Prozessoren – das Herz unserer modernen Informationsgesellschaft – werden seit Jahrzehnten immer schneller. In den letzten vier Jahrzehnten hat sich die Performance pro Prozessor um einen Faktor 100.000 gesteigert. Die Steigerung der Leistung eines einzelnen Prozessorkerns sowie die Anzahl der Prozessorkerne ist in Abbildung 1 dargestellt ([1]). Dabei gelten als Prozessor einer oder mehrere verbundene „Dies“ mit einem oder mehreren Prozessorkernen, die auf einem einzelnen Prozessorsockel verbaut sind. Hierbei haben verschiedene Ansätze zur Steigerung der Leistung beigetragen. In einigen Bereichen ist die Grenze des physikalisch und ökonomisch Sinnvollen bereits erreicht, in anderen Bereichen sehen Experten noch viel Potential.
Ein Nebeneffekt der vielen verschiedenen Ansätze zur Performancesteigerung ist die steigende architektonische Komplexität der CPUs. CPUs bestehen heute aus wesentlich mehr Komponenten als noch vor 20 Jahren. Diese gesteigerte Komplexität führt aber unausweichlich auch zu einer höheren Fehleranfälligkeit. So wurden Fehler bereits 1994 in den ersten Intel Pentium Prozessoren gefunden (FDIV- und F00F-Bugs).
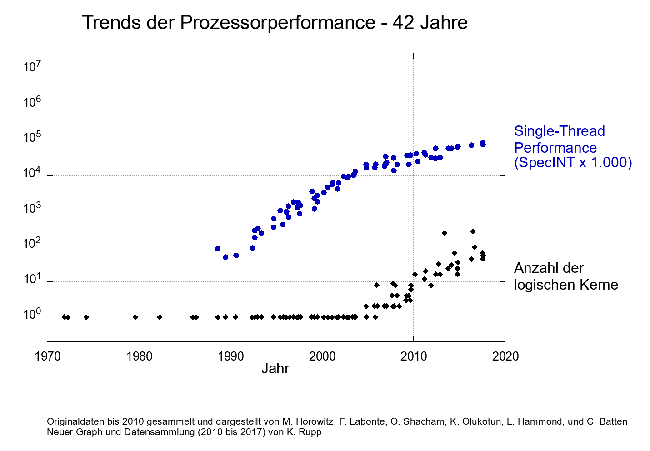
Abbildung 1: Prozessorleistung seit 1970
Im Januar hat das Bekanntwerden der Sicherheitslücken „Spectre“ und „Meltdown“ für großes Aufsehen gesorgt und uns allen schmerzlich klargemacht, welche Konsequenzen ein Fehler in modernen Prozessorarchitekturen haben kann. Das grundlegende Problem betrifft nicht einen einzelnen Hersteller oder ein einzelnes Produkt, sondern einen Kernbestandteil moderner CPUs, ob in Desktop-Systemen, Servern, Netzwerkkomponenten, Tablets oder Smartphones.
Auf der anderen Seite bemühen sich die Prozessorhersteller darum, zusätzliche Funktionen in ihre Prozessoren einzubauen, um die Nutzung auch in wenig vertrauenswürdigen Umgebungen wie der Cloud abzusichern.
Dieser Artikel beschäftigt sich mit den beiden Seiten moderner CPU-Architekturen: Probleme durch komplexere Architekturen und integrierte Sicherheitsmaßnahmen sowie den möglichen Interaktionen zwischen beiden Seiten.
1. Grundlagen moderner CPUs
Um zu verstehen, was genau Spectre und Meltdown so gefährlich macht, müssen wir zunächst die Grundlagen aktueller CPUs betrachten. Dieser Abschnitt wird sowohl die allgemein bekannten Grundlagen moderner Prozessorperformance als auch die weniger bekannten betrachten. Insbesondere letztere haben weitreichenden Einfluss auf die Funktionsweise eines Prozessors und bilden die Grundlage für Spectre und Meltdown.
1.1 Die bekannten Performance-Grundlagen – Taktrate und Multi-Core
Die wohl bekanntesten Techniken zur Erhöhung der Performance sind die Taktrate und die Anzahl der CPU-Kerne. Diese sind auch daher so bekannt, da sie in Produktwerbungen und technischen Spezifikationen sehr prominent platziert sind.
Dabei ist gerade die Taktrate ein schon recht lange ausgereizter Bereich. Bereits mit dem Intel Pentium IV von 2004 wurden Taktraten von 4 GHz erreicht, und selbst die am höchsten getakteten heutigen CPUs erreichen nur bis zu 4,5 GHz. Bei höheren Taktraten wird der Energieverbrauch der CPUs bei der momentan eingesetzten Silizium-basierten Technologie zu hoch und die Leistung pro Watt nimmt stark ab.
Als sich abzeichnete, dass eine Erhöhung der Taktrate nicht mehr möglich ist, kam der zweite bekannte Faktor ins Spiel: Es wurden mehrere CPU-Kerne auf einem Sockel betrieben und die Multi-Core-CPUs waren geboren. Die Steigerung der Kernanzahl schreitet bis heute fort und 32-Kern-CPUs sind im Server-Bereich verfügbar. Zwar sind auch hier bei steigender Zahl der Kerne Anpassungen an der Architektur notwendig, speziell um die Kommunikation zwischen Kernen effizienter zu gestalten, aber das Potential ist hier noch nicht ausgeschöpft. So gibt es im Bereich der Forschung und Entwicklung bereits Tests mit mehr als 100 Kernen pro Sockel.
1.2 Die weniger bekannten Funktionen: Fortgeschrittene Funktionsblöcke, Out-of-Order-Execution und Speculative Execution
Die weniger bekannten, aber für moderne CPUs mindestens genauso wichtigen Funktionen betreffen die Architektur jedes einzelnen CPU-Kerns. So gibt es in modernen CPUs diverse Funktionsblöcke, die für Spezialoperationen notwendig sind. Neben den schon lange vorhandenen Blöcken, beispielsweise für Ganzzahl- und Gleitkomma-Operationen, gibt es für einige häufige (Software-)Funktionen mittlerweile eigene Blöcke innerhalb der CPU; darunter fallen beispielsweise:
- Verschlüsselungsoperationen, z. B. für Festplattenverschlüsselung
- Vektoroperationen, die identische Operationen auf mehrere Datensätze gleichzeitig anwenden können
- Speichercontroller, die den Zugriff auf den RAM beschleunigen
Ebenso befindet sich heutzutage die Anbindung an externe Anschlüsse, wie PCI Express, Ethernet oder USB direkt in der CPU.
Ein schon in den 1980er Jahren absehbares Problem war, dass die Prozessorperformance viel schneller wuchs als die Geschwindigkeit des angebundenen Arbeitsspeichers. So steht dem Performance-Gewinn der CPUs um einen Faktor 100.000 eine Geschwindigkeitserhöhung des Arbeitsspeichers um einen Faktor 10 entgegen. Ohne Tricks würde eine CPU bei Operationen mit Speicherzugriff also mehr als 99% der Zeit darauf warten, Daten aus dem Arbeitsspeicher zu laden. Hierzu wurden und werden immer größere Caches in die CPUs eingebaut, die einen Teil der geladenen Daten aus dem Arbeitsspeicher vorhalten. Diese verfügen über verschiedene Größen und Geschwindigkeiten, wobei schnellerer Cache aufgrund der höheren Kosten kleiner ausfällt als langsamer Cache.
Ein weiterer Performance-Gewinn ist möglich, indem die CPU-Instruktionen nicht in der vorgegebenen Reihenfolge abgearbeitet werden, sondern so, dass möglichst keine Taktzyklen verschwendet werden und alle Funktionsblöcke ausgelastet werden. Dabei muss aber sichergestellt werden, dass die Ergebnisse der Instruktionen auch in veränderter Reihenfolge identisch sind. Auch muss der ursprüngliche Zustand vor der Ausführung wiederhergestellt werden, falls ein Fehler (sog. Exception) auftritt. Hierzu wurde bereits Mitte der 1990er Jahre die „Out-of-Order Execution“ eingeführt. Das Prinzip ist in Abbildung 2 dargestellt. Es können in diesem Beispiel alle Funktionsblöcke im ersten Taktzyklus gleichzeitig genutzt werden und es werden insgesamt nur zwei Taktzyklen statt vier benötigt. Aufgrund der Komplexität der notwendigen Logik innerhalb des Prozessors ist diese Funktion aber zunächst nicht flächendeckend eingesetzt worden. Stattdessen wurde diese Technik in einigen Server-CPUs sowie in Intels Pentium Pro und AMDs K5-Prozessoren eingesetzt. Aber selbst im Serverbereich gab es einige CPUs, in denen zunächst auf diese Funktion verzichtet wurde, wie der Intel Itanium oder IBM POWER6. Heutzutage besitzen alle gängigen CPU-Architekturen diese Funktion.
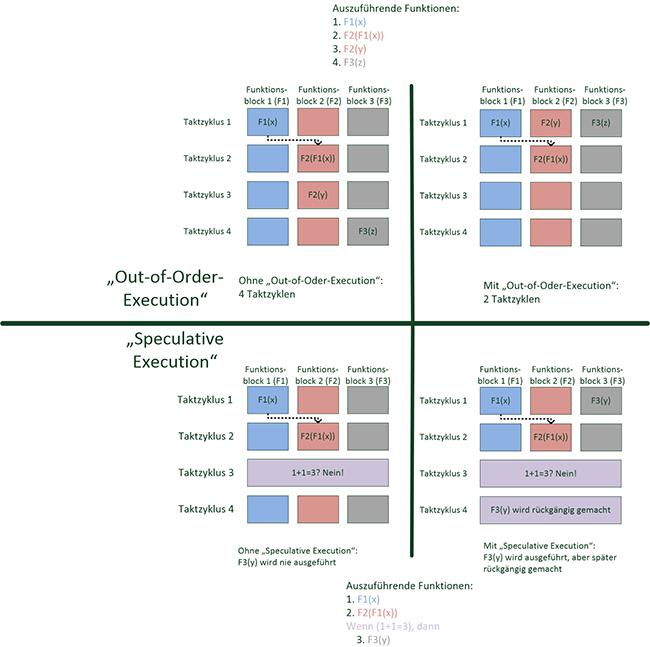
Abbildung 2: Funktionsprinzip „Out-of-Order-Execution“ und „Speculative Execution“
Ebenfalls mit dem Pentium Pro hat Intel die sogenannte „Speculative Execution“ eingeführt, wie sie in Abbildung 2 dargestellt ist. Diese behebt folgendes Problem: Sobald eine Entscheidung in einem Programm gefällt werden muss (beispielsweise eine if-Abfrage), kann der Prozessor erst dann wissen, welchen Weg er einschlagen muss, wenn er das Ergebnis der Abfrage kennt. Hier setzt die Speculative Execution an: Der Prozessor trifft eine Abschätzung, welcher Zweig des Programms am wahrscheinlichsten ist und führt, beispielsweise beim Warten auf Daten aus dem Arbeitsspeicher, diesen Zweig schon einmal aus; wenn das Ergebnis der Abfrage zu einem späteren Zeitpunkt bekannt ist und der vermutete Pfad der richtige war, so ist dieser zumindest teilweise, im Optimalfall vollständig, abgearbeitet und der Prozessor spart viele Taktzyklen. Sollte der Prozessor falsch geraten haben, so ist der Performanceverlust gering; der ursprüngliche Zustand vor der Verzweigung wird analog zur Out-of-Order-Execution wiederhergestellt und das Programm wird so ausgeführt, wie es vorgesehen ist. Dabei kann eine CPU auch anhand vorheriger Ausführungen lernen, ob ein bestimmter Pfad häufig genutzt wird und dies bei zukünftigen Ausführungen berücksichtigen. Ein direkter Vergleich zwischen einem Intel Pentium MMX 200 (ohne Out-of-Order-Execution und Speculative Execution) und einem Pentium Pro 200 ergibt einen Performance-Zuwachs durch Out-of-Order Execution und Speculative Execution von ca. 46% ([2]). Eine ausführliche Beschreibung der Intel-Prozessorarchitektur im Zusammenhang mit Intel SGX findet sich in [3].
2. Spectre und Meltdown – wie moderne Features zum Sicherheitsproblem werden
Die im letzten Kapitel dargestellten Funktionen jenseits der Erhöhung der Taktrate und Kernanzahl haben dazu geführt, dass heutige CPUs um ein Vielfaches komplexer geworden sind. So ist die Zahl der Transistoren um viele Größenordnungen gestiegen. Diese Komplexität und die Tricks der Hersteller, die Performance zu erhöhen, führten zu den im Januar bekanntgewordenen Sicherheitslücken Spectre ([4]) und Meltdown ([5]), die in diesem Kapitel genauer beschrieben werden sollen. Außerdem ist Anfang Mai dieses Jahres eine Reihe weiterer Sicherheitslücken aufgetaucht, die als „Spectre Next Generation“ ([6]) bezeichnet werden. Allen diesen Lücken liegen Out-of-Order-Execution und Speculative Execution zugrunde, die auf unterschiedliche Art und Weise ausgenutzt werden.
2.1 Spectre
Die Sicherheitslücke Spectre ([4]), welche einem Programm ermöglicht, eigentlich unzugängliche Speicherbereiche anderer Programme auszulesen, macht sich fehlende Sicherheitsüberprüfungen bei der Speculative Execution zunutze. Grob beschrieben erfolgt ein Angriff wie folgt: Zunächst werden die Caches der CPU geleert, was zu Optimierungszwecken von jedem Programm ausgelöst werden kann. Damit wird sichergestellt, dass alle Daten aus dem (langsamen) Arbeitsspeicher geladen werden müssen. Dann wird bei einem Angriff per Spectre die CPU darauf trainiert, eine gewisse Entscheidung im Programm des Angreifers zu erwarten, in der abhängig von der Entscheidung ein Speicherzugriff erfolgt. Im Allgemeinen wird bei dieser Abfrage vom Programm überprüft, ob der Speicherzugriff erlaubt ist. Sobald ausreichend wahrscheinlich ist, dass der Prozessor von einer positiven Abfrage ausgeht, wird die entsprechende Variable sowohl in der Abfrage als auch für den Speicherzugriff so manipuliert, dass auf einen eigentlich verbotenen Speicherbereich zugegriffen wird. Zwar verwirft die CPU die Daten, sobald klar ist, dass eine falsche Entscheidung getroffen wurde, aber bleiben ggf. die hierfür gelesenen Daten im Cache der CPU. Wenn man nun versucht, diesen Wert noch einmal zu lesen (erfolgreich oder nicht), so ist die Ladezeit wesentlich geringer, da die Daten im Cache liegen, was sie eigentlich nicht sollten. Durch speziell konstruierte Speicherzugriffe ist es möglich, anhand der verringerten Zugriffszeiten den eigentlichen Inhalt des Caches zu lesen, der durch die spekulative Ausführung modifiziert wurde. Hierdurch kann Stück für Stück der Speicher von „fremden“ Programmen ausgelesen werden. Dies ist kein schneller Vorgang, aber speziell für das Auslesen von AES-Verschlüsselungs-Keys, Passwörter oder den privaten Teil eines Public/Private-Keypaars müssen nur wenige Kilobyte an Daten ausgelesen werden. Somit können sehr sensible Daten ausgelesen werden, die einem Angreifer weitreichende Möglichkeiten geben.
Diese Sicherheitslücke betrifft nahezu jeden der großen CPU-Hersteller: Intel, AMD, IBM und ARM. Dies verdeutlicht, dass es sich hier um ein Problem in der modernen CPU-Architektur handelt und nicht um das Problem eines einzelnen Herstellers. Zwar sind von den Herstellern erste Patches auf Hardwareebene bereitgestellt worden, aber es sind seit der Veröffentlichung dieser Patches bereits neue Wege gefunden worden, diese architekturbedingte Lücke auszunutzen.
Aufgrund der Kritikalität dieser Sicherheitslücke hat sich Microsoft sogar bereit-erklärt, die notwendigen Patches, die die eigenen Produkte eigentlich nicht betreffen, über den Update-Mechanismus des Betriebssystems bereitzustellen.
2.2 Meltdown
Die parallel zu Spectre veröffentlichte Meltdown-Sicherheitslücke ([5]) nutzt im Gegensatz zu Spectre die Out-of-Order-Execution aus, um auf den eigentlich geschützten Speicherbereich des Kernels zuzugreifen. Ein Angreifer kann in einem Programm einen Speicherzugriff nach einer eigentlich fehlerhaften Anweisung, welche eine Exception auslöst, platzieren. Durch die Out-of-Order-Execution kann es aber dennoch sein, dass dieser Speicherzugriff – zumindest temporär – ausgeführt wird, während die Exception verarbeitet wird. Zwar wird bei Bemerken der Exception der Speicherzugriff wieder verworfen und ggf. das Programm beendet, die gelesenen Daten finden sich aber – wie bei Spectre – im CPU-Cache und können über einen Seitenkanal ausgelesen werden.
Dabei ist wichtig, dass die o.g. Speicherzugriffe nur im Kontext des aktuellen Programmes stattfinden können und kein (direktes) Auslesen fremder Speicherbereiche möglich ist. Diese Limitierung lässt sich durch eine Eigenheit vieler moderner Betriebssysteme umgehen:
Der Speicherbereich des Kernels wird üblicherweise aus Performancegründen direkt im Speicherbereich eines Programms verfügbar gemacht und im Kernelspeicher ist üblicherweise der gesamte (genutzte) physische Arbeitsspeicher eines Systems sichtbar. Zwar existieren eigentlich Sicherheitsmechanismen, die einen Zugriff auf unerlaubte Bereiche unterbinden sollen. Diese Mechanismen werden aber – ähnlich wie bei der Speculative Execution und Spectre – durch die Out-of-Order-Execution umgangen.
Die ursprüngliche Veröffentlichung ([5]) hat für das Auslesen des Kernelspeichers eine Bandbreite von ca. 500 kB/s erreicht.
Gegenmaßnahmen gegen Meltdown können zu großen Teilen im Betriebssystem greifen. Im Linuxkernel beispielsweise gibt es bereits Patches, die das Übertragen von Kernelspeicher in jedes Programm minimieren und somit einen Angriff erheblich erschweren. Auch hier ist allerdings nicht sicher, ob diese Mechanismen ausreichen und wie lange es ggf. dauern wird, bis neue Angriffe gefunden werden, die diese Sicherheitsmechanismen aushebeln.
Meltdown ist – sofern man dies momentan beurteilen kann – nur für Intel relevant. Die Entdecker dieser Lücke waren nicht in der Lage, diese bei CPUs von ARM oder AMD zu reproduzieren. Veröffentlichungen der Hersteller haben dies bestätigt.
2.3 Spectre-NG – erste Informationen
Als Erweiterung zu Spectre sind am 3. Mai erste Informationen zu weiteren Spectre-basierten Lücken namens Spectre Next Generation bekannt geworden ([6]). Diese insgesamt 8 Lücken werden teilweise als kritisch eingestuft, aber weitergehende Informationen sind nur teilweise verfügbar. Als besonders kritisch wird dabei eine Lücke eingestuft, die es im Virtualisierungsumfeld ermöglicht, von einer virtuellen Maschine auf den Speicher einer anderen virtuellen Maschine zuzugreifen, ohne dass der Hypervisor Einfluss darauf hat.
Die ersten weitergehenden Informationen beziehen sich leider nur auf zwei der acht Lücken, von denen beide nur als mittelschwer eingeordnet werden. Diese werden allgemein als „Spectre V3“ und „Spectre V4“ bezeichnet. Zu diesen Lücken sind bereits Patches auf Prozessorebene verfügbar; weitere Patches auf Betriebssystemebene sind in Arbeit und beispielsweise im Linuxkernel bereits vorhanden. Die Aufnahme der Patches in verschiedene Linux-Distributionen ist in vollem Gange. Zu den übrigen Lücken stehen momentan noch keine neuen Informationen zur Verfügung. Eine Übersicht der betroffenen Hersteller und Informationen zu Lücken und Patches sind unter [7] zusammengefasst.
3. Sicherheitsmechanismen moderner CPUs
So katastrophal die Situation aufgrund der gefundenen Sicherheitslücken auch aussehen mag, so gibt es auch starke Bemühungen der CPU-Hersteller, die Sicherheit ihrer CPUs zu verbessern. Insbesondere für nicht vertrauenswürdige Umgebungen wurden in den letzten Jahren Funktionen in die CPUs integriert, die es dem Nutzer trotzdem ermöglichen, vertrauliche Daten sicher zu verarbeiten. Eine der wichtigsten Einsatzmöglichkeiten ist dabei die Nutzung der Cloud. Hier stellt sich für Nutzer und Entscheidungsträger die Frage: Wie kann ich sicher sein, dass nicht sogar ein anderer Nutzer oder der Cloud-Anbieter selbst meine Daten abgreift und daraus Kapital schlägt?
Zwar gibt es mit der sogenannten homomorphen Verschlüsselung ([8]) Möglichkeiten, dies in Software zu realisieren. Allerdings ist die Performance immer noch um viele Größenordnungen schlechter als bei der Verarbeitung von unverschlüsselten Daten.
In diesem Kapitel werden zwei für das Rechenzentrum und den Cloud-Betrieb relevante Technologien der Hersteller Intel und AMD beschrieben, die das gleiche Ziel verfolgen, aber unterschiedliche Ansätze nutzen.
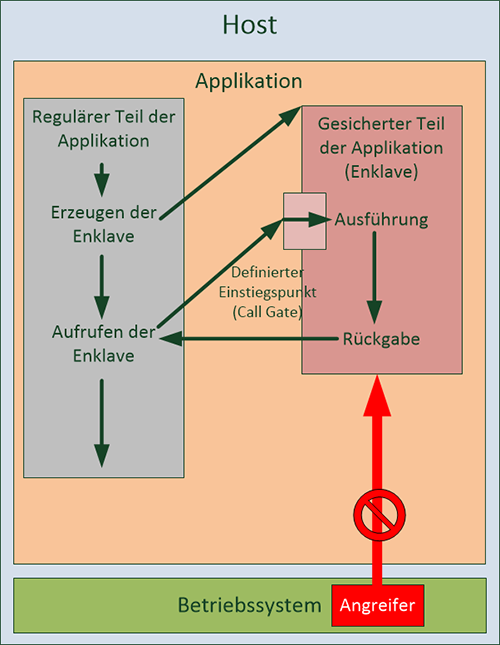
Abbildung 3: Funktionsweise Intel SGX
3.1 Intel SGX
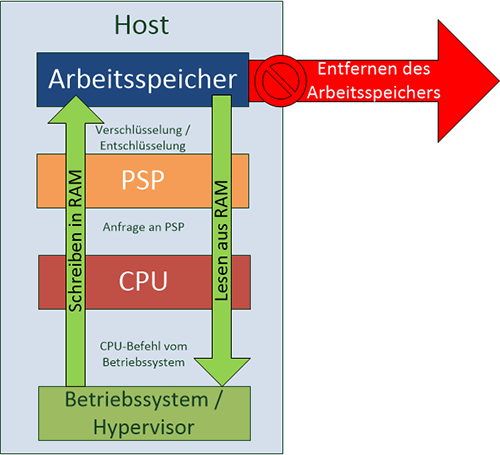
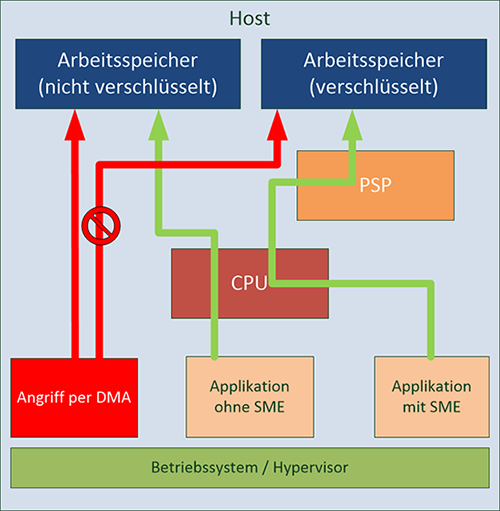
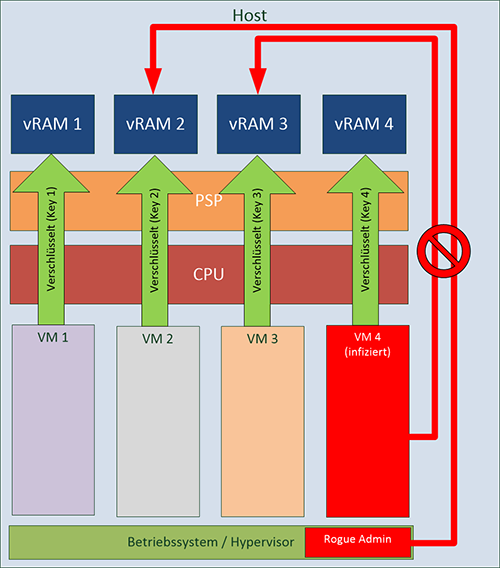
Intel hat im Jahr 2014 die „Software Guard Extensions“ – kurz SGX – eingeführt. Dabei setzt Intel auf eine Absicherung von Programmen gegeneinander. Ein Programm kann eine sog. „SGX Enclave“ erzeugen, in der vertrauliche Daten verarbeitet werden können. Der für die Enklave genutzte Arbeitsspeicher wird dabei vollständig verschlüsselt und erst innerhalb der CPU entschlüsselt. Damit ist ein Zugriff auf den von der Enklave genutzten Speicher nicht direkt möglich. Der dabei verwendete Schlüssel kann nicht vom Betriebssystem oder von DMA-fähiger Hardware ausgelesen werden und dies wird auf verschiedenen Ebenen vom Prozessor sichergestellt. Eine Nutzung der Enklave kann nur über klar definierte Ein- und Ausgangspunkte erfolgen, und diese Punkte sind nur für die Applikation zugänglich, die die Enklave erzeugt hat. Eine grafische Darstellung findet sich in Abbildung 3.
Um sicherzustellen, dass der Betreiber der Infrastruktur weder das zugrundeliegende Betriebssystem noch das SGX-fähige Programm manipuliert, findet beim Einrichten der Enklave eine sog. „Software Attestation“ statt. Dabei wird einerseits die Integrität der Software überprüft, andererseits führt die Verschlüsselung zu einem Schutz vor bösartigen Betreibern oder Mitarbeitern des Betreibers.
Ein Nachteil dieser Technologie ist die wahrscheinlich geringere Performance von Code innerhalb einer Enklave. Zwar gibt Intel selbst keine genauen Informationen zum Einfluss auf die Performance. Allerdings wird dazu geraten, nur kleine Teile eines Programms in die Enklave auszulagern, was ein deutlicher Hinweis auf Performanceeinbußen ist. Genaue Informationen zum Einfluss auf die Performance sind leider nicht öffentlich verfügbar, da die Nutzung von SGX momentan einen speziellen Vertrag zwischen dem Entwickler und Intel voraussetzt. Erst dadurch ist es möglich, die eigene Software um SGX zu erweitern und die eigenen Enklaven vom Prozessor genehmigen zu lassen.
Insgesamt ist der Ansatz, den Intel für SGX gewählt hat, aber als positiv für verschiedene Szenarien zu bewerten, in denen geringe Mengen vertraulicher Daten auf einem System mit mehreren Benutzern verarbeitet werden müssen. Diese Absicherung gegeneinander kann die Sicherheit mehrerer Nutzer innerhalb eines einzigen Betriebssystems oder mehrerer virtualisierter Betriebssysteme mit je einem Nutzer auf einem physischen Host erhöhen. Beispiele für SGX-fähige Software sind VPN-Server und –Clients oder sonstige Verschlüsselungstools, bei denen die Sicherheit von der Vertraulichkeit von Zertifikaten oder Verschlüsselungs-Keys abhängt.