgen für gewisse Voreingenommenheit hinsichtlich des Ergebnisses. Dies sieht man beispielsweise daran, dass Stable Diffusion bei „Smartphone cases“ häufig sehr ähnliche Bilder erzeugt. - Für das Trainieren eines KI- oder ML-Algorithmus sind große Datenmengen vonnöten, um zielführende Ergebnisse zu erreichen.
- Häufig wird angemerkt, dass die Berechnung auf besonders leistungsfähiger Hardware erfolgen muss.
Das gilt insbesondere für das Training. Nutzung der KI-Algorithmen kann immer häufiger auf üblicher Alltags-Hardware erfolgen. - Die Nutzung der KI erfordert Know-how.
Die genaue Ausformulierung der Text-Prompts erzeugt sehr unterschiedliche Bilder. Es bedarf demnach Erfahrung in der Nutzung der konkreten KI, sobald der Anwendungsbereich entsprechend komplex wird.

Abbildung 6: Beispiel-Bild (Prompt: “nerd sitting in the jungle eating donuts and using a laptop pc”)
Die Zukunft der KI im Netzwerk
Welche Rückschlüsse lassen sich nun auf dieser Basis für die KI im Bereich der Netzwerktechnik treffen?
Natürlich ist das oben beschriebene Beispiel der Text-to-Image-KI nicht unbedingt auf Netzwerktechnik anwendbar. Prinzipiell kann man sich jedoch eine “Text-to-Solution“- oder “Text-to-Networkdesign“-Komponente vorstellen. Inwieweit die Entwicklung wirklich in diese Richtung geht, ist allerdings unklar.
Als erstes muss man feststellen, dass Ergebnisse mit derartig großer Fluktuation und so großen Qualitätsunterschieden für viele Anwendungsfälle im Netzwerkbetrieb auf den ersten Blick keinen Nutzen bringen würden. Bei einer automatischen Anpassung von Netzwerkparametern will man sich bestimmt nicht darauf verlassen, dass das zufallsbedingte Ergebnis beliebig schlecht sein kann.
Die oben beschriebenen Latent-Diffusion-Modelle sind natürlich nicht für so technische Problemstellungen wie ein Netzwerkdesign gedacht. Ein zentraler Teil ist hierbei so flexibel und bedarf deutlichen menschlichen Inputs, dass der Nutzen bei technischen Themen vermutlich begrenzt ist. Insbesondere sehen wir auch bei der oben beschriebenen automatischen Bild-Erstellung, dass die Auswahl des besten Ergebnisses noch einiges an menschlichem Verständnis und Vorstellungsvermögen erfordert.

Abbildung 7: Beispiel-Bild (Prompt: “A highly detailed matte painting of cottage in a forest in winter”)
Grundsätzlich kann man sich jedoch durchaus vorstellen, über ähnliche Verfahren Vorschläge für ein Netzdesign oder eine Konfiguration zu erhalten. Angesichts des Aufwands zur Entwicklung sowie des benötigten Know-hows auf der Nutzer-/Betreiber-Seite zur Beschreibung und Auswahl der Lösung ist es aus meiner Sicht allerdings eher unwahrscheinlich, dass dies sehr bald geschehen wird.
Kurzum, es ist aktuell nicht möglich, einfach ein Netzwerkdesign auf Basis einer Textbeschreibung zu erstellen und in den nächsten Jahren wird sich das nicht ändern. Trotzdem werden wir in Zukunft sicherlich häufiger Algorithmen aus dem Bereich des Machine Learning sehen, um den Betrieb des Netzwerks zu erleichtern.
Die fortschreitende Entwicklung und die Tatsache, dass technische Umgebungen im Vergleich zu anderen Szenarien klarer strukturiert und damit einfacher zu überschauen sind, lässt darauf schließen, dass hierbei eine Zunahme hinsichtlich der Qualität der Vorschläge zu erwarten ist.
Auch wenn Stable Diffusion als Beispiel selbst nicht auf Netzwerktechnik angewendet werden kann, zeigt es beeindruckend, wie die Technologie sich hier weiterentwickelt. Vergleichbare Weiterentwicklungen gibt es auch in anderen Bereichen der KI. Beispielsweise werden Erkennungsalgorithmen verlässlicher und besser. Diese Verbesserungen werden wir sicherlich in Zukunft in Bereichen sehen, in denen auch jetzt schon KI eingesetzt wird. Die Klassifizierung von Ereignissen mit Sicherheitsrelevanz oder von Fehlerzuständen wird von diesen Entwicklungen profitieren. Auch wenn wir in solchen Fällen weiterhin den Menschen als zentrale Entscheidungsinstanz sehen, werden Anzeigen, Vorschläge und in eingeschränktem Maße Reaktionen zielgerichteter und besser werden.
Analog zur Umsetzung einer Image-to-Image-Funktion bei Stable Diffusion ist hier durchaus denkbar, dass das bestehende Netzdesign als Teil der Eingabe für Verbesserungsvorschläge dient und so sehr direkte Anpassungsmöglichkeiten erkannt werden.
Man kann natürlich nur abwarten, was sich tatsächlich tut. Dennoch lässt sich kurz zusammenfassen, dass wir erwarten oder hoffen, dass KI in Zukunft auch für konkrete Entscheidungen herangezogen werden kann. Dabei wird jedoch relevant sein, ob diese Entscheidungen weiterhin nachvollziehbar, nachprüfbar und korrigierbar sind. Dies ist insbesondere im Hinblick auf das grundlegende Betriebsrisiko zu betonen.

Abbildung 8: Beispiel-Bild (Prompt: “A highly detailed matte painting of cottage in a forest in winter, in style of van gogh, vivid colors, god rays, intricate lighting”)
Bei den folgenden Aspekten könnte KI in naher Zukunft eine wichtigere Rolle spielen:
Netzwerkmanagement:
- Erkennung von Fehlerzuständen im Netzwerk (Ressourcenengpässe, WLAN-Störungen etc.)
- Darstellung des aktuellen Netzwerks und des Zustands der Komponenten
- Erzeugung von Alarmen unabhängig von fest vorgegebenen Schwellwerten
- Proaktive Anpassungsvorschläge für das Netzdesign
IT-Security:
- Erkennung von Sicherheitsvorfällen
- Anomalie-Erkennung
- Automatische Quarantäne bei unerwartetem Verhalten von Endgeräten
Netzdesign:
- Vorschlag von Konfigurationsanpassungen anhand der konkret beobachteten Nutzung des Netzwerks
- Automatische Optimierung von WLAN-Konfigurationsparametern (Sendestärken und Kanalwahl)
- Optimierte KI-gestützte Routingentscheidung im Sinne eines SD-WAN
Es ist davon auszugehen, dass KI irgendwann über die reine Anomalie-Erkennung und direkt darauf basierender Reaktionen hinausgeht. Ein Netzwerk lässt sich vielleicht noch nicht mustergültig planen und konfigurieren. Bestimmte automatische Anpassungen werden in Zukunft jedoch möglich sein.
Als Beispiel, wo sich diese Entwicklung bereits andeutet, ist der Bereich des WLANs zu nennen. Hier werden wir solche Entwicklungen sehen, da diese in der Vergangenheit auch im 5G-Mobilfunk zu erkennen waren. In den letzten WLAN-Standards diente der Mobilfunkstandard immer wieder als Vorlage. Dort finden sich im Release 18 KI/ML-Algorithmen beispielsweise in der Planung zum physikalischen Layer [15].
Die praktische Anwendung wird auch im Netzwerkumfeld von der benötigten Datenmenge abhängen, die für das Anlernen benötigt wird. In nicht statischen Themenfeldern ist hierbei auch zu berücksichtigen, dass, abhängig vom verwendeten Algorithmus, fortlaufend gelernt wird, um auf sich ändernde Bedingungen reagieren zu können.
Solch große Datenmengen mit Netzdesign-Varianten, auftretenden Problemfällen, unterschiedlichen Anwendungen, Protokollen und Fehlerzuständen werden bestimmte KI-Nutzungen auf Cloud-Management-Umgebungen beschränken. Hier wird nicht nur der Input eines Netzwerks berücksichtigt, sondern die Zustände zahlreicher Netze von zahlreichen Kunden werden in einem System zusammengeführt. Dies gilt aktuell bereits und ist bisher eine Einschränkung der KI-Nutzung in On-Prem-Managementsystemen. Für Funktionen, die jedoch nicht ständig weiter lernen müssen, kann eine Entwicklung hin zu geringeren Hardwareanforderungen ähnlich zu Stable Diffusion erwartet werden. Natürlich bleibt abzuwarten, für welche der Anwendungsmöglichkeiten die Hersteller dann eine On-Prem-Variante entwickeln. Hier wird es eine Frage des Vertriebsmodells sein, ob Hersteller überhaupt ein Interesse daran haben, dies umzusetzen.
Zu guter Letzt ist vor allem anzumerken, was für den Betrieb jeder Hardware gilt: Der Netzwerkbetrieb sollte ein grundsätzliches Verständnis der genutzten Technologie haben. Konkret bedeutet das, dass der Einsatz von KI es notwendig macht zu verstehen, welche Funktionen verlässliche Ergebnisse liefern, wie zuverlässig eine Anomalie-Erkennung überhaupt sein kann und wie ich die Ergebnisse interpretiere.
Spätestens dann, wenn man irgendwann in Zukunft deutlich spezielle Funktionen mit automatisierten Reaktionen und grundlegenden Design-Entscheidungen haben will, wird entsprechendes Know-how notwendig sein.
Grundsätzlich lassen sich vergleichbare Rahmenbedingungen und Beispiele identifizieren, wie dies beim oben genannten Beispiel Stable Diffusion der Fall ist:
Abweichungen von Eigenschaften der Lern-Umgebung führen zu ungewollten Ergebnissen
- Ein Algorithmus, der auf einer Art von Netzwerkarchitektur trainiert wurde, wird bei abweichenden Anforderungen nicht das passende Ergebnis liefern.
- So könnten neue oder abweichende Kommunikationsprotokolle von Anwendungen als Fehler oder Sicherheitsrisiko fehlinterpretiert werden.
- Als weiteres Beispiel wird auch eine automatische Sendestärken- und Kanal-Wahl keine guten Ergebnisse liefern, wenn diese bei Deckenmontage trainiert wurde und im konkreten Umfeld (ggf. entgegen der Herstellerempfehlung) eine vertikale Wandmontage durchgeführt wurde.
Overfitting/Bias
- Individuelle Rahmenbedingungen werden eventuell nicht berücksichtigt.
- Dies kann zum Beispiel bei einer KI-gestützten Quarantäne-Regelung dazu führen, dass Endgeräte fälschlicherweise gesperrt werden, weil die individuelle Nutzung und verwendete Anwendung nicht in der Lernumgebung auftraten.
Für das Trainieren eines KI- oder ML-Algorithmus sind immer große Datenmengen vonnöten, um zielführende Ergebnisse zu erreichen.
- Daher sehen wir aktuell entsprechende KI-Funktionalität vor allem in Cloud-Managementsystemen. Hier liegen dem Hersteller ausreichende Mengen an Daten zur Verfügung, um an einer Vielzahl von Beispielen die Algorithmen zu trainieren.
Häufig wird angemerkt, dass die Berechnung auf besonders leistungsfähiger Hardware erfolgen muss.
- Dies ist ebenfalls ein Grund für die Bereitstellung dieser Funktionen in der Cloud.
Die Nutzung der KI erfordert Know-how.
- Das ist vermutlich ein häufig unterschätzter Punkt. Auch im Bereich des Netzumfelds müssen KI-basierte Empfehlungen verstanden und korrekt interpretiert werden.
Künstliche Intelligenz wird in Zukunft sicher auch im Bereich des Netzbetriebs und des Netzwerkmanagements immer wichtiger. Natürlich können wir aktuell nicht sagen, wie die Entwicklung genau stattfinden und wo sie hingehen wird und wann wir da neue Funktionen und Anwendungen erleben werden. Die KI zeigt in anderen Bereichen deutliche Fortschritte. Es ist ebenfalls zu erwarten, dass diese Fortschritte in Netzwerkmanagement-Systemen Einzug finden werden. Es bleibt also spannend, was sich hier in naher Zukunft für uns Netzwerker ergibt.
Verweise
[1] Simon Hoff, Fluch und Segen der Künstlichen Intelligenz für die Informationssicherheit, ComConsult Netzwerk Insider, 03.06.2018, https://www.comconsult.com/ki-informationssicherheit/
[2] Nils Wantia, KI-Esoterik, ComConsult Blog, 13.09.2022, https://www.comconsult.com/ki-esoterik/
[3] Mohammed Zoghian, KI für die digitale Transformation, ComConsult Blog, 09.08.2022, https://www.comconsult.com/ki-fuer-die-digitale-transformation/
[4] Mohammed Zoghian, KI-Anwendungsfälle für die Cybersicherheit, ComConsult Blog, 16.08.2022, https://www.comconsult.com/ki-anwendungsfaelle-in-der-cybersicherheit/
[5] stability.ai, https://stability.ai
[6] Stable-Diffusion Demo, https://stablediffusionweb.com
[7] Stable-Diffusion Hugging face space, https://huggingface.co/spaces/stabilityai/stable-diffusion
[8] Computerphile Youtube-Kanal, How AI Image Generators Work (Stable Diffusion / Dall-E) – Computerphile, 04.10.2022, https://www.youtube.com/watch?v=1CIpzeNxIhU
[9] Computerphile Youtube-Kanal, Stable Diffusion in Code (AI Image Generation) – Computerphile, 20.10.2022, https://www.youtube.com/watch?v=-lz30by8-sU
[10] J. Rafid Siddiqui, What are Stable Diffusion Models and Why are they a Step Forward for Image Generation?, 20.09.2022, https://towardsdatascience.com/what-are-stable-diffusion-models-and-why-are-they-a-step-forward-for-image-generation-aa1182801d46
[11] Cisco Systems, Künstliche Intelligenz, https://www.cisco.com/c/de_de/solutions/artificial-intelligence.html
[12] HPE Aruba, Künstliche Intelligenz, https://www.arubanet works.com/de/products/verwaltung/kuenstliche-intelligenz/
[13] Juniper Networks, AI for IT Operations (AIOps), https://www.juniper.net/de/de/solutions/artificial-intelligence-for-it-opera tions-aiops.html
[14] Lancom Systems, Lancom Active Radio Control ™ 2.0, https://www.lancom-systems.de/technologie/wlan-optimierung-mit-active-radio-control-2-0
[15] 3GPP, 5G Release 18, https://www.3gpp.org/specifications-technologies/releases/release-18
[16] Open Ai, ChatGPT: Optimizing Language Models for Dialogue, https://openai.com/blog/chatgpt/


