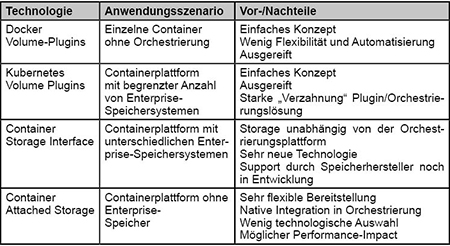
Der ursprüngliche Gedanke bei der Entwicklung von Containern war, dass sie prinzipiell flüchtig sind. Bei Bedarf werden neue Instanzen gestartet, wenn sie nicht mehr benötigt werden verschwinden sie wieder zusammen mit möglichen Veränderungen in den Daten. Außerdem sollen Container möglichst „schlank“ sein und den Host so wenig wie möglich belasten. Auf diesem Prinzip basiert auch der Aufbau eines Container-Dateisystems. Wie in Abbildung 1 dargestellt, werden Container aus einem Image abgeleitet. Dieses Image, im Bild als Beispiel das Ubuntu 15.04 Image, ist aus verschiedenen Read-Only-Schichten aufgebaut, die während seiner Erzeugung gestapelt wurden.
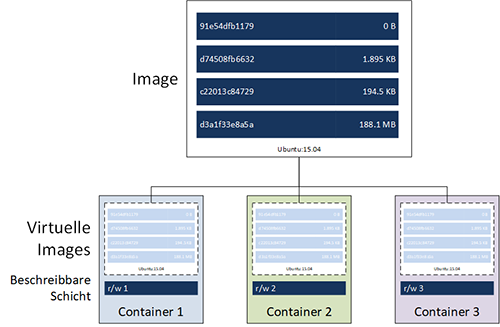
Abbildung 1: Ableitung von Containern aus einem Image. Jeder Container verfügt lediglich über eine möglichst dünne beschreibbare Schicht, die zum tatsächlichen Speicherbedarf beiträgt
Images können sowohl aus öffentlichen (z.B. Docker Hub) oder privaten (z.B. Red Hat Quay, Google Container Registry) Registries mittels des „Pull“ Befehls bezogen werden. Sie werden lokal auf dem Host gespeichert. Wird ein Container gestartet, leitet Docker ihn aus dem Basis-Image ab. Lediglich eine, möglichst kleine, beschreibbare Schicht wird genutzt um Daten zu verändern. Für einen laufenden Container wird also ausschließlich für diese Schicht auf dem Host Speicherplatz benötigt. Identische Container „teilen“ sich ein Ursprungsimage. Durch diesen Mechanismus kann also eine große Zahl von Containern auf einem Host betrieben werden, ohne viel Speicherplatz zu benötigen – natürlich unter der Voraussetzung, dass ausreichend CPU, GPU (Graphics Processing Unit) und Memory-Ressourcen verfügbar sind. Müssen während des Betriebs eines Containers Daten aus dem Image verändert werden, kopiert der Speichertreiber diese zunächst in die beschreibbare Schicht, ändert sie und speichert sie dort zwischen. Diese Technologie – auch als „Copy on Write“ bezeichnet – sorgt dafür, dass ein Großteil der Daten von Containern, die aus demselben Image abgeleitet werden, nur einmal gespeichert werden müssen. Im Prinzip ähnelt diese Art der Verringerung des benötigten Speicherplatzes also der Deduplizierung in Enterprise-Speichersystemen. Wenn aber z.B. zwei Container, die aus einem Basis-Image abgeleitet wurden, dieselben Daten verändern, werden diese zweimal gespeichert.
Das Stapeln von Dateisystemen mit einer dünnen beschreibbaren Schicht hat zwei entscheidende Nachteile: Zum einen erzeugt die Copy on Write Technologie einen nicht zu vernachlässigenden Overhead: Für jeden Schreibvorgang muss der Speichertreiber zunächst Schicht für Schicht nach der zu ändernden Datei suchen. Anschließend wird diese kopiert und verändert. Noch entscheidender – zumindest aus Sicht dieses Artikels – ist die Tatsache, dass die beschreibbare Schicht beim Stoppen eines Containers wieder verschwindet.
Die einfachste Möglichkeit diese Nachteile zu umgehen, ist das Mounten von lokalen Verzeichnissen innerhalb eines Containers. Wie in Abbildung 2 dargestellt können sowohl mehrere Container auf ein Verzeichnis zugreifen oder Verzeichnisse dediziert bereitgestellt werden.
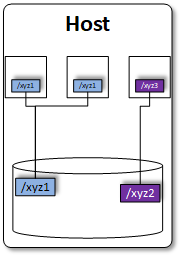
Abbildung 2: Mounten von lokalen Volumes in Container
Im Gegensatz zum in Abbildung 1 dargestellten Modell nimmt die Größe des Containers selbst bei der Veränderung von Dateien nicht zu. Das eingebundene Verzeichnis ist nicht Teil der beschreibbaren Schicht aus der Abbildung.
Für die Einbindung derartiger Verzeichnisse existieren drei verschiedene Varianten:
- Bind Mounts: Diese nutzen das Dateisystem des Hosts. Bind Mounts sind die am längsten verfügbare Möglichkeit, persistenten Speicher in Containern zu nutzen. Durch die direkte Einbindung in das Dateisystem des Hosts stellen Bind Mounts vergleichsweise hohe Leistungsfähigkeit bereit. Allerdings ist ihre Funktionalität im Vergleich zu Volumes stark eingeschränkt.
- Volumes: Volumes sind die von Docker bevorzugte Methode für die Nutzung von persistentem Speicher. Sie werden vollständig von Docker verwaltet. Daraus ergeben sich Vorteile wie der stabile Zugriff von mehreren Containern auf ein Verzeichnis oder die Verwaltung mittels der Docker API.
- tmpfs mounts: Diese Art von Verzeichnis ist nicht für die persistente Speicherung von Daten gedacht. Es wird ein Verzeichnis im Arbeitsspeicher des Hosts angelegt, das nicht Teil der beschreibbaren Schicht aus Abbildung 1 ist. Ein Anwendungsfall ist z.B. die vergleichsweise sichere Speicherung von sensiblen Daten außerhalb der Host-Festplatten. Im Vergleich zu den anderen beiden Varianten haben tmpfs-mounts zwei Einschränkungen: Zum einen sind sie nur innerhalb einer Linux-Umgebung verfügbar. Zum anderen können sie nicht von mehreren Containern gleichzeitig genutzt werden.
In Abbildung 3 sind die unterschiedlichen Varianten miteinander verglichen.
Abbildung 3: Unterschied zwischen bind mounts, volumes und tmpfs mounts bei Docker.
Docker Volume Plugin
Die bisher diskutierten Möglichkeiten zur Einbindung von persistentem Speicher haben sich lediglich auf die Nutzung der Festplatten von Hosts beschränkt. Obwohl z.B. mittels Volumes zwar die Daten auch auf entfernte Hosts ausgelagert werden können, fehlen Enterprise Features wie Snapshots zur Datensicherung oder Hochverfügbarkeit. Mit den bisher vorgestellten Technologien könnten diese lediglich genutzt werden, wenn die Festplatten der Docker Hosts bzw. die relevanten Verzeichnisse durch SAN-Speicher bereitgestellt werden.
Um die Funktionalität der Docker-Plattform durch externe Dienste zu erweitern, stehen sogenannte „Engine Plugins“ zur Verfügung, die als Images verteilt werden. Aktuell existieren Plugins für die Einbindung von Netzwerkfunktionen, für die Autorisierung und eben für persistenten Speicher als sogenannte „Volume Plugins“. Während für die Netzwerk- und Autorisierungsvarianten jeweils drei unterschiedliche Plugins genutzt werden können, gibt es für die Speicheranbindung über 20 Varianten. Diese reichen von solchen, die von Speicherherstellern entwickelt wurden (z.B. Nimble Storage Volume Plugin, HPE 3Pr Storage Plugin) bis hin zu Plugins der großen Cloud-Provider (z.B. Azure File Storage Plugin). Wie in Abbildung 4 dargestellt, wird das Plugin auf jedem Host der Docker Engine als Container „zur Seite gestellt“.
Nachdem das Plugin installiert ist, wird zunächst ein Volume erzeugt. Geschieht das z.B. in einer VMware vSphere-Umgebung, sowohl für klassischen als auch für vSAN-Speicher, ist lediglich folgender Befehl erforderlich:
docker volume create --driver= vsphere --name=MyVolume -o [optionale Parameter]
Je nach Plugin sind verschiedene Optionen wie Thin Provisioning, Replikation oder Deduplizierung verfügbar.
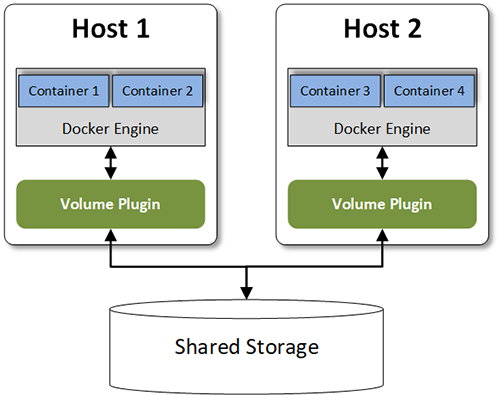
Abbildung 4: Anbindung von externem Speicher mit Volume Plugins
Die Einbindung von persistentem Speicher über Volume Plugin ist in Abbildung 5 dargestellt. Das Plugin stellt dem Docker-Daemon Verzeichnisse zur Verfügung, welche per Bind Mount (s.o.) im Container genutzt werden.
Beim Start des Containers wird das Verzeichnis über das –volume Flag im Container eingebunden.
Bewertungskriterien
Als Entscheidungshilfe für die Auswahl eines Plugins werden die Beispiele anhand der folgenden Kriterien miteinander verglichen:
Unterstützte Speicherumgebungen
Welche Speichersysteme können mit dem Plugin genutzt werden? Als Speichersysteme kommen sowohl zentrale Speicherlösungen wie z.B. SAN-Speicher in Frage als auch Software-Lösungen wie verteilte Dateisysteme oder Cloud Speicher. Dieses Kriterium ist relevant, wenn persistenter Speicher aus unterschiedlichen Quellen für Container genutzt werden soll.
Verfügbare Optionen
Kann der persistente Speicher z.B. durch Spiegelung um Hochverfügbarkeit ergänzt oder durch Deduplizierung effizienter genutzt werden? Dieses Kriterium ist relevant, wenn Speicher mit Enterprise-Features zum Einsatz kommen muss. Die verfügbaren Optionen hängen natürlich direkt von den Eigenschaften des Speichers ab.
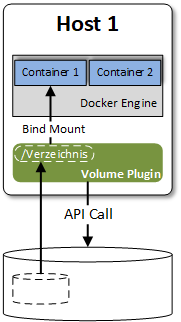
Abbildung 5: Einbindung von persistentem Speicher mittels Volume Plugin
Multi-Engine-Nutzung
Kann ein Volume von mehreren Docker Engines (z.B. auf verschiedenen Hosts oder innerhalb mehrerer VMs) gleichzeitig genutzt werden? Können Container z.B. nach einem Ausfall auf einem neuen Host wieder gestartet werden und von dort auf ihr ursprüngliches Volume zugreifen? Dieses Kriterium ist relevant, wenn Container in einem Hochverfügbarkeitscluster genutzt werden oder mehrere Container Teil einer Applikation sind und Zugriff auf dieselben Daten benötigen.
Zertifizierung für die Docker Enterprise Edition
Seit Mitte des Jahres 2018 ist die zweite Version der Docker Enterprise Edition verfügbar. Diese kommt vor allem dann zum Einsatz, wenn produktive Applikationen als Container betrieben werden. Unter anderem können die Hersteller von Plugins diese von Docker zertifizieren lassen. Im Rahmen der Zertifizierung werden die Plugins als Container verteilt. Diese werden u.a. darauf geprüft, ob sie anhand von Best-Practices erstellt wurden. Außerdem wird die API-Compliance getestet und ein Schachstellen-Scan durchgeführt. Dieses Kriterium ist relevant, wenn im Unternehmen die Docker Enterprise Edition zum Einsatz kommt bzw. geplant ist, diese einzusetzen.
Verfügbare Plugins
Wie bereits beschrieben, steht mittlerweile eine große Zahl an Plugins verschiedener Plugins zur Verfügung. Im Folgenden werden einige davon vorgestellt und in ihrer Funktionalität verglichen. Die in der Auflistung enthaltenen Beispiele stehen exemplarisch für OpenSource-Projekte zur Einbindung unterschiedlicher Backends (Rex-Ray), Plugins für die Nutzung von Cloud-Speicher (Cloudstor), Plugins innerhalb einer herstellerspezifischen Virtualisierungsumgebung (VDVS) und eine Speicherhersteller-spezifische Lösung (HPE 3Par Volume Plugin).
Cloudstor
Das Cloudstor-Plugin wurde von Docker selbst für Docker for Azure entwickelt. Primärer Einsatzzweck ist die Bereitstellung von Speicher innerhalb von Microsoft Azure und Amazon Web Services Public Clouds. Werden die dort verfügbaren Container-Dienste genutzt, steht das Cloudstor-Plugin in der Theorie automatisch zur Verfügung. Allerdings ist zu beachten, dass es sich hier um ein sehr neues Feature handelt, das seine Zuverlässigkeit erst noch nachweisen muss. (siehe Tabelle 1)
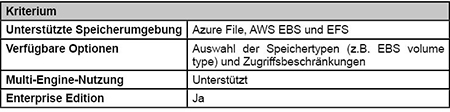
Tabelle 1: Cloudstor
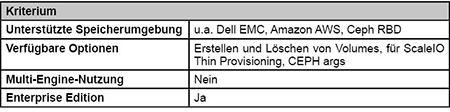
Tabelle 2: REX-Ray Plugin
REX-Ray Plugin
Haupt-Contibutor zur Entwicklung des REX-Ray Plugins ist der Speicherhersteller DellEMC ({code} by DellEMC). Eigentlich stellt REX-Ray eine Sammlung von verschiedenen Plugins für unterschiedliche Speicherumgebungen dar. So werden z.B. das DellEMC ScaleIO- und das Isilon-Speichersystem unterstützt. Darüber hinaus können u.a. auch Cloud-Speicher (Amazon EBS, EFS und S3FS, Google GCE Persistent Disk) eingebunden werden. (siehe Tabelle 2)
vSphere Docker Volume Service
Über den vSphere Docker Volume Service (VDVS) kann persistenter Speicher, der an eine vSphere-Umgebung angebunden ist, von Containern genutzt werden. Das gilt sowohl für VMware-eigenen Speicher (vSAN) als auch für externen Speicher, der mittels iSCSI oder Fibre Channel per VMFS verfügbar gemacht wird. Außerdem kann NAS-Speicher genutzt werden, der mittels NFS angebunden ist. (siehe Tabelle 3)
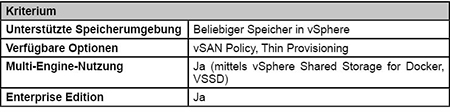
Tabelle 3: vSphere Docker Volume Service
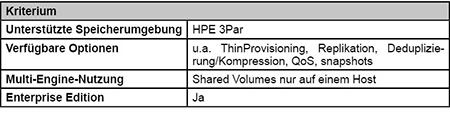
Tabelle 4: HPE 3Par Volume Plugin
HPE 3Par Volume Plugin
Das HPE 3Par Volume Plugin wurde für eine spezielle Familie von Enterprise-Speichersystemen entwickelt. Dementsprechend groß ist das verfügbare Featureset. So können z.B. auch die Replikation zwischen Knoten des Speichersystems oder Quality of Service Parameter in den Optionen des Volume Create Befehls konfiguriert werden. (siehe Tabelle 4)
Fazit
Mittlerweile steht eine große Anzahl von verschiedenen Möglichkeiten zur Einbindung von persistentem Speicher in Container zur Verfügung. Je nachdem, ob eine vorhandene Speicherlösung genutzt werden soll oder z.B. Speicher in der Pu-blic-Cloud genutzt wird, muss das entsprechende Plugin gewählt werden. Damit steht dem Betrieb von Applikationen, die stateful sind, in Containern an dieser Stelle prinzipiell nichts mehr im Wege.
Container-Orchestrierung
Eine der größten Stärken von Containern ist die Möglichkeit zum schnellen Erzeugen und Abschalten von Instanzen. Dies kann z.B. aufgrund von veränderter Last oder auch nach Ausfällen von einzelnen Hosts erforderlich sein. Diese Stärken spielen vor allem dann eine Rolle, wenn Container in produktiven IT-Umgebungen eingesetzt werden. In diesem Umfeld ist die verlässliche Orchestrierung von Containern ein wesentlicher Bestandteil. Sollen Container mit Orchestrierung stateful betrieben werden, spielt die automatisierte Bereitstellung von persistentem Speicher eine entscheidende Rolle.
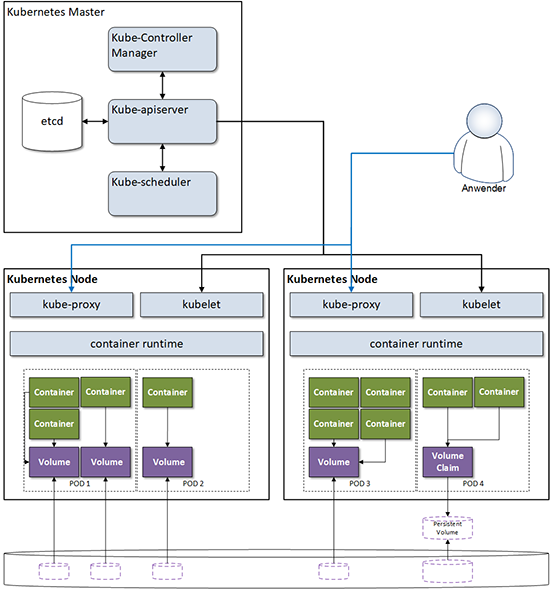
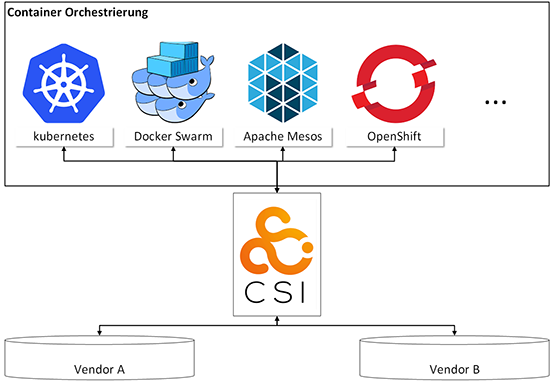
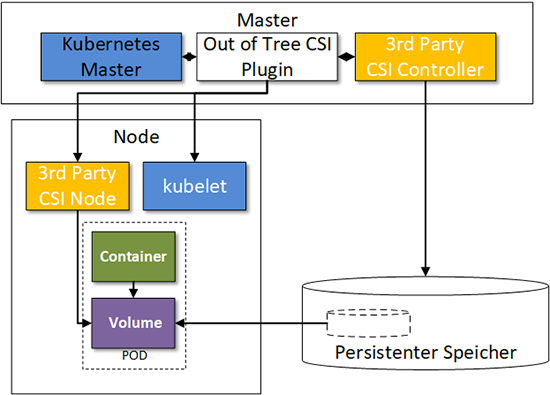
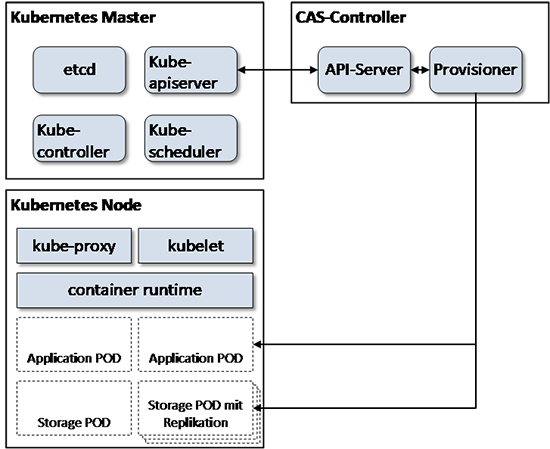
Bei den Container-Orchestrierungssystemen (CO) hat das ursprünglich von Google entwickelte und mittlerweile unter der Schirmherrschaft der Cloud Native Computing Foundation (CNCF) entwickelte Kubernetes den mit Abstand größten Marktanteil. Dieser verfestigt sich auch durch die Verfügbarkeit von Kubernetes bei den wichtigsten Cloud Anbietern (AWS EKS, Azure AKS oder Google GKE) oder durch die verstärkte Präsenz von VMware, die z.B. durch die Übernahme des Kubernetes-Consulting-Unternehmens heptio deutlich wird. Daher liegt der Fokus der weiteren Betrachtung auf Kubernetes.