
aus dem Netzwerk Insider August 2021
Zeitgemäße IT-Angebote sind IT-Services. Eine reine Vermeidung von Totalausfällen wird nicht als angemessene Service-Qualität akzeptiert. Zur Zufriedenheit der Service-User bereitgestellte Angebote weisen eine erwartete (Mindest-)Performance auf. Ob über Service Level Agreements (SLAs) abgesichert, oder „nur“ durch eine Nutzungsvereinbarung – wer ein solches Service-Angebot zu verantworten hat, muss eine entsprechende Erwartungshaltung bedienen.
Zunehmend kommt im dafür notwendigen Monitoring und in Add-On-Anzeigen zu Apps der Begriff der User Experience auf. Performance Monitoring, aus User-Sicht vor allem auf Anwendungsebene, bietet Antworten auf die damit verbundenen Fragen nach Messbarkeit, automatisierter Auswertung, Alarmierung und Diagnosehilfen.

Wer allerdings hofft oder gar versucht, mit entsprechend hinzugekauften Funktionalitäten in seiner Monitoring-Ausstattung schnell und einfach in diesem Sinne erkannte Lücken erfolgreich zu schließen, wird enttäuscht sein und scheitern. Der vorliegende Artikel versucht, ein notwendiges Grundverständnis zu vermitteln und aus der Praxis die Augen für typische Fehler und Fallen zu öffnen. Eine Tool-Ausstattung ist nur so gut, wie sie zum Bedarf passt und beherrscht wird – das gilt für Performance Monitoring ganz besonders.
Performance als Qualitätsparameter für IT-Angebote und -Monitoring
Wer eine IT-Lösung verwendet, nutzt genau genommen einen IT-Service. Auch wenn nicht über einen als App bezeichneten Client erkennbar ein Cloud-Service genutzt wird, ruft man nicht einfach eine Anwendung auf und arbeitet damit. Es reicht längst nicht mehr, dass die Lösung startet, man sich erfolgreich anmelden kann und irgendwie die angebotenen Möglichkeiten zur Verfügung hat. Stillschweigend wird eine Nutzungsqualität erwartet, die über reines Funktionieren hinausgeht.
Was diesem Anspruch nicht mehr genügt, ist das isolierte Monitoring einzelner Teillösungen. Die reine Addition von guten technischen Einzelzuständen hat einer Betrachtung des Ende-zu-Ende-Ergebnisses aus Nutzersicht zu weichen: Jede Teillösung für sich kann im Monitoring ihres Betreibers „grün“ sein, und dennoch kommt beim Service-Nutzer ein Ergebnis an, mit dem dieser nicht zufrieden ist.
Ein wesentlicher Parameter ist „Performance“. Wer möchte schon lange warten, ehe eine Anmeldemöglichkeit erscheint bzw. die Einstiegsansicht zur Lösung am Bildschirm zu sehen ist und auch genutzt werden kann? Wie lange dauert es vom Klick zum angezeigten Ergebnis, bzw. beim mauslosen Endgerät vom Antippen zur Ergebnisanzeige?
Erklärt man Performance zu einem qualitäts- und damit letztlich verfügbarkeitsrelevanten Aspekt, muss man für das entsprechende Monitoring die nötige Messbarkeit und Objektivität herstellen. Was ist im Sinne der oben wiedergegebenen Nutzerperspektive „lange“, was ist im Sinne eines akzeptablen Nutzens bzw. eines Service Level Agreement (SLA) „zu lange“? Dauert alles lange, oder sind es nur bestimmte Vorgänge, und welche Teilbeiträge sind an den problematischen Vorgängen beteiligt?
Bei der letzten Fragestellung kommen wir in den Übergang vom reinen Monitoring zur Diagnose. Ideal ist natürlich, wenn man dann nicht automatisch das Werkzeug wechseln muss, um weiterzukommen. Zumindest wäre es aus Effizienzgründen gut, die Monitoring-Daten weiter nutzen zu können, bis man einkreisen kann, welcher Betreiber eines Teils der Leistungskette zum Service mit seinen speziellen Hilfsmitteln tiefer in die Analyse einsteigen muss.
User Experience messen – die Applikationsebene ist zu betrachten
Monitoring von Netzkomponenten, inklusive deren Durchsatz und deren Auslastung, das kennt man schon eine gefühlte Ewigkeit. Tatsächlich war Monitoring anfangs vor allem Netzmonitoring, einschließlich der Erreichbarkeit der IP-Adressen vernetzter Geräte. Mit der Zeit sind Monitoring der Systembasis von Anwendungen und Diensten, der zugehörigen Ressourcenauslastung und der grundlegenden Verfügbarkeit von Anwendungs- und Systemprozessen ebenfalls typisch im Monitoring erfasste Themen geworden.
User Experience im Sinne der oben beschriebenen Situationen lässt sich so nicht erfassen. Lediglich grundlegende Auslöser in Form von Engpässen oder häufigem Umschalten im Rahmen von Redundanzmechanismen können so entdeckt werden. Warum reicht das nicht für ein erwartetes proaktives Service-Management?
Immer erst auf eine Flaschenhals-Situation zu reagieren, bei der (fast) nichts mehr vorwärts geht, wäre im Sinne des Service-Gedankens mit SLA-Erwartungen zu spät. Am Endgerät können schon vor einem solchen Service-Down-Zustand schlechte Antwortzeiten beobachtet werden. Außerdem können schlechte Antwortzeiten als Reaktion auf Aufrufe oder Eingaben am Client auch andere Gründe haben. Manche Apps und Dienste reagieren bereits empfindlich auf Ungleichmäßigkeiten, bei anderen sind allzu scharfe Timeout-Timer die Ursache dafür, dass auf einen Klick oder Touch im Hintergrund mehrere Anläufe erfolgen müssen, bis endlich ein Ergebnis da ist.
Schon bevor es zu solchen Aspekten automatisierte Monitoring-Hilfen gab, hat ComConsult für Kunden systematische Analysen zu Anwendungen durchgeführt, zum Beispiel wenn diese über eher „dünne“ WAN-Verbindungen Probleme machten. Das Hilfsmittel war der Protokoll- und Statistikanalysator. Die dabei zu nehmenden Hürden fallen beim Monitoring ähnlich an:
Mühselig musste man anfangs Client-Requests und zugehörige Replies in Paketaufzeichnungen finden und die Delta-Time zwischen den Zeitstempeln ausrechnen. Solche Einzelwerte waren dann tabellarisch aufzubereiten. Erst dann konnte man problematische Ausreißer ermitteln und Möglichkeiten suchen und verifizieren, um das jeweilige Problem zu entschärfen.
Bald bot gängige Analysator-Software zumindest für typische Protokolle und Standardanwendungen Arbeitserleichterung: Typische Request-Reply-Paare werden mit inzwischen gängiger Funktionalität automatisch ermittelt und als „Service-Response-Time“-Auswertungen o.Ä. aufbereitet. Zu wichtigen Protokollen wie http gibt es unterschiedliche Angebote an typischen Auswertungen. (siehe Abbildung 1)
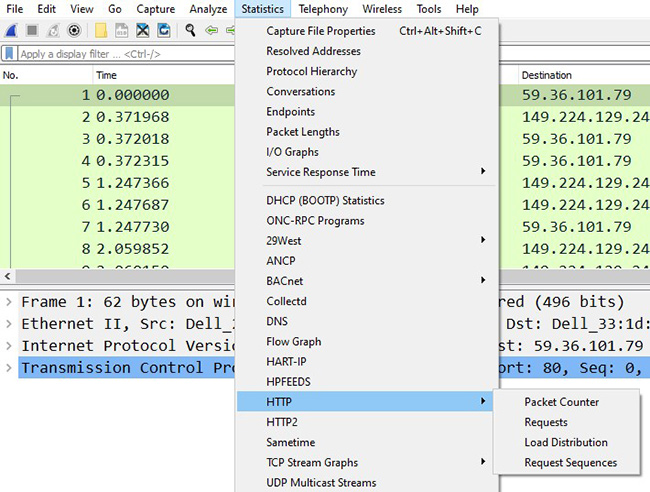
Abbildung 1: Statistik-Auswertungsoptionen – Beispiel Wireshark
Dennoch mühsam: Man benötigt für den erfolgreichen Einsatz freundliche Nutzer oder Nutzerinnen, die möglichst realitätsgetreu unter Verwendung unbedenklicher Testdaten eine Anwendungsnutzung als Basis einer Messung vorführen. Muss man das systematisch unter verschiedenen Arbeitssituationen bzgl. Netz- und Systemauslastung durchspielen, benötigt dies viel Arbeitszeit und zudem Disziplin und Geduld der Test-User. Ohne gegebenen Anlass wird man einen solchen Aufwand nicht betreiben.
Für jemanden, der aus der messtechnischen Fehlersuche-Praxis kommt, ist das Analysieren von Anwendungsperformance und die systematische Ermittlung problematischer User-Aktionen also nichts Neues.
Was jedoch neu ist: Mittlerweile bauen Anbieter von Services, insbesondere von per Browser oder Handy-App nutzbaren Angeboten, das Thema „User Experience“ in ihre Oberflächen oder Anzeigen mit ein. Ein „Performance-Dashboard“ in der Oberfläche macht bestimmt viele neugierig. Natürlich will der Anbieter einer solchen Oberfläche mit guten Werten glänzen, daher dieses Informationsangebot. Aber: Wer als Service-Nutzer da regelmäßig draufguckt, wird auch mitbekommen, wenn sich die Werte gegenüber den bislang üblichen plötzlich merkbar verschlechtern.
Auch deshalb muss die Frage „Reicht nicht ein Engpass-Monitoring zu den Komponenten der Servicekette?“ mit nein beantwortet werden. Der Service-Verantwortliche will nicht später als seine Kundschaft messtechnisch erkennbare Performanceverschlechterung mitbekommen (zumindest sollte so der Anspruch sein).
Dr. Suchmaschine liefert auf der Suche nach Antworten zu entsprechenden Monitoring-Funktionalitäten schnell Begriffe wie Digital Experience Monitoring (DEM), Application Performance Monitoring oder auch Application Performance Management (beides als APM abgekürzt). Ehe man sich mit Aspekten wie Lernfähigkeit von Tools, Diagnosen auf Anwendungsebene unter Berücksichtigung von Abhängigkeiten, sowie dem Angebot eines Monitoring-Tools als Software-as-a-Service-Lösung beschäftigt, ist es wichtig, grundlegende Ansätze zu verstehen. (siehe Abbildung 2)
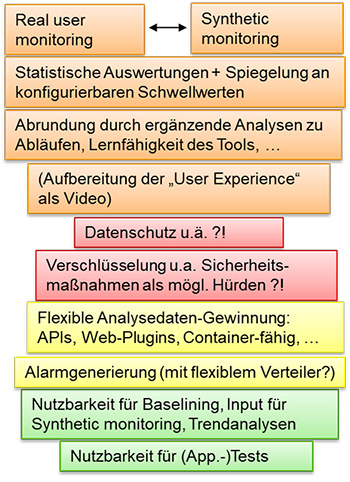
Abbildung 2: Performance Monitoring auf Anwendungsebene – Aspekte
Real User Monitoring oder Synthetisches Monitoring?
User Experience Monitoring (UEM) oder auch Digital Experience Monitoring (DEM) drücken schlichtweg das aus, was eingangs als Aufgabenstellung beschrieben wurde: messtechnisch und kontinuierlich für eine Überwachung erfassen, wie sich eine bestimmte Anwendung oder ein Cloud-Service aus User-Sicht darstellt. Was kommt an Performance an, gibt es Tendenzen zur Verschlechterung, werden gar in SLAs vereinbarte Schwellwerte gerissen?
Wie man diese Sichtweise prinzipiell erfasst, erklärt schon das Beispiel mit der systematischen Analysator-basierten Herangehensweise. Man erkennt an diesem Beispiel auch schon grundsätzliche Probleme, mit denen man zur Messwertgewinnung, wie sie für ein kontinuierliches Monitoring nötig ist, umgehen muss:
- Wie sorgt man für die notwendige Anwendungsnutzung, aus der Daten zum Antwortzeitverhalten von Anwendung bzw. Service gewonnen werden?
Die Lösung über Testpersonen wäre für kontinuierliche Messungen, wie sie für die typischen per Monitoring zu bedienenden Fragestellungen inklusive Alarmierung bei Incidents nötig sind, nicht praktikabel. - Wie aussagekräftig ist dabei die messtechnisch ausgewertete Nutzung?
„Das“ Nutzerverhalten gibt es nicht. Die Nutzungsweise kann sich je nach Aufgaben einer Person, doch auch abhängig vom Zeitpunkt ändern.
Es genügt also nicht, das klassische Monitoring-Problem zu bearbeiten, SLA- und umgebungsspezifische Schwellwerte für festgelegte Parameter zu setzen. Es kommt noch die Frage einer repräsentativen Messung hinzu.
Aktuelle Tool-Angebote bedienen hier zwei grundlegende Ansätze:
- Real User Monitoring, Real User Measurement (RUM)
Beim Real User Measurement wird das Antwortzeitverhalten auf Anwendungs- und Service-Ebene bei produktiver User-Aktivität gemessen.
Die Messung erfolgt passiv, d.h. ohne Einmischung der Monitoring-Lösung in das Geschehen. Es können nur für solche Vorgänge und Auslastungssituationen statistische Werte zur Antwortzeit ermittelt werden, die tatsächlich anfallen. Ergänzend können z.B. Fehlermeldungen gezählt werden, in deren Folge ein negativer User-Eindruck entstehen kann oder wird.
Manche Lösungen konzentrieren sich hierbei auf Web-Applikationen. Die Quelle ist dann z.B. ein Browser-Plugin. Will ein Anbieter seine eigene Lösung aus User-Perspektive überwachen, kann er auch direkt „Monitoring-Client“-Anteile in mobilen Web-Code oder in die bereitgestellte App einbetten. Der IT-Bereich einer Umgebung kann APM-Agenten-Software auf von ihm als Endgeräte bereitgestellte „Managed Clients“ ausrollen.
Grundsätzlich können bei Kenntnis entsprechender Protokolle bzw. Applikationsaufrufe und –mechanismen aber beliebige Anwendungsformen per RUM beobachtet werden.
Da es sich um produktive Zugriffe auf die entsprechenden Angebote handelt, fließt das Nutzungsverhalten der User bedingt in die Auswertung mit ein. - Synthetisches Monitoring, Synthetisches Transaction Monitoring (STM)
Hier wird das Nutzerverhalten automatisiert nachgebildet. Vereinfacht gesagt simuliert hier ein als Software realisierter Automat, z.B. ein Skript, typische User-Aufrufe und notiert die zugehörigen Antwortzeiten als Basis für statistische Auswertung.
Dies wird wiederholt durchgeführt, sodass man nach einem festgelegten Schema und Abstand entsprechende Aktivität und zugehörigen Input für die Performance-Statistik bekommt.
Beide Ansätze haben ihre Vor- und Nachteile, die man sich für die eigenen Monitoring-Fälle anschauen muss, um die passende Wahl zu treffen. Einen kleinen Ausschnitt zeigt die nachfolgende Gegenüberstellung. (siehe Abbildung 3)
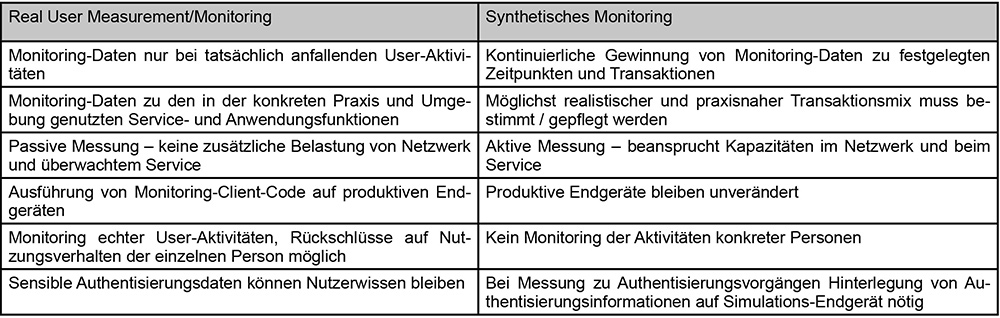
Abbildung 3: Übersicht: RUM vs. Synthetisches Monitoring – ausschnittsweiser Vergleich
Freundlicherweise mitwirkende Testpersonen braucht man in beiden Fällen nicht, was ein automatisierbares Monitoring überhaupt erst ermöglicht.
Aus dem Real-Time-User-Ansatz erhält man unmittelbar Informationen zum tatsächlichen Geschehen sowie Hinweise auf sich änderndes Verhalten und Aufkommen der Nutzung. Ein realistisches Baselining ist hier leichter möglich. Auch in Situationen mit hoher Parallelität der Nutzung durch viele User ist die passive Messung mit Blick auf die Auslastung von Netzwerk- und Service-Kapazitäten unschädlich. Dafür muss man vor dem Einsatz dieser Art von Messung den Bespitzelungsverdacht mit Blick auf die IT-nutzenden Personen ausräumen und je nach Klärung womöglich auf bestimmte Auswerte- und Diagnosemöglichkeiten verzichten.
Beim Synthetischen Monitoring ist man für die Datengewinnung nicht auf Nutzeraktivitäten angewiesen. Es lässt sich eine kontinuierliche Prüfung der grundlegenden Service-Performance realisieren, was etwa für die Kontrolle per SLA zugesagter Mindestkapazitäten und performance nutzbar ist. Allerdings muss man sich hüten, diese Methode unkontrolliert mit einer Vielzahl synthetischer Clients und hoher Taktung einzusetzen: Der damit verbundene Overhead an zusätzlicher Belastung von Netzwerk- und Service-Kapazitäten darf nicht zu Negativerlebnissen der eigentlichen User führen.
Zu bewertende und zu klärende Sicherheitsfragen gibt es in beiden Fällen. So muss man beim Synthetischen Monitoring oft Wissenskomponenten der Authentisierungsmethode auf den synthetischen Clients hinterlegen – mit entsprechendem Hacking-Risiko. Anwendungen und Dienste, die sich gegen automatisierte Zugriffe absichern, sperren Synthetisches Monitoring mit aus.
Dafür ist bei Aufrufen und Transaktionen im Real User Monitoring eine Beschränkung auf nicht-sensible Informationen und Daten nicht möglich. Die Verschlüsselungsoption bringt hier keine pauschale Heilung. Bei kompletter Verschlüsselung erblindet auch das Monitoring, da Transaktionsaufrufe und korrespondierende Rückmeldungen nicht mehr erkannt werden können. Statt Antwortzeitverhalten bleibt nur noch One-Way-Übertragungsdauer als Messgröße. Die User-Sicht kann man so nicht erfassen, sie endet vielmehr sehr nahe am reinen Erreichbarkeitsmonitoring.
Die Verschlüsselungsthematik in Kombination mit Monitoring-Bedarf ist ohnehin ein schwieriger Aspekt: Je stärker man Verschlüsselungslösungen inklusive Schlüsselmanagement macht, umso schwieriger wird die Einbindung von Monitoring-Lösungen als „berechtigte Mitwisser“. Dabei zählen oft die IT-Angebote, mit denen sensible Daten verarbeitet werden, auch zu den Verfügbarkeits- und Performance-kritischen. Der damit verbundene Zielkonflikt „Vertraulichkeit und Betriebspraxis“ würde hier im Detail zu weit vom Thema Monitoring wegführen, muss aber beachtet werden.
Insgesamt kommt man schnell zu dem Ergebnis, in der eigenen Umgebung beide Varianten des Monitorings aus User-Sicht kombiniert einzusetzen, um den Mix der wichtigen Anwendungen und Services gut abdecken zu können:
Wo es auf kontinuierlichen Test und Nachweis bestimmter (SLA-)Performance-Güte ankommt, drängt sich Synthetisches Monitoring auf. Mit einer repräsentativen Simulation realisiert man die testweisen Zugriffe und bekommt an Schwellwerten spiegelbare Werte, auch in Pausenzeiten der produktiven User. Bei Beschränkung auf eine vertretbare Zahl an Installationen von „synthetischen Usern“ ist die zusätzliche Belastung durch das Monitoring akzeptabel. Man misst sozusagen, welche Performance die nächsten hinzukommenden User noch erwarten könnten – auch die muss brauchbar sein.
Baselining zur Gewinnung von Schwellwerten für proaktives Monitoring (inklusive Alarmierung) erfordert ein Real User Monitoring, ebenso die Bestimmung realistischer Zugriffsverteilungen zur Verwendung im Synthetischen Monitoring. Nötigenfalls muss man doch hin und wieder eine abgestimmte, repräsentative Friendly-User-Sitzung organisieren, etwa bei Services, zu denen sich das Nutzerverhalten häufiger ändert.
Wer selbst Anwendungen entwickelt, z.B. Web-Anwendungen, kann mit einer Real-User-Monitoring-Auswertung Feedback bei der Erarbeitung neuer Versionen bekommen. Es besteht so die Möglichkeit, noch durch optimierende Anpassungen an der Anwendung auf auffällige Werte erfolgreich zu reagieren. Findet sich keine entsprechende Lösung, können aus dem Entwicklungsbereich die gemachten Monitoring-Beobachtungen als Eingangswerte an den Betrieb übergeben und Kapazitäten dann überprüft werden. Synthetische Messungen lassen sich auf Grundlage solchen Inputs im Sinne neuer Anwendungsfunktionalitäten angemessen aktualisieren.
Generell lassen sich zu neuen Anwendungen oder neuen Versionen mittels Real-User-Monitoring-Untersuchungen, durchgeführt bei vorbereitenden Tests oder in einer Pilotphase, wertvolle Daten für den produktiven „Betrieb“ gewinnen. Die immer wieder zu beobachtende Situation, dass auf Versionswechsel mit neuen Funktionalitäten unangenehme Überraschungen in Form vermeidbarer Tickets unmittelbar nach dem Rollout folgen, wird so weniger wahrscheinlich.
Alle beispielhaft genannten Nutzungs- und Kombinationsmöglichkeiten von Real-User- und Synthetischem Monitoring sind mit gezielter Nutzung dieser Optionen und damit mit Arbeit verbunden. Für typische Standard-Dienste und verbreitete Anwendungen kann ein entsprechendes Produkt vorbereitete Messungen und Aufbereitungen als Dashboards o.Ä. mitbringen, die eine brauchbare und realistische Ausgangsbasis darstellen.
Je umfassender das Angebot eines Services oder einer Anwendung ist und je spezieller die mit deren Hilfe durchgeführten Nutzungszwecke sind, umso mehr muss man selber auswählen. Messungen und Schwellwerte etc. müssen in Abhängigkeit von solchen Eigenschaften einer genutzten IT-Lösung an die eigene Umgebung angepasst werden. Hierzu muss man selbst aktiv beitragen. Ein Werkzeughersteller beschäftigt sachkundige Entwickler, keine Hellseher. Auch ein erfahrener System-Integrator kann nur gut passende Vorschläge zur Feineinrichtung machen, wenn man ihm die Zielumgebung, deren Anwendungsfälle und den eigenen Informationsbedarf im Monitoring erläutert hat.
- Wo will bzw. muss man selbst genauer hinschauen? Wo genügt ein grundlegendes Monitoring für einfache Parameter und tieferes Nachhaken bei Bedarf, womöglich konzentriert auf Ticket-Eröffnung und Fallbegleitung bei einem IT-Dienstleister?
- Wieviel kontinuierlich gewonnene und ausgewertete Monitoring-Informationen verkraftet man, wo ist im eigenen Fall die Grenze zur eher hinderlichen Informationsüberflutung?
- Welche Messungen will man für Diagnosefälle vorbereitet zur Verfügung haben, welche Personen sollen zur schnellen Generierung solcher Diagnosemöglichkeiten im Selfservice geschult werden?
Solche Fragen müssen passend zum eigenen Anwendungs- und Service-Mix beantwortet werden. Das muss so geschehen, dass man mit der Menge an Monitoring-Informationen geeignet versorgt, jedoch nicht überflutet wird. Die verschiedenen Rollen und Bereiche, die Monitoring-Angebote nutzen, müssen da aktiv mitarbeiten, bei der betrachteten User-Experience-Sicht und damit der Anwendungsebene oft intensiver als bei der Monitoring-Feinkonzeption zur Netz- und Systemüberwachung.
Network Performance Monitoring als wichtige Ergänzung
Nähern sich die Antwortzeiten aus User-Sicht einem problematischen Bereich, oder liegen bereits Meldungen aus Nutzergruppen vor, die als Performance-Incident zu behandeln sind, muss die Ursache und ein Ansatzpunkt zur Behebung gefunden werden.
Findet sich im Bereich der betroffenen Lösung tatsächlich ein System oder eine Anwendungskomponente mit einem offensichtlichen Ressourcen-Engpass, ist das natürlich ein vermutlicher Volltreffer. Performance-Probleme, auf die User empfindlich reagieren, fangen aber oft früher an. Außerdem: Im Zeitalter der Kombination von Eigen- und Fremdleistungen für einen IT-Service kommt man häufig selbst nicht so einfach zu den nötigen Einsichten. Im extremsten Fall eines Cloud-Services hat man womöglich aus gutem Grund die Betriebsverantwortung komplett in fremde Hände gegeben. Damit verbunden ist fallweise freiwillig oder je nach Verhalten des Service-Providers ein Verzicht auf Monitoring-Details zur Lösungsbasis des Services verbunden.
Was dann bleibt, ist oft nur das Eröffnen eines Tickets beim Service-Provider. Dumm nur, wenn der „nichts finden kann“, nach seiner Einschätzung bei ihm auch keine Ursache vorliegen könne, da „andere Kunden arbeiten können und sein Monitoring keine Störungen ausweist“. Sollte er recht haben, bleiben zwei Verdächtige in der Ursachenfindung: die betroffenen Clients selber, oder die Kommunikationswege von den Clients zum Service bzw. zum Eingang in die Umgebung des Service-Providers.
Ein grundlegendes Client-Problem kann ein gut geschulter Service Desk meist verifizieren bzw. eben ausschließen, z.B. wenn andere Services der vom gemeldeten Problem betroffenen Clients aus gut erreichbar und nutzbar sind. Bliebe der Übertragungsweg, „das Netzwerk“.
Die Anführungszeichen signalisieren, dass sich auch hier typisch verschiedene Teilbeiträge zu einem Gesamtweg addieren. Vielleicht ist es die zum mobilen Arbeiten von unterwegs bzw. aus dem Homeoffice genutzte VPN-Verbindung, die ausnahmsweise zu stark bremst und den Ansatzpunkt für die weitere Diagnose und Behebung bietet? Vielleicht ist es die Außenanbindung eines bestimmten Standorts oder der auf dem Weg zum Anwendungs-Service-Provider genutzte Internetzugang der eigenen Umgebung? Ebenfalls kann die vom Client für die Namensauflösung genutzte Methode zu längeren Antwortzeiten führen.
Im Incident-Fall wird man solche Fragen im Rahmen einer systematischen Fehlersuche durchprüfen und gegebenenfalls eine solche Ursache im Kommunikationsweg nach einer gewissen Zeit finden. Proaktiv ist das allerdings nicht. Findet man zudem in diesem Bereich keine konkrete, eindeutige Ursache des aus User-Sicht bestehenden Problems mit einem Service, kann man nur zum Betreiber dieses Services zurückkehren und zum eröffneten Ticket nachhaken.
Besser als die Aussage „wir konnten bei uns keine Auffälligkeiten finden“ ist natürlich, wenn man dem Service-Provider mit messbaren Fakten gegenübertreten kann. Diese können dann in die weitere (Ausschluss-)Diagnose einfließen. Je nach erstem Eindruck, welche Nutzergruppen betroffen sind, wird man fallweise sogar zunächst versuchen, eine offenkundige Ursache im Bereich von Netz- und Sicherheitsinfrastrukturen auszuschließen. Am falschen Ende oder beim falschen IT-Dienstleister mit einem Ticket tiefergehende Analysen anzustoßen, kann bedeuten, wertvolle Zeit bis zur wirklichen Problemlösung zu verschwenden.
Verkürzt gesagt: Was auf Anwendungsebene eine Antwortzeitanalyse, abgedeckt über APM-Möglichkeiten ist, ist auf Netzebene eine Laufzeitanalyse zwischen Kommunikationsendpunkten. Gewissermaßen ist hier das Gegenstück zum APM ein Netzwerk-Performance-Monitoring (NPM) mit den im Folgenden kurz dargestellten Möglichkeiten:
- Quelle entsprechender Rohdaten sind intelligente Komponenten in der Netzinfrastruktur
In der Vergangenheit zum Einkreisen von Übertragungsteilstrecken mit schlechter Performance genutzte Hilfsmittel wie Traceroute (tracert), Pathping usw. prallen mehr und mehr an Sicherheitsvorkehrungen ab, die ein Ausspionieren von Netzen verhindern sollen. Stattdessen liefern Netzkomponenten, die bestimmte Protokolle wie Netflow, IPFix, iflow oder netstream unterstützen, Zeitstempel-basierte Informationen über die Laufzeiten von Paketen, die solche Stationen in Netzen nacheinander durchlaufen.
Eine Monitoring-Lösung, die ihre entsprechende Autorisierung nachweisen kann, erhält so Eingangsdaten entlang verschiedener Kommunikationspfade. - In Verbindung mit einer Kenntnis der Netztopologie, in der sich so abfragbare Netzkomponenten befinden, ergibt sich ein Bild, wie der zeitliche Anteil bestimmter Teilstrecken an Gesamtlaufzeiten im Netz darstellt.
Entdeckt man punktuelle Ausreißer oder ganze Teilstücke mit ungünstigen Performance-Werten, lässt sich dies präventiv und reaktiv aufgreifen:
Neuralgische Punkte und Teilstrecken, bei denen man solche Ausreißer wiederholt wahrnimmt, bieten Ansatzpunkte für proaktive Alarme. Zu diesem Zweck ermittelt man fokussiert auf die Problemstellen Baselining-Werte als Vergleichsschwellen.
Treten Ausreißer als akutes Problem auf, liefern Messdaten zu Teilabschnitten mit schlechten Übertragungswerten wertvolle Ansatzpunkte für geschicktes Nachhaken durch tiefergehende Diagnose.
Wichtig: Derartige Messungen und der damit verbundene Aufwand können nur bei solchen Abschnitten von Netzwerk-Pfaden effektiv helfen, auf deren Zustand man steuernd einwirken kann. Diese gehören entweder zu Netzen, die man selbst überwacht und betreibt, oder deren Betreiber Dienstleister sind, die man steuern kann. Zudem muss man Zugang zu geeigneten Messpunkten haben. Für Teilstrecken über öffentliche Netze wie das Internet trifft dies nicht zu.
Hier muss man prüfen, was im eigenen Fall sinnvoll und möglich ist. Welche Komponenten mit entsprechender Intelligenzoption hat man zur Verfügung? Hat man die Möglichkeit zum entsprechenden Zugriff darauf? Wie viele der oben benannten, teils herstellerspezifischen Protokolle muss eine entsprechende Monitoring-Lösung verstehen? Wie organisiert man die Authentisierung für adäquat berechtigten Zugriff durch die Monitoring-Lösung? Inwieweit hängt die Aussagefähigkeit und damit das Verhältnis von Einsatz und Nutzen eines solchen NPM von Verschlüsselung der Datenströme (Transportverschlüsselung) ab?
Sowie natürlich: Wie kommen entsprechende Auswertungen und deren Anzeige unter Berücksichtigung der konkreten Netzstruktur und gewünschter Auswerte- und Anzeigemöglichkeiten zustande? Wie passt eine in die engere Wahl gezogene NPM-Lösung in die schon vorhandene Monitoring-Tool-Ausstattung? Ein Strauß an unterschiedlichsten Oberflächen und Bedieneigenheiten kann die zielsichere Nutzung spürbar behindern, mindestens aber den Zeitaufwand für Know-how-Aufbau und -Pflege deutlich erhöhen.
Hat man eine für die eigene Umgebung, die eigenen Zwecke und die eigenen Monitoring-Nutzer geeignete Lösung gefunden und eingerichtet, lassen sich APM und NPM koordiniert einsetzen. Die Service-Kette „vom Klick bis zur Ergebnisanzeige“ lässt sich gezielt bzgl. der Beiträge zur Gesamtperformance aus User-Sicht zerlegen. Dies kann man proaktiv, z.B. für Gegensteuern durch Kapazitäts- bzw. Service-Management bei schleichend negativen Trends einsetzen, aber auch reaktiv für Monitoring & Alarmierung sowie Diagnose bei Incidents.
Bewusst auswählen und nutzen – der Schlüssel zum Erfolg
Der Themenbereich Performance Monitoring inklusive entsprechender Tools ist deutlich umfangreicher und anspruchsvoller als der hier gemachte Versuch, die so automatisierbare Messbarkeit und ihre Sichtweisen einzuordnen.
Die gute Nachricht: Es gibt ein ernst zu nehmendes Angebot an Werkzeugen, das Stadium der möglichen neuen Geschäftsidee für Tool-Hersteller ist überschritten. Der zugehörige Markt sortiert und stabilisiert sich. Die Zukunftssicherheit von Anschaffungen lässt sich auch daran erkennen, welche Hersteller das Thema aufgegriffen haben.
Wer sich in der Vergangenheit schon mit entsprechenden Angeboten beschäftigt hat bzw. verstehen möchte, wo eine solche Erweiterung von bereits eingesetzten Monitoring-Produktlinien einzuordnen ist, muss allerdings ein wenig recherchieren bzw. am Ball bleiben. Auch kommen spezielle Anwendungsformen (v.a.: Web-Applikationen/Apps) und spezialisierte Angebote hinzu.
Insgesamt sieht man sich einem breiten Angebot gegenüber. Um dieses effektiv nutzen zu können, ist je nach Produkt Eigenleistung in unterschiedlicher Form nötig:
- umfangreiches Scripting
- manuelle Unterlegung mit Details zur Umgebung und den genutzten Services bzw. Anwendungen
- bewusste Auswahl aus umfangreichen Startangeboten und notwendige Feinanpassung an zugehörigen Hersteller-Default-Einstellungen.
Von Netz- und Systemmonitoring schon bekannte Möglichkeiten für übergreifende Statusauswertungen und Analysehilfen wie Root-Cause- und Impact-Analysen werden je nach Werkzeug auch auf APM-Daten erweitert.
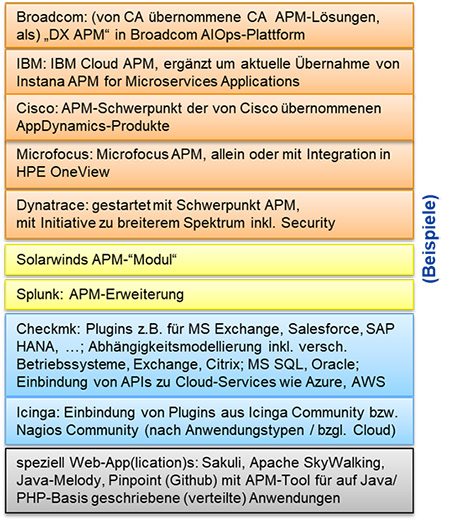
Abbildung 4: Spannweite des Angebots an APM-intelligenten Lösungen – Beispiele
Die Beispiele in der nachfolgenden Abbildung sollen dazu einen kleinen Einblick vermitteln. Sie sind selbstredend ohne Anspruch auf Vollständigkeit zusammengestellt, auch sind genannte Produkte und Hersteller nicht als besondere Empfehlungen zu verstehen. Vielmehr soll zum einen die Breite der Wahlmöglichkeiten illustriert werden. Zum anderen sollen Optionen vorgeführt werden, wie man bereits vorhandene Monitoring-Ausstattungen mit Ergänzungen aus Hand bekannter Hersteller und Lieferanten gezielt erweitern kann. (siehe Abbildung 4)
Mit der dargestellten Breite an Optionen, was reine APM-Grundfunktionalität, abgedecktes Anwendungs-Spektrum und das Angebot an vorbereiteten Default-Analysen für verbreitete Anwendungen und Services betrifft, soll das Signal gegeben werden:
Eine gezielte Optimierung der eigenen Monitoring-Ausstattung zur Verstärkung der User-Perspektive erfordert mehr als ein bisschen Suchmaschinen-Nutzung oder Lesen eines Artikels, und anschließende Einkaufstour zur Tool-Erweiterung. Wer im Wesentlichen Web-Services und –Anwendungen zu erfassen hat, kann anders herangehen als jemand, der Cloud-Services, eigene Anwendungen in fremdbetriebenen Infrastrukturen oder Full-Managed-Service-Angebote bzw. Mischungen daraus überwachen muss.
Bei Bereitstellung und Betrieb der APM-Monitoring-Lösungen kann man ebenfalls zwischen Eigenbetrieb und Fremdbetrieb wählen. Viele Herstellerangebote umfassen die Bereitstellung als Service in der „Cloud“ des Tool-Herstellers, ja favorisieren und bewerben dies schwerpunktmäßig. So lassen sich Hilfen zur bedarfsgerechten Anpassung der Feineinrichtung und Anzeigen mittels maschinellem Lernen unterstützen sowie Analysehilfen zukünftig mit weiterführender künstlicher Intelligenz unterlegen. Voraussetzung allerdings: Man selbst ist bereit und erhält die Freigabe vom Risiko- und Sicherheitsmanagement, solche Informationen über die eigene IT-Ausstattung und deren Zustand in eine fremdbetriebene Umgebung zu geben. (siehe Abbildung 5)
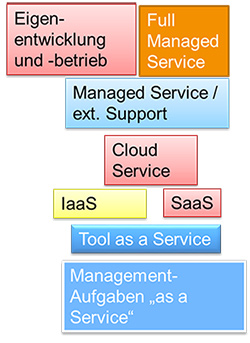
Abbildung 5: Bereitstellungsformen von Services und Monitoring-Tools – Einflüsse für APM-Wahl
Fazit
Wer sinnvoll die Service-User-Sicht stärker in sein Monitoring aufnehmen will, muss sich mit einer Reihe von technischen Möglichkeiten beschäftigen, seinen konkreten Bedarf an Informationen und Antworten bestimmen und einen dazu passenden Einstieg finden.
Die Produktauswahl ist dabei ein wichtiger Arbeitsschritt, der die genauere Beschäftigung mit den dadurch gegebenen Möglichkeiten erfordert. Die Einbindung der notwendigen Datenquellen erledigt sich auch nicht nebenbei oder gar vollständig „out of the box“. Erst der planvolle Zuschnitt der davon genutzten Mess- und Anzeige-Optionen für die verschiedenen Monitoring-Nutzergruppen entscheidet letztlich über den konkreten Nutzen, den man über eine eingeführte APM-Möglichkeit erzielt.
Hier müssen diese Nutzergruppen nicht nur mitgenommen werden, sondern kontinuierlich mitwirken – nur sie können ihren konkreten Bedarf benennen, an den richtigen Stellen eine schädliche Informationsüberflutung per Veto stoppen, und nicht zuletzt: APM-Lösungen liefern Hilfestellung und Daten und sparen hierdurch Zeit. Sie übernehmen jedoch nicht die richtige Deutung und zielgerichtete Ableitung von Erkenntnissen und notwendigen Eingriffen, um Services und Anwendungen (wieder) in einen aus User-Sicht geeigneten Zustand zu bringen.
Nur wer seine Umgebung und die Tools gut kennt, für den werden sich die in solche Ausrüstung gesetzten Erwartungen auch erfüllen. Andernfalls droht im schlimmsten Fall eine in der Praxis von IT-Services-Tools immer wieder zu beobachtende teure Investitionsruine: Mächtige und gute Produkte, die nicht beherrscht werden und mit minimalem Nutzen vor sich hin laufen.



Kontakt
ComConsult GmbH
Pascalstraße 27
DE-52076 Aachen
Telefon: 02408/951-0
Fax: 02408/951-200
E-Mail: info@comconsult.com