Im Juni letzten Jahres erschien ein erster Artikel zum Thema „CPU-Sicherheit“ im Netzwerk-Insider. Darin wurde bereits darauf hingewiesen, dass auf Basis von Spectre und Meltdown neue architekturbedingte Sicherheitslücken entdeckt wurden, aber Details waren noch nicht bekannt. In den vergangenen 10 Monaten sind diese (und weitere) Sicherheitslücken veröffentlicht und im Detail beschrieben worden. Außerdem konnten in dieser Zeit die Auswirkungen auf den realen Betrieb von IT-Systemen beobachtet werden. Dieser Artikel soll eine Übersicht über die wichtigsten neuen Informationen geben, speziell über die neuen Sicherheitslücken, wobei diese technisch detailliert behandelt werden müssen. Außerdem werden neue Informationen zu den Auswirkungen von Gegenmaßnahmen betrachtet sowie eine Einschätzung zur aktuellen Gefährdungslage dargestellt.
1. Sicherheitslücken in CPUs – eine kurze Wiederholung
Um zu verstehen, was die aktuellen Sicherheitslücken in CPUs ermöglicht und wo die Gefahren liegen, soll in diesem Kapitel noch einmal in Kurzform eine Übersicht über die Funktionen „Out-of-Order-Execution“ und „Speculative Execution“ in modernen CPUs dargestellt werden. Außerdem werden die ursprünglichen Versionen von Spectre und Meltdown erläutert. Für eine detaillierte Beschreibung dieser Themen sei auf den entsprechenden Artikel im Netzwerk Insider von Juni 2018 verwiesen
[1].
1.1 CPU-Technologien
Bei den CPU-Technologien sind zum Verständnis der Sicherheitslücken drei Aspekte zu nennen: Caches, „Out-of-Order-Execution“ und „Speculative Execution“; alle drei sollen hier nur kurz angeschnitten werden, um ein grundlegendes Verständnis für die Funktionsweise von Spectre und Meltdown zu schaffen.
Wichtig ist zunächst im Hinterkopf zu behalten, dass CPUs sehr viel schneller sind als der Arbeitsspeicher, auf den sie zugreifen. Dadurch werden bei jedem Zugriff auf den Arbeitsspeicher viele Taktzyklen verschwendet. Heutzutage kann eine CPU in der Zeit, die ein Ladevorgang aus dem Arbeitsspeicher benötigt, bis zu 1000 Instruktionen abarbeiten. Um diese Diskrepanz zu maskieren, besitzen CPUs Cache-Stufen, die Daten aus dem Arbeitsspeicher zwischenspeichern und eine deutlich geringere Zugriffszeit besitzen als der Arbeitsspeicher. Es gibt, abgestuft nach Kosten, mehrere Cache-Stufen (sog. Level), die sich in Größe und Geschwindigkeit unterscheiden. Typischerweise gibt es drei Ebenen:
- Extrem schneller, aber sehr kleiner (< 1 MB) Level-1-Cache (L1)
- Sehr schneller, größerer L2-Cache (wenige MB)
- Schneller L3-Cache (> 10 MB)
Eine Skizze der Technologien „Out-of-Order-Execution“ und „Speculative Execution“ ist in Abbildung 1 dargestellt.
Out-of-Order-Execution
Bei der Out-of-Order-Execution moderner CPUs wird die Reihenfolge von Instruktionen innerhalb eines auszuführenden Programms modifiziert, um die einzelnen Bereiche einer CPU (Gleitkomma-Einheit, Fließkomma-Einheit, Vektor-Einheit etc.) optimal zu nutzen. Das ist natürlich nur möglich, sofern die Daten bereits in den Cache geladen wurden oder andere Teile des Programms lange genug brauchen, um einen Ladevorgang aus dem Arbeitsspeicher zu rechtfertigen. Komplexe Logik innerhalb der CPUs stellt sicher, dass Änderungen der Reihenfolge das Ergebnis der Ausführung nicht beeinflussen. Trotzdem kann es dazu kommen, dass Zugriffe erfolgen, die nicht erlaubt sind und sog. „Exceptions“ auslösen. In diesem Falle wird der ursprüngliche Zustand vor der Ausführung (theoretisch) wiederhergestellt. Allerdings kann, wie im Folgenden beschrieben, die CPU dazu gebracht werden, auch Instruktionen nach einem eigentlich unerlaubten Zugriff auszuführen.
Speculative Execution
In nahezu allen Programmen kommt es irgendwann zu Verzweigungen des Ausführungspfads. Ein typisches Beispiel ist hier ein „if-then“-Konstrukt, also eine „Wenn-Dann“-Abfrage. Hier wird die Performance normalerweise reduziert, da keine Instruktionen jenseits der Abfrage durch Out-of-Order-Execution ausgeführt werden können. Hier setzt „Speculative Execution“ an; es wird der wahrscheinlichste Pfad ermittelt oder durch vorherige Ausführungen gelernt und schon einmal „auf Verdacht“ ausgeführt. Diese Ausführung kann auf schon im Cache vorhandene Daten zugreifen oder schon im Voraus Daten aus dem Arbeitsspeicher laden und diese verarbeiten. Sollte der Verdacht stimmen, gewinnt man viele Taktzyklen. Sollte der Verdacht nicht stimmen oder eine Exception auftreten, so wird – wie bei „Out-of-Order-Execution“ – der ursprüngliche Zustand (zumindest theoretisch) wiederhergestellt und die Applikation wie eigentlich geplant fortgesetzt.
1.2 Spectre und Meltdown
Die dargestellten Technologien wurden mit starkem Fokus auf Performance entwickelt. Etwaige Folgen für die Sicherheit wurden nur bedingt betrachtet. Dies liegt vor allem an der Zeit, in der diese Technologien entwickelt wurden und nicht am mangelnden Sicherheitsbewusstsein der Entwickler. Vor 20 Jahren war eine so stark parallele Nutzung von CPU-Ressourcen durch verschiedene User kaum denkbar wie sie im Zeitalter der Virtualisierung üblich ist. Diese wurde erst durch die Einführung von Multi-Core-CPUs sinnvoll. Ihren bisherigen Höhepunkt hat diese parallele Nutzung mit dem Aufstieg der Cloud gefunden. Gerade für die Wirtschaftlichkeit eines Cloud-Angebots ist eine gleichzeitige Nutzung von Ressourcen durch mehrere Kunden – unter Umständen sogar durch miteinander konkurrierende Firmen – eine Grundvoraussetzung.
Mit der Entdeckung von Spectre und Meltdown sowie deren verschiedenen Variationen wurden vergangene Versäumnisse beim Blick auf Sicherheitsaspekte von CPUs schmerzhaft verdeutlicht.
Dabei sei noch darauf hingewiesen, dass die Gefahr von Spectre und Meltdown darin liegen, dass die in Kapitel 1.1 erwähnte Wiederherstellung des Ursprungszustands der CPU nicht vollständig ist. Die bereits in den Cache der CPU geladenen Daten werden nicht wieder entfernt.
Insgesamt ist das Ausnutzen von Spectre und Meltdown – auch in ihren neuen Versionen – sehr komplex. Ein Angriff in dieser Form muss sehr genau auf das geplante Ziel zugeschnitten werden und erfordert sehr viel Knowhow. Daher ist – zumindest momentan – davon auszugehen, dass diese Sicherheitslücken, wenn überhaupt, nur von staatlich finanzierten Hackergruppen ausgenutzt werden können. Wie in Kapitel 4 dargestellt wird, sind bisher aber noch keine Angriffe bekannt.
Im Folgenden soll kurz beschrieben werden, wie die ersten beiden Sicherheitslücken funktionieren.
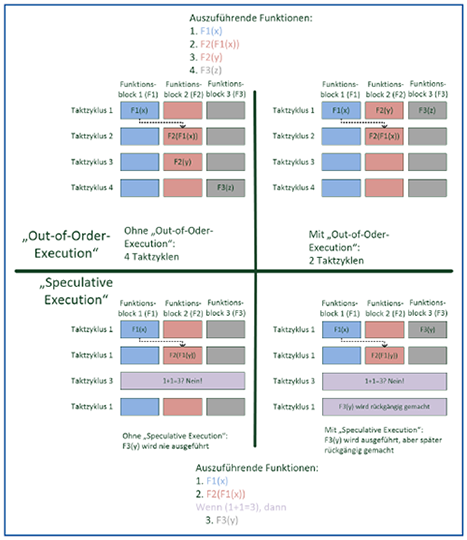
Abbildung 1: Schematische Darstellung von „Out-of-Oder-Execution“ und „Speculative Execution“ [1]
Spectre bedient sich der „Speculative Execution“, um eigentlich nicht zugängliche Daten auszuspähen. Dazu wird durch ein von einem Angreifer kontrolliertes Programm die CPU darauf trainiert, ein bestimmtes Abfrage-Ergebnis als wahrscheinlich anzusehen. Anschließend wird die Abfrage und ein innerhalb der Abfrage getätigter Speicherzugriff modifiziert. Zwar erkennt die CPU bei der Ausführung der Abfrage den Fehler und stellt den Ursprungszustand wieder her, doch die zuvor im Rahmen der spekulativen Ausführung geladenen Daten sind nach wie vor im CPU-Cache vorhanden und können über einen Seitenkanal ausgelesen werden. Dazu wird vor dem Angriff der CPU-Cache geleert und mit einem möglichen Wert der auszulesenden Daten gefüllt. Ein Beispiel hierfür wären die einzelnen Bytes eines Verschlüsselungs-Keys. Nach dem Angriff kann dann über Messungen der Zugriffszeit auf die auszuspähenden Daten ermittelt werden, ob diese aus dem Arbeitsspeicher geladen wurden oder ob der „geratene“ Wert im Cache stimmt. Es handelt sich dabei um einen langsamen Prozess mit geringen Übertragungsraten, aber bestimmte Daten, wie beispielsweise Verschlüsselungs-Keys oder Passwörter können trotzdem mit ausreichender Geschwindigkeit ausgelesen und an einen Angreifer übermittelt werden.
Meltdown
Bei Meltdown wird ebenfalls das Verhalten der CPU ausgenutzt, alle gelesenen Daten im Cache abzulegen. Doch statt einen bestimmten Ausführungspfad in einem Programm zu nutzen, wird die „Out-of-Order-Execution“ ausgenutzt. So wird eine Reihe von Instruktionen auf der CPU ausgeführt, die einen unzulässigen Speicherzugriff beinhaltet. Die Reihenfolge ist dabei so gewählt, dass der unzulässige Zugriff nach der Optimierung der Instruktionsreihenfolge zu einem früheren Zeitpunkt geschieht als im Programm eigentlich vorgesehen. Dadurch können auch hier – noch bevor die Exception verarbeitet wird – Daten in den Cache übertragen und auf ähnliche Art und Weise wie bei Spectre ausgelesen werden.
2. Neue Sicherheitslücken
Dass die ersten Meldungen von Spectre und Meltdown nur die Spitze des Eisbergs darstellen würden, war schon zu Beginn der Berichterstattung sehr wahrscheinlich. Und so wurden bereits neue Sicherheitslücken „angekündigt“ als die ersten gerade erst bekannt wurden. Diese, so wie alle weiteren, seither bekannten Sicherheitslücken moderner Prozessorarchitekturen im Umfeld von Spectre und Meltdown, sollen im Folgenden beschrieben werden. Dabei wird aufgrund der Komplexität der technische Tiefgang minimiert und nur sehr grob auf die Details eingegangen. Der interessierte Leser sei hier auf [2] verwiesen. Aus dieser Veröffentlichung ist auch die grobe Aufteilung übernommen, wie sie in Abbildung 2 dargestellt ist.
An dieser Skizze sieht man sehr deutlich, dass aus den ursprünglich zwei Sicherheitslücken eine Vielzahl verschiedener Angriffsszenarien entwickelt werden konnte, und dass die Entdeckung weiterer Lücken nicht unwahrscheinlich ist. Es sind noch genauere Unterscheidungen innerhalb dieser Angriffe möglich. In diesem Artikel wird im Weiteren aber nicht auf jede einzelne Angriffsform eingegangen.
Eine weitere beunruhigende Nachricht war die Veröffentlichung der Lücke „NetSpectre“, die eine Ausnutzung von Spectre über das Netzwerk ermöglicht hat. Hier sind aber glücklicherweise Gegenmaßnahmen auf verschiedenen Ebenen, unter anderem im Netzwerk, möglich.
Auch wurde ein Weg gefunden, auf Basis der CPU-Architektur zusätzliche Informationen über die physische Verteilung von gespeicherten Daten im Arbeitsspeicher zu ermitteln, die in Verbindung mit anderen Angriffen (Rowhammer [3]) eine Änderung von Daten erlaubt.
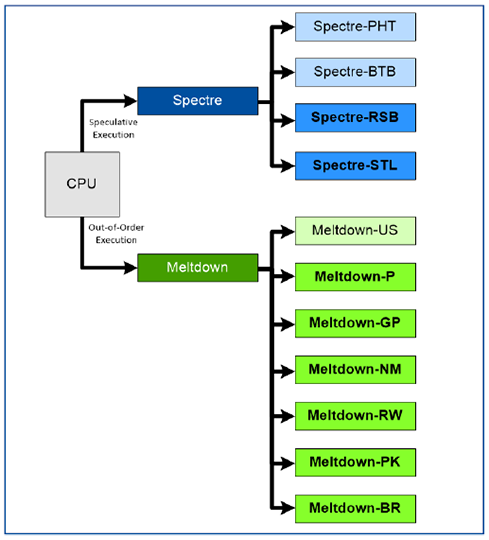
Abbildung 2: Systematische Untersuchung von CPUs auf Basis von Spectre und Meltdown durch Forscher. Alle dargestellten Sicherheitslücken sind bekannt und können ausgenutzt werden. Die fett dargestellten Sicherheitslücken sind in [2] entdeckt und zum ersten Mal ausgenutzt worden.
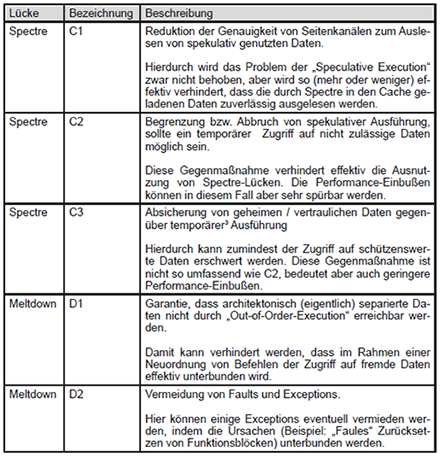
Die in den Medien gängige Bezeichnung „Spectre V“ für Spectre-basierte Lücken ist wenig zielführend. So ist weder die genaue Ursache noch die Kritikalität aus dem Namen zu erkennen. Um zumindest die Ursache besser nachvollziehen zu können, wird in diesem Artikel die Nomenklatur aus [2] übernommen, die sowohl für Meltdown als auch für Spectre gilt. Damit ergibt sich die Bezeichnung „Spectre-“ bzw. „Meltdown-“, um die ursächliche Funktionseinheit der CPU direkt zu benennen. Es gelten für die Architekturelemente die in Tabelle 1 aufgeführten Abkürzungen. Die Ausnutzbarkeit der jeweiligen Lücke auf CPUs von Intel, AMD und/oder ARM ist ebenfalls aufgeführt. Lücken, die theoretisch betrachtet aber nicht erfolgreich ausgenutzt wurden, sind nicht aufgeführt.
Auf Basis dieser Nomenklatur werden im Folgenden die neuen Angriffe auf Basis von Spectre und Meltdown beschrieben.
2.2 Neue Spectre-Versionen
Zu den bereits im Mai letzten Jahres bekannten Sicherheitslücken (Spectre-BHT und Spectre-PTB) gesellen sich zwei neue Ansätze: Spectre-RSB und Spectre-STL.
Spectre-RSB
Nach dem Aufruf einer Funktion auf CPU-Ebene („call“-Instruktion) wird der „Return Stack Buffer“ (RSB, Tabelle 1) genutzt, um die Adresse nach der Rückkehr aus der Funktion zu speichern. Der RSB ist dabei in jedem (physischen) CPU-Kern vorhanden und in der Anzahl der gespeicherten Adressen begrenzt. Sollten die Funktionsaufrufe stark verschachtelt sein (und damit mehr Adressen notwendig sein als im RSB vorhanden) oder ein Angreifer die Instruktionen an der gespeicherten Adresse modifizieren, ergibt sich so die Möglichkeit, eigenen Code im Rahmen von „Speculative Execution“ auszuführen. Dieser Angriff bietet sich insbesondere an, um aus abgeschotteten Umgebungen (sog. „Sandboxes“) auszubrechen, wie sie beispielsweise im Desktop-Bereich bei vielen Browsern zum Einsatz kommen.
Spectre-STL
Beim „Raten“ der CPU, welcher Ausführungspfad am wahrscheinlichsten ist, müssen Daten berücksichtigt werden, von denen die CPU nicht genau weiß, ob sie vorher verändert werden oder nicht. Hier dient der STL (Store To Load) der Vorhersage von Abhängigkeiten zwischen Lade- und Speicherinstruktionen. Sollte eine Abhängigkeit unwahrscheinlich (oder auszuschließen) sein, können Daten spekulativ geladen werden, was wiederum zur Befüllung des Caches genutzt werden kann. Sollte doch eine Überschneidung gefunden werden, so werden nur die geänderten Bereiche neu geladen, was eine bessere Ausnutzung des CPU-Caches zur Folge hat.
In Verbindung mit spekulativer Ausführung können aber auch Daten geladen werden, die eigentlich vor der Ausführung verändert werden sollten. So kann über einen Seitenkanal der „alte“ Stand der Daten ausgelesen werden. Da diese Daten auch Verweise auf andere Speicherbereiche (sog. Pointer) enthalten können, ist es so auch möglich, bestimmte Überprüfungen zu Zugriffsrechten oder Datentypen der Zielbereiche im Speicher zu umgehen.
2.3 Neue Meltdown-Versionen
Auch im Bereich von Meltdown haben sich neue Angriffsformen ergeben. Insgesamt sechs neue Angriffsvektoren haben sich seit Juni letzten Jahres ergeben:
Meltdown-P
Dieser Angriff ist speziell auf das Ausspähen von Intel SGX-Enklaven und in erweiterter Form auf die Überwindung von Isolationsmechanismen eines Betriebssystems oder sogar Hypervisors ausgelegt. Hier können beispielsweise Funktionen bei der Nutzung des L1-Caches dazu genutzt werden, Daten aus einer SGX-Enklave zu extrahieren. Dazu wird ein bestimmtes Bit (Present Bit) im Speicher ausgenutzt, um entsprechende Speicherbereiche anzugreifen.
Im Virtualisierungsumfeld kann ein Fehler bei der Übersetzung von Gast-VM-Speicheradressen zu Speicheradressen des Virtualisierungshosts weiter dazu führen, dass eine VM vollständigen Zugriff auf den L1-Cache inkl. der Daten aus anderen VMs erhält.
Meltdown-GP
Ursprünglich von ARM entdeckt, wird hier die „Out-of-Order-Execution“ genutzt, um Instruktionen auf eigentlich nicht zugänglichen Daten auszuführen. Bevor die resultierende „General Protection Exception“ (#GP) abgefangen und behandelt wird, können hier bereits Daten extrahiert werden. Dieser Ansatz ist sehr ähnlich zur ursprünglichen Meltdown-Lücke. Hierbei können eigentlich für einen Angreifer nicht zugängliche Daten ausgespäht werden.
Meltdown-NM
Bei Meltdown-NM wird die „Faulheit“ der CPU bei einem Context Switch (z.B. dem „Umschalten“ von einer Applikation zu einer anderen) ausgenutzt. Hier sollte normalerweise der Zustand aller CPU-Funktionsblöcke gespeichert und in einen definierten Zustand überführt werden. Da dieser Zustand aber bei einigen Funktionsblöcken sehr viele Daten enthält und eine Speicherung und ein Überführen in einen definierten Zustand zeitaufwendig ist, wird dies im Allgemeinen vermieden. Sollte die Funktionseinheit doch benötigt werden, so wird eine „Device-not-available“-Exception (#NM – daher der Name) ausgelöst und erst dann der Zustand gespeichert. Durch eine geschickte Nutzung der „Out-of-Order-Execution“ ist es hier aber möglich, vor Verarbeitung der Exception die schon vorhandenen Daten auszulesen. Hierbei können eigentlich für einen Angreifer nicht zugängliche Daten ausgespäht werden.
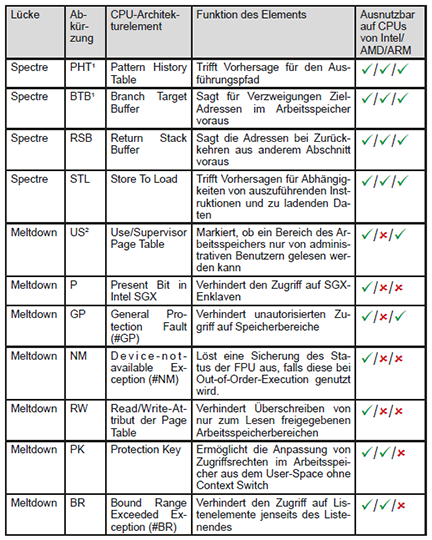
Tabelle 1: Abkürzungen der Architekturelemente
Meltdown-RW
Ursprünglich als „Spectre V1.2“ bezeichnet, hat eine genauere Untersuchung ergeben, dass es sich hierbei um eine Ausnutzung der „Out-of-Order-Execution“ und nicht der „Speculative Execution“ handelt. Bei Meltdown-RW können Daten in der momentanen Berechtigungsstufe (z.B. User oder Kernel) unabhängig von eventuellen Lese- und Schreibrechten (Read/Write – RW) modifiziert werden, was eine Umgehung von Sandboxing-Funktionen ermöglicht, solange sich eine Software auf die CPU-Mechanismen zum Schutz des Speichers verlässt.
Meltdown-PK
Intels aktuelle Skylake-SP-Prozessorgeneration beinhaltet Funktionen zur Zugriffssteuerung auf den Arbeitsspeicher auf Applikationsebene. Durch Schwachstellen in der „Out-of-Order-Execution“ ist es allerdings möglich, auch Speicherbereiche auszulesen, für die weder Lesen noch Schreiben erlaubt sein sollte.
Meltdown-BR
Eine Bound-Range-Exception (#BR) wird normalerweise genutzt, um den Zugriff auf Daten jenseits eines Listen- bzw. Array-Endes zu verhindern. Versucht zum Beispiel eine Anwendung auf das 21. Element einer Liste mit 20 Elementen zuzugreifen, so kommt es zu dieser Exception. Sollte diese Exception allerdings im Rahmen einer „Out-of-Order-Execution“ erfolgen, so findet die Behandlung der Exception zu spät statt und erlaubt über einen Seitenkanal das Auslesen von Daten jenseits des Listenendes. Dies ist ähnlich zu Spectre-PHT und wurde ursprünglich als Spectre-Variante identifiziert, allerdings findet hier keinerlei Nutzung von Speculative Execution statt. Auch hier können eigentlich für einen Angreifer nicht zugängliche Daten ausgespäht werden.
2.4 NetSpectre – Ausnutzen von Spectre über das Netzwerk
Eine der ersten Fragen, die sich bei Entdeckung einer neuen Sicherheitslücke stellt, ist die Ausnutzung über das Netzwerk, da sich damit die Angriffsfläche deutlich erhöht. Entsprechend stellte sich diese Frage auch bei Bekanntwerden von Spectre. Forscher haben im Juli letzten Jahres einen Artikel veröffentlicht ( [4]), in dem genau dieses Szenario untersucht und eine Möglichkeit zur Ausnutzung von Spectre über ein Netzwerk gezeigt wird.
Es ergeben sich dabei glücklicherweise eine Reihe von Anforderungen und Einschränkungen, die eine einfache Ausnutzung deutlich erschweren. Zu den Anforderungen gehören:
- Das Vorhandensein und die Ausführung einer angreifbaren CPU-Instruktionsfolge beim Empfangen eines Paketes, die ein Ausnutzen der ursprünglichen Spectre-Lücke ermöglicht. Diese Instruktionsfolge muss sich in einer realen Umgebung an irgendeiner Stelle in einem Treiber oder im Netzwerk-Stack des Betriebssystems befinden. Ein Beispiel für eine Instruktionsfolge ist die Überprüfung einer Array-Länge, wobei die Abfrage vom Angreifer manipulierbar sein muss. Zum Beispiel muss bei der Code-Abfolge
if (x < bitstream_length)
if (bitstream[x])
flag = true
„x“ vom Angreifer kontrollierbar sein, um die spekulative Ausführung zu trainieren und bei Erfolg „x“ auf den gewünschten Wert zu ändern.
- Es muss ebenso wie für den Empfang des Pakets eine Instruktionsfolge vorhanden sein, die die Auswirkungen von Spectre, zum Beispiel eine Zeitverzögerung durch das Cache-Verhalten, auf Netzwerk-Ebene an den Angreifer über das Netzwerk zurückmeldet. Typische Beispiele hierfür sind Verzögerungen in der Antwortzeit von Paketen.
- Der Angreifer muss die Möglichkeit haben, eine große Anzahl von Paketen an das Ziel zu schicken und die Antworten zu beobachten, da die Antwortzeiten nur über sehr viele Pakete gemittelt den Inhalt der zu extrahierenden Speicheradresse(n) mit ausreichender Sicherheit preisgeben. Diese Anforderung wird dadurch vereinfacht, dass die große Anzahl von Paketen nicht in kurzer Zeit übermittelt werden muss, sondern über einen beliebig langen Zeitraum verteilt werden kann.
Als maßgebliche Einschränkungen müssen hier einerseits die sehr geringe Bandbreite genannt werden, da die Informationen nur Bit-weise übertragen werden können und andererseits der starke Einfluss der zwischen Angreifer und Ziel befindlichen Netzwerk-Komponenten. Prinzipiell ist dieser Angriff nur dann möglich, wenn sich Angreifer und Ziel im selben Layer-2-Netzwerk befinden.
2.5 Spoiler
Anfang 2019 wurde eine neue Lücke in Intel-CPUs entdeckt ( [5]) die die Zuordnung zwischen dem Adressraum einer Anwendung (Virtual Address Space) und dem physischen Adressraum (Physical Address Space) des Hosts preisgeben kann. Damit ist es möglich, den genauen Standort der Daten einer Anwendung auszuspionieren. Dies ist für sich genommen kein sinnvoller Angriffsvektor, kann aber in Verbindung mit dem sog. Rowhammer-Angriff zur Modifikation von Daten in beliebigen Anwendungen genutzt werden.
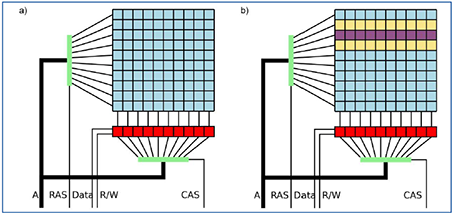
Abbildung 3: Aufbau eines Arbeitsspeichermoduls (a) und Angriff auf eine „Row“ (violett) durch schnelle Änderung der benachbarten Rows (gelb) (b, [6])
Rowhammer – eine kurze Einführung
Bereits 2014 haben Sicherheitsforscher ( [3]) eine Möglichkeit gefunden, Bits im Arbeitsspeicher zu verändern. Dazu wurde die Unterteilung des (physischen) Arbeitsspeichers in Reihen (englisch: „Rows“) ausgenutzt und die Tatsache, dass jede Row regelmäßig erneuert werden muss, da Arbeitsspeicher flüchtig ist. Leert man nun den Cache und greift man nun sehr häufig schreibend (mehrere Millionen Mal pro Sekunde) auf eine oder beide benachbarte Reihen einer Zielreihe zu, so kann man reproduzierbar einzelne Bits in der Zielreihe modifizieren, wie in Abbildung 3 dargestellt. Selbst Schutzmechanismen wie ECC (Error-correcting Code, das Erkennen und wenn möglich Beheben von Bitfehlern im Arbeitsspeicher) bieten hier keinen ausreichenden Schutz.
Spoiler und Rowhammer – ein tolles Paar
Kombiniert man nun die Informationen, die man durch Spoiler erhalten hat mit einem Rowhammer-Angriff, so kann man die Speicherbereiche einer Ziel-Anwendung modifizieren und nahezu beliebigen Code unterschieben.
Gegenmaßnahmen sind zum jetzigen Zeitpunkt nicht bekannt.

Teile diesen Eintrag