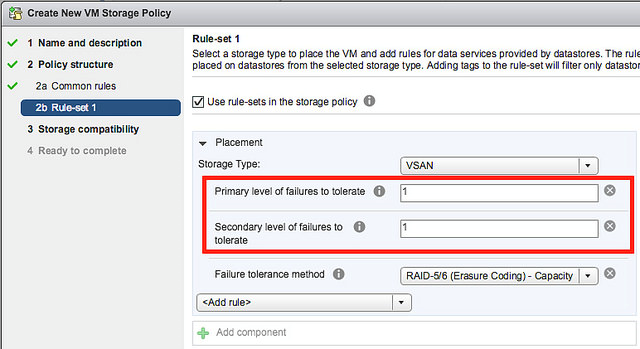
Fehlertoleranz
Die wichtigsten Parameter zur Definition des gewünschten Grads an Fehlertoleranz (siehe Abbildung 5) sind:
- Number Of Failures To Tolerate (FTT)
Diese Policy bestimmt die Anzahl von Fehlern, die auf Cluster-Ebene toleriert werden können ohne den Zugriff auf Daten zu verlieren. Der Default-Wert ist 1, der Parameter kann auf Werte zwischen 0 und maximal 3 gesetzt werden.
Realisiert wird diese Fehlertoleranz selbstverständlich über Datenredundanz, das heißt der Parameter bestimmt auch, wie oft identische Daten im Cluster vorgehalten werden, und hat damit maßgeblichen Einfluss auf die notwendige Brutto-Gesamtkapazität im Cluster.
- Fault Tolerance Method
Mögliche Werte sind „RAID-1 mirroring“ und „RAID-5/6 erasure coding“, neben „keine Fehlertoleranz“, Default ist „RAID-1“.
Mit RAID-1 werden maximal drei Fehler im Cluster aufgefangen, die notwendige Anzahl verfügbarer Hosts (bzw. Fehlerdomänen) berechnet sich aus „2*FTT + 1“, mit FTT = Number Of Failures To Tolerate (siehe Abbildung 7)
Mit RAID-5/6 werden nur maximal zwei tolerierbare Fehler im Cluster unterstützt, wofür ein Host (bzw. eine Fehlerdomäne) mehr notwendig ist als in einer Konfiguration mit RAID-0 („2*FTT + 2“). Für FTT=1 werden die Daten auf drei Datenkomponenten verteilt und eine zusätzliche Parity-Komponente erzeugt (RAID-5: 3 + 1), für FTT=2 werden die Daten auf vier Datenkomponenten verteilt und zusätzliche zwei Parity-Komponenten erzeugt (RAID-6: 4 + 2).
RAID-1 (mirroring) ist klassischerweise die einfachste Redundanzmethode und wird insbesondere für Umgebungen empfohlen, wo hohe I/O-Werte erreicht werden sollen. Der Vorteil von RAID-5/6 liegt im geringeren Verbrauch von physischem Speicherplatz. RAID-6 benötigt für FTT=2 nur das 1,5-fache der originalen Datenmenge, während RAID-1 hierfür den dreifachen Speicherplatz verbraucht und damit natürlich deutlich teurer ist (Abbildung 6 fasst die Anforderungen an den Speicherplatz zusammen).
Die Nachteile des Erasure-Coding-Verfahrens liegen im höheren Overhead bei Schreiboperationen. Zum einen werden nämlich CPU-Ressourcen zur Berechnung der Parity-Informationen verbraucht und zum anderen entsteht eine höhere I/O-Last, da zur Parity-Berechnung Datenblöcke aller Datenlaufwerke gelesen werden müssen. VMware versucht diesen Overhead dadurch auszugleichen, dass RAID-5/6 nur in All-Flash-Konfigurationen zugelassen ist.

Abbildung 6: Speicherplatzanforderungen
Beide Parameter können via Storage Policy sowohl auf virtuelle Maschinen als auch auf individuelle VMDK-Container angewendet werden. Falls einer der Hosts, die Komponenten eines Objekts halten, (oder mehrere, falls konfiguriert) offline geht, sorgen die Verfahren dafür, dass alle Daten weiterhin verfügbar sind. Fällt ein Host oder eine Speicherkomponente (Festplatte, Flash-Laufwerk, Storage-Controller) dauerhaft aus, erstellt vSAN im Hintergrund die ausgefallen Komponenten auf einem weiteren Host automatisch neu, um den ursprünglichen Redundanzgrad wieder zu erlangen.
Die minimale Anzahl Hosts in einem vSAN-Cluster ist also drei. In einem solchen Szenario wird lediglich Mirroring (RAID-1) mit FTT=1 unterstützt. Die Zahl Drei rührt daher, dass jedem Spiegel (aus zwei Komponenten) eine dritte, sogenannte „Witness“-Komponente hinzugefügt, um Split-Brain-Situationen zu verhindern. Seit Version 6.1 gibt es auch einen sogenannten „Witness Host“, der diese Rolle in einer Konfiguration mit nur zwei echten vSAN-Hosts übernehmen kann. Dieser „Witness Host“ ist eine virtuelle Appliance, die eine Instanz von vSphere und vSAN ausführt und die man sich bei VMware herunterladen kann.
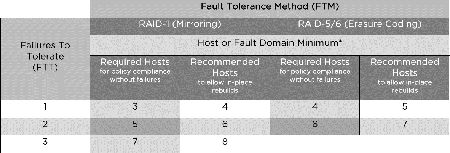
Abbildung 7: Benötigte und empfohlene Hostanzahl
vSAN unterstützt darüber hinaus die Definition von Fehlerdomänen und einer sogenannten Stretched-Cluster-Konfiguration.
„Fehlerdomänen“ erweitern einfach das Default-Konzept, wo zur Fehlertoleranz Daten redundant auf unterschiedlichen Hosts gespeichert werden, sodass Hosts neu gestartet, ausgeschaltet und sogar ausfallen können, ohne dass dies die Verfügbarkeit der Daten beeinträchtigt. Per Default ist also jeder Host eine eigene Fehlerdomäne.
Mit der Einführung von Fehlerdomänen können jetzt mehrere vSAN-Hosts (zum Beispiel alle Hosts im selben Rack) zu einer Fehlerdomäne zusammengefasst werden, sodass jetzt sogar ganze Gruppen von Hosts gleichzeitig ausfallen können, ohne dass dies die Verfügbarkeit der Daten beeinträchtigt.
Im Sinne der oben diskutierten Fehlertoleranzverfahren ist der Totalausfall aller Hosts einer Fehlerdomäne nur ein Fehler. Natürlich müssen aber die Mindestanforderungen aus Abbildung 7 jetzt auf die definierten Fehlerdomänen (z. B. Racks) übertragen werden! In einem Rechenzentrum mit nur zwei Racks führt das dazu, dass ein drittes Rack zumindest für den Witness Host benötigt wird.
Mit „Stretched Cluster“ erweitert VMware dieses Konzept erneut um eine weitere Stufe. Statt, wie gerade beschrieben, den Ausfall von Racks abzusichern, soll mit Stretched Cluster der Ausfall eines ganzen Rechenzentrums abgefangen werden. Damit wird vSAN auch in Desaster-Recovery-Szenarien möglich.
„Stretched Cluster“ führt hierzu im Wesentlichen eine weitere Redundanzebene ein und sorgt dafür, dass alle Daten aus Rechenzentrum A gespiegelt auch in Rechenzentrum B vorliegen – und zwar unabhängig vom lokalen Redundanzverfahren, das weiterhin die Daten innerhalb der Rechenzentren schützt. „Stretched Cluster“ stellt eine Active-Active-Umgebung zur Verfügung. Das heißt, jeder physische Schreibvorgang in Rechenzentrum A führt zu einem entsprechenden Schreibvorgang auf dem Spiegel in Rechenzentrum B und umgekehrt.
Für das Netzwerk empfiehlt VMware daher eine maximale Round Trip Time (RTT) von 5 msec, was grob einer maximalen Entfernung von 500 km zwischen beiden Rechenzentren bedeutet. Die benötigte Bandbreite hängt natürlich im Wesentlichen von der Anzahl und dem Umfang aller Schreibvorgänge zusammen, VMware empfiehlt pro Schreib-I/O mit 4 kB zu kalkulieren und 40 % für vSAN-Overhead und zusätzlich 25 % für Rebuilds einzubeziehen. Für 100.000 I/Os und einem Lese-Schreib-Verhältnis von 70:30 kommt man so auf
30.000 IO/sec * 4 kB/IO * 1,4 * 1,25 = 210 MB/sec = 1,68 Gb/sec
Die Anbindung an die Witness-Site ist dagegen nicht besonders kritisch: 200 msec RTT und relativ geringe Bandbreite.
Wie bei einer lokalen Zwei-Node-Konfiguration (und vergleichbaren Desaster-Recovery-Lösungen anderer Storage-Hersteller) wird auch bei Stretched Cluster ein remote Witness-Host an einer dritten Lokation benötigt, um Split-Brain-Situationen aus dem Weg zu gehen.
Im Detail führt VMware in Version 6.6 für Stretched Cluster ein paar neue Mechanismen und Parameter ein:
- Der alte Parameter „Failures To Tolerate“ heißt jetzt „Primary Failures To Tolerate“.
Ohne Stretched Cluster hat er dieselbe Bedeutung wie vorher. Mit Stretched Cluster kann er nur die Werte 0 oder 1 annehmen. 1 bedeutet, die Ressource wird über beide Rechenzentren gespiegelt, 0 bedeutet, die Ressource befindet sich nur lokal auf einer der beiden Seiten.
Der neue Parameter „Affinity“ legt in diesem Fall fest, auf welcher der beiden Seite die Ressource platziert werden soll.
- Es gibt einen neuen Parameter „Secondary Failures To Tolerate“, der in einer Stretched-Cluster-Umgebung die Rolle des alten Parameters „Failures To Tolerate“ übernimmt und regelt, wie die Ressource RZ-lokal geschützt wird.
- Ein neuer Standardmechanismus regelt, dass lesende Zugriff lokal und nicht über die WAN-Strecke erfolgen. Ohne Stretched Cluster werden lesende Zugriff im vSAN nämlich über alle verfügbaren Spiegel gleichmäßig verteilt.
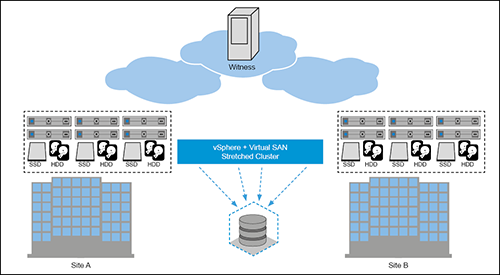
Abbildung 8: vSAN Stretched Cluster
Cache-Nutzung
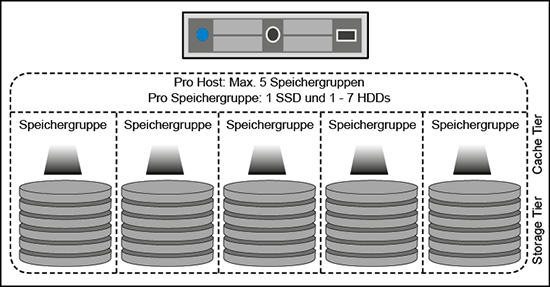
In gemischten (hybriden) Konfigurationen bestimmt die Zahl der SSDs pro Server die Zahl der Speichergruppen, alle Magnetplatten werden hierbei dem Storage Tier zugeordnet und auf die Speichergruppen verteilt. Die Cache-SSD jeder Speichergruppe wird hierbei standardmäßig zu 70 % als Lese-Cache und zu 30 % als Schreib-Puffer genutzt.
In einer All-Flash-Konfiguration wird das Cache-Laufwerk dagegen nur als Schreib-Puffer genutzt, eine Lese-Cache wird als unnötig angesehen. VMware empfiehlt in einer All-Flash-Konfiguration jedoch zwei unterschiedliche Typen von Flash-Laufwerken einzusetzen: Schnelle Laufwerke mit einer höheren Lebensdauer (wegen der vielen Schreibzugriffe) wie beispielsweise hochwertige NVMe-Karten (Non-Volatile Memory Express) als Cache-Laufwerke und Standard-SSDs mit einer höheren Kapazität zum günstigeren Preis als Datenspeicher.
In einer hybriden Konfiguration erfolgen lesende Zugriffe also zunächst immer über die Cache-Laufwerke, erst wenn der gesuchte Datenblock dort nicht gefunden wird („cache miss“), wird er von der zugehörenden Festplatte gelesen. Da vSAN lesende Zugriffe gleichmäßig über alle (lokalen) Spiegel verteilt und um trotzdem die Effektivität dieses Caches nicht zu gefährden, wird pro Datenblock eine feste Zuordnung zu einem zuständigen Spiegel gehalten. Das heißt, ein bestimmter Datenblock wird immer von derselben Festplatte beziehungsweise vom selben Cache-Laufwerk gelesen, gleichzeitig werden aber die anderen Datenblöcke gleichmäßig über die Caches der anderen Spiegel verteilt.
Der Schreib-Puffer der Cache-Laufwerke fungiert dagegen als echter Puffer für alle Schreibzugriffe. Da hierbei selbstverständlich die Verfügbarkeitsanforderungen der betreffenden Anwendung oder virtuellen Maschine nicht verletzt werden dürfen, erfolgen Schreibzugriffe immer gleichzeitig auf alle Caches aller betroffenen Spiegel im Cluster.
In hybriden Konfigurationen wird dieser Schreib-Puffer auf einer regelmäßigen Basis auf die Festplatten geschrieben, wobei aus Performance-Gründen zusammenhängende Blöcke bevorzugt werden.
Bei All-Flash-Konfigurationen steht dagegen die gesamte Cache-Kapazität als Schreib-Puffer zur Verfügung, daher setzt VMware hier auf einen etwas anderen Algorithmus: Die Datenblöcke bleiben solange im Cache wie sie geändert werden („hot blocks“). Erst wenn über einen längeren Zeitraum keine Updates mehr erfolgen („cold blocks“), werden die Blöcke in den eigentlichen Datenspeicher geschrieben und aus dem Cache gelöscht. Dieses Verhalten reduziert unter anderem die Schreibzugriffe auf die Daten-SSDs und verlängert damit deren Lebensdauer.
Damit auch dieser Schreib-Puffer effektiv genutzt wird, empfiehlt VMware eine Cache-Größe, sodass alle regelmäßig veränderte Blöcke, mindestens aber 10 % der effektiv genutzten Daten im Cache gehalten werden können. Dass dies nur ein Daumenwert ist und von Anwendung zu Anwendung deutlich variieren kann, liegt auf der Hand.
Skalierbarkeit
Die Architektur von vSAN ermöglicht flexible, vielfältige Erweiterungsmöglichkeiten sowohl in die Breite als auch in die Höhe:
- Scale Up durch das Hinzufügen weiterer Kapazitäten (Laufwerke) zum Storage Tier einzelner oder aller Hosts
- Scale Up durch das Hinzufügen weiterer Speichergruppen (sowohl Speicher- als auch Cache-Laufwerke) zu vorhandenen Hosts
- Scale Out durch das Hinzufügen weiterer Hosts mit eigener Speicherkapazität zum vSAN-Cluster
VMware empfiehlt klar ein Scale Out durch neue Hosts, da dies die einfachere und risikoärmere Methode zur Erweiterung eines vSAN-Clusters ist. Das Hinzufügen neuer Hosts erfolgt ohne Unterbrechung des laufenden Betriebs, die neuen Speicherkapazitäten werden in den vSAN-Pool integriert und transparent im Hintergrund mit Daten gefüllt.
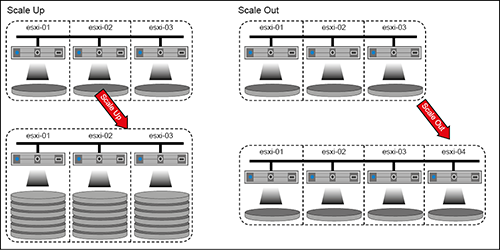
Abbildung 9: Skalierbarkeit von vSAN
Ein Scale Up mit beispielsweise größeren Festplatten oder einfach nur mehr Festplatten auf der Kapazitätsseite verändert das Verhältnis Speicherkapazität zu Cachegröße und dies kann Auswirkungen auf die Zugriffszeiten und damit auf die Performance der Anwendungen haben.
Etwas problemfreier ist das Hinzufügen zusätzlich Speichergruppen inklusive dazugehörendem Cache-Laufwerk, hier spielt nur die Leistungsfähigkeit des betroffenen Controllers eine Rolle.
Eine andere Möglichkeit zu Skalieren ist, die zusätzlichen Kapazitätserweiterungen von Anfang an vorzusehen und die Hosts direkt mit genügend großen Cache-Laufwerken aufzubauen und so bei Erweiterungen Performanceprobleme durch zu kleinen Cache zu vermeinen („Design for growth“).
Obwohl es aus Sicht der Architektur von vSAN prinzipiell egal ist, wie die jeweiligen Hosts oder die einzelnen Speichergruppen aufgebaut sind und man daher durchaus auch nur einzelne Hosts aufrüsten könnte, spricht vieles dafür, alle Hosts gleichartig auszustatten und zu konfigurieren. Ansonsten kann das einfache Verschieben einer Speicherkomponente oder deren Spiegel auf eine andere Speichergruppe dazu führen, dass sich die Anwendung plötzlich anders verhält.
Last but not least erfordert eine Scale-Up-Aufrüstung selbstverständlich immer, dass noch genügend freie Slots für neue Laufwerke vorhanden sind. Schon aus diesem Grund wird in vielen Fällen ein simples Scale Out durch weitere Hosts leicht umzusetzen sein.
Fazit
VMware liefert mit vSAN eine Speichertechnologie, die die traditionellen Hersteller massiv unter Druck setzen wird. Die Hardware besteht im Wesentlichen aus Standardservern und Standard-Speicherlaufwerken, die Konfiguration des Speicher-Pools erfolgt weitgehend automatisch und die Administration ist eng mit der Servervirtualisierung und der Administration von virtueller Maschinen verbunden.
Selbstverständlich gilt es wie bei klassischen vSphere-Realisierungen den VMware Compatibility Guide zu beachten. Insbesondere bei All-Flash-Konfigurationen haben die Cache-Laufwerke aufgrund der hohen Schreiblast besondere Anforderungen bezüglich ihrer Lebensdauer. Hier zu sparen bedeutet am falschen Ende zu sparen.
Die Anforderungen an das Netzwerk hält VMware traditionell gering. Dass die Anbindung an das vSAN-Netzwerk redundant ausgelegt werden soll, versteht sich von selbst, und auch die Forderung nach 10-Gb-Schnittstellen in einer All-Flash-Umgebung kann man heutzutage für die Anbindung von zentralem Speicher als moderat bezeichnen. Jumbo-Frames können genutzt werden, von einer expliziten Einführung nur für vSAN rät VMware ab, der Nutzen sei zu gering.
Die Notwendigkeit, Multicast im vSAN-Netz zu unterstützen, besteht übrigens seit der Version 6.6 nicht mehr.
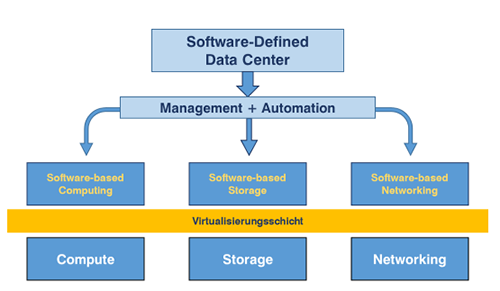
VMware verfolgt mit vSAN konsequent die Idee des Software-defined Data Center und vervollständigt damit den Baustein „Software-defined Storage“:
- Die Integration in das vCenter Management und das Verankern von Storage Policies (zur Steuerung von Verfügbarkeit und Performance) direkt an der virtuellen Maschine ermöglichen das vollständige automatische Ausrollen von VMs inklusive deren Speicher und Anforderungen daran.
- Die weitgehend automatische Konfiguration des Speicherpools ermöglicht einfache und schnelle Scale-Out-Erweiterungen und die transparente Integration unterbrechungsfrei im laufenden Betrieb.
Damit können Kunden zunächst einmal mit einer relativ kleinen Umgebung starten und sukzessive weitere Hosts und Speicherkapazität hinzufügen und genauso im Laufe der Zeit die bestehende Speicherinfrastruktur durch modernere, leistungsfähigere Hosts ersetzen.
Dies ist deutlich effektiver und eben auch kostengünstiger als die Anschaffung großer monolithischer Speichersysteme und diese dann nach einigen Jahren komplett auszutauschen.